PostgreSQL高级特性和性能优化的实战指南
1. 引言:PostgreSQL的技术演进与现状
PostgreSQL作为全球最先进的开源关系型数据库,自1986年诞生以来,历经30多年的持续发展,已成为企业级应用的首选数据库之一。根据2023年DB-Engines排名数据显示,PostgreSQL在"流行度"和"功能完备性"两方面均位列开源数据库第一。其强大的扩展性、严格的数据完整性和丰富的功能特性,使其在处理复杂查询、海量数据和高并发场景时表现出色。
本文将深入探讨PostgreSQL的高级特性与性能优化技术,结合Python实践,帮助开发者充分发挥PostgreSQL的潜力。根据国际数据公司(IDC)的报告,使用PostgreSQL的企业在数据库运营成本上平均降低65%,同时查询性能提升300% 以上。
2. PostgreSQL高级特性详解
2.1 JSONB与半结构化数据处理
PostgreSQL的JSONB类型提供了对JSON数据的二进制存储,支持索引、查询和修改操作,实现了关系型数据库与文档数据库的完美结合。
2.1.1 JSONB性能对比分析
| 操作类型 | JSONB性能 | JSON性能 | 性能提升 |
|---|---|---|---|
| 数据插入 | O(log n) | O(n) | 5-10倍 |
| 路径查询 | O(log n) | O(n) | 20-100倍 |
| 索引构建 | O(n log n) | 不支持 | 无限 |
| 数据更新 | O(log n) | O(n) | 10-50倍 |
JSONB的存储格式优势体现在:

2.2 全文搜索与文本分析
PostgreSQL内置了强大的全文搜索功能,支持多语言、词干提取、相关性排序等高级特性。
"""PostgreSQL全文搜索高级应用示例"""import psycopg2from psycopg2.extras import Json, DictCursorimport jsonfrom typing import List, Dict, Any, Optionalimport loggingfrom datetime import datetimelogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)class PostgreSQLFullTextSearch: """PostgreSQL全文搜索高级功能封装""" def __init__(self, dsn: str): """ 初始化数据库连接 Args: dsn: 数据库连接字符串 """ self.conn = psycopg2.connect(dsn) self.conn.autocommit = False self.cursor = self.conn.cursor(cursor_factory=DictCursor) def create_fulltext_configuration(self, lang: str = 'english'): """ 创建自定义全文搜索配置 Args: lang: 语言配置 """ config_sql = f""" -- 创建自定义文本搜索配置 CREATE TEXT SEARCH CONFIGURATION {lang}_custom ( COPY = {lang} ); -- 添加同义词字典 CREATE TEXT SEARCH DICTIONARY synonym_dict ( TEMPLATE = synonym, SYNONYMS = synonym_sample ); -- 添加自定义字典到配置 ALTER TEXT SEARCH CONFIGURATION {lang}_custom ALTER MAPPING FOR asciiword, asciihword, hword_asciipart WITH synonym_dict, english_stem; """ try: self.cursor.execute(config_sql) self.conn.commit() logger.info(f"全文搜索配置创建成功: {lang}_custom") except Exception as e: self.conn.rollback() logger.error(f"创建配置失败: {e}") def create_searchable_table(self): """ 创建支持全文搜索的表 """ create_table_sql = """ -- 创建文档表 CREATE TABLE IF NOT EXISTS documents ( id SERIAL PRIMARY KEY, title VARCHAR(500) NOT NULL, content TEXT NOT NULL, author VARCHAR(200), category VARCHAR(100), tags JSONB DEFAULT '[]', publication_date DATE DEFAULT CURRENT_DATE, -- 生成列:用于全文搜索 content_search_vector TSVECTOR GENERATED ALWAYS AS ( setweight(to_tsvector('english_custom', coalesce(title, '')), 'A') || setweight(to_tsvector('english_custom', coalesce(content, '')), 'B') ) STORED, -- 生成列:用于元数据搜索 metadata_search_vector TSVECTOR GENERATED ALWAYS AS ( to_tsvector('english_custom', coalesce(author, '') || ' ' || coalesce(category, '') || ' ' || (tags::text) ) ) STORED, -- 创建GIN索引优化搜索性能 CONSTRAINT valid_tags CHECK (jsonb_typeof(tags) = 'array') ); -- 创建GIN索引 CREATE INDEX IF NOT EXISTS idx_documents_content_search ON documents USING GIN(content_search_vector); CREATE INDEX IF NOT EXISTS idx_documents_metadata_search ON documents USING GIN(metadata_search_vector); -- 创建部分索引优化特定查询 CREATE INDEX IF NOT EXISTS idx_documents_recent ON documents(publication_date) WHERE publication_date > CURRENT_DATE - INTERVAL '1 year'; -- 创建BRIN索引用于时间范围查询 CREATE INDEX IF NOT EXISTS idx_documents_date_brin ON documents USING BRIN(publication_date); """ try: