PostgreSQL向量检索之pgvector实战入门指南
作者:袖梨
2026-06-08
一. 什么是 pgvector?
pgvector 是 PostgreSQL 的开源扩展,用于在数据库中存储和处理向量数据,特别是高维嵌入向量(embedding)。
功能与特点
- 向量存储:可将向量数据直接存入表中。
- 距离计算:支持 L2(欧氏距离)、Inner Product(内积)、Cosine(余弦相似度)等。
- 最近邻搜索:支持精确搜索和近似搜索(IVFFlat / HNSW)。
- 兼容 SQL:可以直接与表中的其他列一起做查询、过滤和排序。
- 可扩展性:适合中小规模向量存储,也能应对大数据量场景。
二. 为什么选择 PostgreSQL + pgvector?
- 数据整合:向量与原始数据存放在同一数据库,无需单独部署向量数据库。
- 事务和安全:继承 PostgreSQL 的事务、权限控制、备份与复制机制。
- 易于扩展:可以直接使用 SQL 做 JOIN、过滤条件,实现混合检索。
- 降低维护成本:只需要维护一个数据库系统,减少运维复杂度。
- 可视化和监控:可以使用 PostgreSQL 现有工具进行监控和分析。
三. 安装与启用
- 确保 PostgreSQL 支持扩展(通常 PostgreSQL 13+)
- 安装 pgvector
启用扩展:
CREATE EXTENSION IF NOT EXISTS vector;
验证安装:
SELECT * FROM pg_extension WHERE extname='vector';
成功后即可在表中创建向量列。

四. 基本数据结构
- 向量列类型:
vector或vector(n),其中n是向量维度。 - 示例表结构:
CREATE TABLE documents ( id BIGSERIAL PRIMARY KEY, embedding VECTOR(3) -- 假设嵌入向量是 3 维);
小贴士:向量列的维度必须固定,查询和索引时保持一致。
五. 基本操作
5.1 插入向量
INSERT INTO documents (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'),('[4,0,5]');5.2 查询向量最近邻
-- 使用 L2 距离SELECT id,embedding <-> '[1,2,3]' as score,embedding FROM documents ORDER BY embedding <-> '[1,2,3]' LIMIT 5;
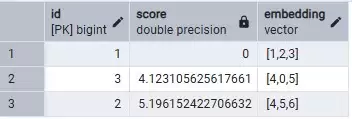
根据score的得分,就能查询出相近的向量,值越小代表越相似,算法如下
公式
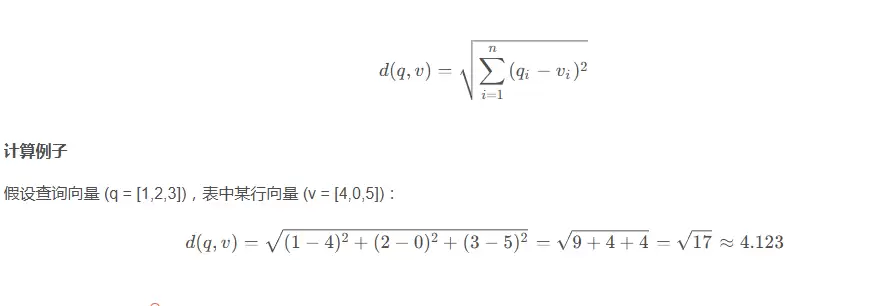
5.3 常用距离运算符
| 操作符 | 相似度度量 | 说明 | 推荐场景 | 值越小代表 |
|---|---|---|---|---|
<-> | 欧氏距离 (L2 Distance) | 计算两个向量之间的几何距离 | 图像、音频、地理数据检索 | 越相似 |
<#> | 负内积 (- Inner Product) | 取负号后的内积,用于最大内积搜索 | 推荐系统、模型打分 | 越相似 |
<=> | 余弦距离 (Cosine Distance) | 1 - 余弦相似度,对向量长度不敏感 | 文本语义检索、跨语言向量匹配 | 越相似 |
后面会出一篇关于这些运算符计算使用的文章
5.4 其他操作
# 向现有表中添加向量列ALTER TABLE items ADD COLUMN embedding vector(3);# 更新向量UPDATE items SET embedding = '[1,2,3]' WHERE id = 1;# 删除向量UPDATE items SET embedding = '[1,2,3]' WHERE id = 1;
六. Python 示例
使用 pgvector-python 或 psycopg2 处理向量:
import numpy as npimport psycopg2from pgvector.psycopg2 import register_vector# 连接数据库conn = psycopg2.connect(host='192.168.1.101', dbname='test-agent', user='postgres', password='123456', port=5433)register_vector(conn) # 注册 vector 类型cur = conn.cursor()# 插入示例向量embedding = np.random.rand(3).astype('float32')print(embedding)cur.execute( "INSERT INTO documents (embedding) VALUES (%s)", (embedding,) # 注意这里的逗号,确保是元组格式)conn.commit()# 查询最近邻query_embedding = np.random.rand(3).astype('float32')print(query_embedding)cur.execute( "SELECT id, embedding,embedding <-> %s as score FROM documents ORDER BY embedding <-> %s LIMIT 5", (query_embedding, query_embedding,))rows = cur.fetchall()for r in rows: print(r)cur.close()conn.close()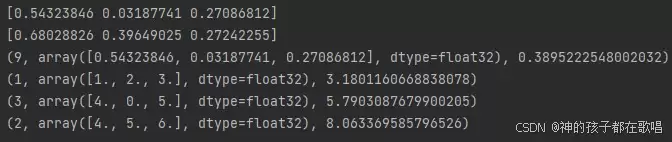
七. 小结
- pgvector 是 PostgreSQL 的向量扩展,支持高维嵌入向量存储与检索。
- 提供精确与近似最近邻查询,并可与 SQL 完美结合。
- 基础操作包括创建表、插入向量、查询最近邻以及选择合适的距离运算符。