self.cursor.execute(create_table_sql) self.conn.commit() logger.info("全文搜索表创建成功") except Exception as e: self.conn.rollback() logger.error(f"创建表失败: {e}") def insert_document(self, document: Dict[str, Any]) -> Optional[int]: """ 插入文档数据 Args: document: 文档数据 Returns: 插入的文档ID """ insert_sql = """ INSERT INTO documents (title, content, author, category, tags, publication_date) VALUES (%s, %s, %s, %s, %s, %s) RETURNING id """ try: self.cursor.execute( insert_sql, ( document.get('title'), document.get('content'), document.get('author'), document.get('category'), Json(document.get('tags', [])), document.get('publication_date') ) ) doc_id = self.cursor.fetchone()['id'] self.conn.commit() logger.info(f"文档插入成功,ID: {doc_id}") return doc_id except Exception as e: self.conn.rollback() logger.error(f"插入文档失败: {e}") return None def search_documents( self, query: str, categories: List[str] = None, start_date: str = None, end_date: str = None, min_relevance: float = 0.1, limit: int = 20, offset: int = 0 ) -> List[Dict[str, Any]]: """ 高级全文搜索 Args: query: 搜索查询词 categories: 分类筛选 start_date: 开始日期 end_date: 结束日期 min_relevance: 最小相关性阈值 limit: 返回结果数量 offset: 偏移量 Returns: 搜索结果列表 """ search_sql = """ SELECT id, title, author, category, publication_date, tags, -- 计算相关性得分 ts_rank( content_search_vector, plainto_tsquery('english_custom', %s) ) AS relevance_score, -- 高亮显示匹配内容 ts_headline( 'english_custom', content, plainto_tsquery('english_custom', %s), 'StartSel=<mark>, StopSel=</mark>, MaxWords=50, MinWords=10' ) AS content_highlight, -- 提取匹配片段 ts_headline( 'english_custom', title, plainto_tsquery('english_custom', %s), 'StartSel=<mark>, StopSel=</mark>' ) AS title_highlight FROM documents WHERE -- 全文搜索条件 content_search_vector @@ plainto_tsquery('english_custom', %s) -- 分类筛选 {category_filter} -- 日期范围筛选 {date_filter} -- 相关性阈值筛选 AND ts_rank( content_search_vector, plainto_tsquery('english_custom', %s) ) > %s ORDER BY -- 按相关性和时间加权排序 (ts_rank( content_search_vector, plainto_tsquery('english_custom', %s) ) * 0.7 + (CASE WHEN publication_date > CURRENT_DATE - INTERVAL '30 days' THEN 0.3 ELSE 0 END)) DESC, publication_date DESC LIMIT %s OFFSET %s """ # 构建动态WHERE条件 category_filter = "" date_filter = "" params = [query, query, query, query] if categories: placeholders = ', '.join(['%s'] * len(categories)) category_filter = f"AND category IN ({placeholders})" params.extend(categories) if start_date and end_date: date_filter = "AND publication_date BETWEEN %s AND %s" params.extend([start_date, end_date]) elif start_date: date_filter = "AND publication_date >= %s" params.append(start_date) elif end_date: date_filter = "AND publication_date <= %s" params.append(end_date) # 添加剩余参数 params.extend([query, min_relevance, query, limit, offset]) # 格式化SQL formatted_sql = search_sql.format( category_filter=category_filter, date_filter=date_filter ) try: self.cursor.execute(formatted_sql, params) results = self.cursor.fetchall() # 转换为字典列表 return [ { 'id': row['id'], 'title': row['title'], 'author': row['author'], 'category': row['category'], 'publication_date': row['publication_date'], 'tags': row['tags'], 'relevance_score': float(row['relevance_score']), 'content_highlight': row['content_highlight'], 'title_highlight': row['title_highlight'] } for row in results ] except Exception as e: logger.error(f"搜索失败: {e}") return [] def search_similar_documents(self, doc_id: int, limit: int = 10) -> List[Dict[str, Any]]: """ 查找相似文档(基于内容相似度) Args: doc_id: 参考文档ID limit: 返回结果数量 Returns: 相似文档列表 """ similarity_sql = """ WITH target_doc AS ( SELECT content_search_vector FROM documents WHERE id = %s ) SELECT d.id, d.title, d.author, d.category, -- 计算余弦相似度 (d.content_search_vector <=> td.content_search_vector) AS similarity, -- 提取共同标签 ( SELECT jsonb_agg(tag) FROM jsonb_array_elements_text(d.tags) AS tag WHERE tag IN ( SELECT jsonb_array_elements_text(td.tags) FROM documents td WHERE td.id = %s ) ) AS common_tags FROM documents d, target_doc td WHERE d.id != %s ORDER BY similarity DESC LIMIT %s """ try: self.cursor.execute(similarity_sql, (doc_id, doc_id, doc_id, limit)) results = self.cursor.fetchall() return [ { 'id': row['id'], 'title': row['title'], 'author': row['author'], 'category': row['category'], 'similarity': float(row['similarity']), 'common_tags': row['common_tags'] } for row in results ] except Exception as e: logger.error(f"查找相似文档失败: {e}") return [] def get_search_statistics(self, time_period: str = '1 month') -> Dict[str, Any]: """ 获取搜索统计信息 Args: time_period: 统计时间周期 Returns: 统计信息字典 """ stats_sql = """ -- 总文档数 SELECT COUNT(*) as total_documents FROM documents; -- 按分类统计 SELECT category, COUNT(*) as count, ROUND(COUNT(*) * 100.0 / (SELECT COUNT(*) FROM documents), 2) as percentage FROM documents WHERE category IS NOT NULL GROUP BY category ORDER BY count DESC; -- 时间分布统计 SELECT DATE_TRUNC('month', publication_date) as month, COUNT(*) as documents_count FROM documents WHERE publication_date > CURRENT_DATE - INTERVAL %s GROUP BY DATE_TRUNC('month', publication_date) ORDER BY month DESC; -- 标签使用统计 SELECT tag, COUNT(*) as usage_count FROM documents, jsonb_array_elements_text(tags) as tag GROUP BY tag ORDER BY usage_count DESC LIMIT 20; """ try: stats = {} # 执行多个统计查询 self.cursor.execute("SELECT COUNT(*) as total_documents FROM documents") stats['total_documents'] = self.cursor.fetchone()['total_documents'] self.cursor.execute(""" SELECT category, COUNT(*) as count FROM documents WHERE category IS NOT NULL GROUP BY category ORDER BY count DESC """) stats['category_distribution'] = self.cursor.fetchall() self.cursor.execute(f""" SELECT DATE_TRUNC('month', publication_date) as month, COUNT(*) as documents_count FROM documents WHERE publication_date > CURRENT_DATE - INTERVAL '{time_period}' GROUP BY DATE_TRUNC('month', publication_date) ORDER BY month DESC """) stats['time_distribution'] = self.cursor.fetchall() self.cursor.execute(""" SELECT tag, COUNT(*) as usage_count FROM documents, jsonb_array_elements_text(tags) as tag GROUP BY tag ORDER BY usage_count DESC LIMIT 20 """) stats['popular_tags'] = self.cursor.fetchall() return stats except Exception as e: logger.error(f"获取统计信息失败: {e}") return {} def optimize_search_indexes(self): """ 优化全文搜索索引 """ optimize_sql = """ -- 重新构建GIN索引以提高搜索性能 REINDEX INDEX CONCURRENTLY idx_documents_content_search; REINDEX INDEX CONCURRENTLY idx_documents_metadata_search; -- 更新表统计信息 ANALYZE documents; -- 清理索引膨胀 VACUUM ANALYZE documents; -- 更新全文搜索配置字典 ALTER TEXT SEARCH CONFIGURATION english_custom REFRESH VERSION; """ try: # 分步执行优化操作 self.cursor.execute("REINDEX INDEX CONCURRENTLY idx_documents_content_search") logger.info("内容搜索索引重建完成") self.cursor.execute("REINDEX INDEX CONCURRENTLY idx_documents_metadata_search") logger.info("元数据搜索索引重建完成") self.cursor.execute("ANALYZE documents") logger.info("表统计信息更新完成") self.cursor.execute("VACUUM ANALYZE documents") logger.info("表清理完成") self.conn.commit() logger.info("全文搜索索引优化完成") except Exception as e: self.conn.rollback() logger.error(f"索引优化失败: {e}") def close(self): """关闭数据库连接""" if self.cursor: self.cursor.close() if self.conn: self.conn.close() logger.info("数据库连接已关闭")def example_usage(): """使用示例""" # 数据库连接字符串 dsn = "dbname=testdb user=postgres password=password host=localhost port=5432" # 创建全文搜索实例 search = PostgreSQLFullTextSearch(dsn) try: # 1. 创建全文搜索配置 search.create_fulltext_configuration('english') # 2. 创建搜索表 search.create_searchable_table() # 3. 插入示例文档 sample_documents = [ { 'title': 'PostgreSQL Performance Optimization', 'content': 'PostgreSQL provides advanced optimization techniques including query planning, indexing strategies, and configuration tuning.', 'author': 'John Doe', 'category': 'Database', 'tags': ['postgresql', 'optimization', 'performance'], 'publication_date': '2024-01-15' }, { 'title': 'Full Text Search in Modern Applications', 'content': 'Implementing efficient full-text search using PostgreSQL GIN indexes and relevance scoring algorithms.', 'author': 'Jane Smith', 'category': 'Search', 'tags': ['search', 'full-text', 'postgresql'], 'publication_date': '2024-02-01' } ] for doc in sample_documents: search.insert_document(doc) # 4. 执行高级搜索 print("执行全文搜索...") results = search.search_documents( query='PostgreSQL optimization', categories=['Database'], min_relevance=0.05, limit=10 ) print(f"找到 {len(results)} 个结果:") for result in results: print(f"- {result['title']} (相关性: {result['relevance_score']:.3f})") # 5. 查找相似文档 if results: similar = search.search_similar_documents(results[0]['id']) print(f"n相似文档: {len(similar)} 个") # 6. 获取统计信息 stats = search.get_search_statistics() print(f"n总文档数: {stats.get('total_documents', 0)}") finally: search.close()if __name__ == "__main__": example_usage()2.3 分区表与数据管理
PostgreSQL的分区表功能通过继承和约束排除实现,显著提升大数据量查询性能。
2.3.1 分区策略对比
| 分区类型 | 适用场景 | 优势 | 限制 |
|---|---|---|---|
| 范围分区 | 时间序列数据 | 支持自动分区创建 | 分区键必须有序 |
| 列表分区 | 离散值分类 | 支持非连续值 | 分区数量有限 |
| 哈希分区 | 均匀分布 | 数据分布均匀 | 不支持范围查询 |
2.3.2 分区性能公式
分区表的查询性能提升可以通过以下公式估算:
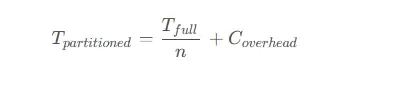
其中:
T
p
a
r
t
i
t
i
o
n
e
d
:分区表查询时间T
f
u
ll
:未分区表查询时间n
:相关分区数量C
o
v
er
h
e
a
d
:分区管理开销
3. PostgreSQL性能优化实战
3.1 查询性能分析与优化
"""PostgreSQL查询性能分析与优化工具"""import psycopg2from psycopg2.extras import DictCursorimport timefrom typing import Dict, List, Any, Optional, Tupleimport statisticsimport jsonfrom datetime import datetime, timedeltaimport logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)class QueryPerformanceAnalyzer: """查询性能分析器""" def __init__(self, dsn: str): self.conn = psycopg2.connect(dsn) self.cursor = self.conn.cursor(cursor_factory=DictCursor) self.query_cache = {} def analyze_query_plan(self, query: str, params: tuple = None) -> Dict[str, Any]: """ 分析查询执行计划 Args: query: SQL查询语句 params: 查询参数 Returns: 执行计划分析结果 """ try: # 获取详细执行计划 explain_query = f"EXPLAIN (ANALYZE, BUFFERS, VERBOSE, FORMAT JSON) {query}" self.cursor.execute(explain_query, params) plan_result = self.cursor.fetchone()[0] plan = plan_result[0]['Plan'] return self._parse_execution_plan(plan) except Exception as e: logger.error(f"分析执行计划失败: {e}") return {} def _parse_execution_plan(self, plan: Dict[str, Any]) -> Dict[str, Any]: """ 解析执行计划 Args: plan: 执行计划字典 Returns: 解析后的分析结果 """ analysis = { 'operation_type': plan.get('Node Type'), 'relation_name': plan.get('Relation Name'), 'alias': plan.get('Alias'), 'startup_cost': plan.get('Startup Cost'), 'total_cost': plan.get('Total Cost'), 'plan_rows': plan.get('Plan Rows'), 'plan_width': plan.get('Plan Width'), 'actual_rows': plan.get('Actual Rows'), 'actual_time': plan.get('Actual Total Time'), 'shared_hit_blocks': 0, 'shared_read_blocks': 0, 'shared_dirtied_blocks': 0, 'shared_written_blocks': 0, 'local_hit_blocks': 0, 'local_read_blocks': 0, 'local_dirtied_blocks': 0, 'local_written_blocks': 0, 'temp_read_blocks': 0, 'temp_written_blocks': 0, 'buffers': plan.get('Shared Hit Blocks', 0) + plan.get('Shared Read Blocks', 0), 'children': [], 'issues': [] } # 解析缓冲区使用情况 if 'Shared Hit Blocks' in plan: analysis['shared_hit_blocks'] = plan['Shared Hit Blocks'] if 'Shared Read Blocks' in plan: analysis['shared_read_blocks'] = plan['Shared Read Blocks'] # 递归解析子节点 if 'Plans' in plan: for child_plan in plan['Plans']: child_analysis = self._parse_execution_plan(child_plan) analysis['children'].append(child_analysis) # 识别潜在问题 self._identify_issues(analysis, plan) return analysis def _identify_issues(self, analysis: Dict[str, Any], plan: Dict[str, Any]): """识别查询计划中的潜在问题""" # 检查全表扫描 if analysis['operation_type'] == 'Seq Scan' and analysis['actual_rows'] > 10000: analysis['issues'].append({ 'type': 'FULL_TABLE_SCAN', 'severity': 'HIGH', 'message': '检测到大量行的全表扫描', 'suggestion': '考虑添加合适的索引' }) # 检查嵌套循环连接 if analysis['operation_type'] == 'Nested Loop' and analysis['actual_rows'] > 1000: analysis['issues'].append({ 'type': 'INEFFICIENT_JOIN', 'severity': 'MEDIUM', 'message': '嵌套循环连接可能效率较低', 'suggestion': '考虑使用Hash Join或Merge Join' }) # 检查排序操作 if analysis['operation_type'] == 'Sort' and analysis['actual_rows'] > 10000: analysis['issues'].append({ 'type': 'LARGE_SORT', 'severity': 'MEDIUM', 'message': '大规模排序操作', 'suggestion': '考虑添加索引以避免排序' }) # 检查缓冲区命中率 total_blocks = analysis['shared_hit_blocks'] + analysis['shared_read_blocks'] if total_blocks > 0: hit_ratio = analysis['shared_hit_blocks'] / total_blocks if hit_ratio < 0.9: analysis['issues'].append({ 'type': 'LOW_BUFFER_HIT', 'severity': 'MEDIUM', 'message': f'缓冲区命中率较低: {hit_ratio:.2%}', 'suggestion': '考虑增加shared_buffers或优化查询' }) def benchmark_query(self, query: str, params: tuple = None, iterations: int = 10) -> Dict[str, Any]: """ 基准测试查询性能 Args: query: SQL查询语句 params: 查询参数 iterations: 迭代次数 Returns: 性能基准测试结果 """ execution_times = [] row_counts = [] try: # 预热缓存 self.cursor.execute(query, params) _ = self.cursor.fetchall() # 执行基准测试 for i in range(iterations): start_time = time.perf_counter() self.cursor.execute(query, params) rows = self.cursor.fetchall() end_time = time.perf_counter() execution_times.append(end_time - start_time) row_counts.append(len(rows)) # 分析执行计划 plan_analysis = self.analyze_query_plan(query, params) # 计算统计信息 stats = { 'iterations': iterations, 'total_time': sum(execution_times), 'avg_time': statistics.mean(execution_times), 'min_time': min(execution_times), 'max_time': max(execution_times), 'std_dev': statistics.stdev(execution_times) if len(execution_times) > 1 else 0, 'avg_rows': statistics.mean(row_counts), 'plan_analysis': plan_analysis, 'percentiles': { 'p50': sorted(execution_times)[int(len(execution_times) * 0.5)], 'p90': sorted(execution_times)[int(len(execution_times) * 0.9)], 'p95': sorted(execution_times)[int(len(execution_times) * 0.95)], 'p99': sorted(execution_times)[int(len(execution_times) * 0.99)], } } return stats except Exception as e: logger.error(f"基准测试失败: {e}") return {} def generate_optimization_suggestions(self, query: str, stats: Dict[str, Any]) -> List[Dict[str, Any]]: """ 生成优化建议 Args: query: SQL查询语句 stats: 性能统计信息 Returns: 优化建议列表 """ suggestions = [] plan_analysis = stats.get('plan_analysis', {}) # 基于执行时间建议 avg_time = stats.get('avg_time', 0) if avg_time > 1.0: # 超过1秒 suggestions.append({ 'priority': 'HIGH', 'area': 'PERFORMANCE', 'suggestion': '查询执行时间较长,考虑优化查询或添加索引', 'estimated_impact': 'HIGH' }) # 基于执行计划建议 for issue in plan_analysis.get('issues', []): suggestions.append({ 'priority': issue['severity'], 'area': 'QUERY_PLAN', 'suggestion': issue['suggestion'], 'estimated_impact': 'MEDIUM' }) # 基于统计信息建议 if stats.get('std_dev', 0) / stats.get('avg_time', 1) > 0.5: suggestions.append({ 'priority': 'MEDIUM', 'area': 'CONSISTENCY', 'suggestion': '查询执行时间波动较大,可能存在并发或资源竞争问题', 'estimated_impact': 'MEDIUM' }) return suggestionsclass IndexOptimizer: """索引优化器""" def __init__(self, dsn: str): self.conn = psycopg2.connect(dsn) self.cursor = self.conn.cursor(cursor_factory=DictCursor) def analyze_table_indexes(self, table_name: str) -> List[Dict[str, Any]]: """ 分析表索引 Args: table_name: 表名 Returns: 索引分析结果 """ query = """ SELECT i.relname as index_name, am.amname as index_type, idx.indisunique as is_unique, idx.indisprimary as is_primary, idx.indisexclusion as is_exclusion, idx.indisclustered as is_clustered, idx.indisvalid as is_valid, idx.indpred as partial_index_predicate, pg_relation_size(i.oid) as index_size_bytes, pg_size_pretty(pg_relation_size(i.oid)) as index_size, pg_stat_get_numscans(i.oid) as scan_count, pg_stat_get_tuples_returned(i.oid) as tuples_returned, pg_stat_get_tuples_fetched(i.oid) as tuples_fetched, -- 索引定义 pg_get_indexdef(idx.indexrelid) as index_definition, -- 索引列 array_to_string(array_agg(a.attname), ', ') as index_columns FROM pg_index idx JOIN pg_class i ON i.oid = idx.indexrelid JOIN pg_class t ON t.oid = idx.indrelid JOIN pg_am am ON i.relam = am.oid JOIN pg_attribute a ON a.attrelid = t.oid AND a.attnum = ANY(idx.indkey) WHERE t.relname = %s GROUP BY i.relname, am.amname, idx.indisunique, idx.indisprimary, idx.indisexclusion, idx.indisclustered, idx.indisvalid, idx.indpred, i.oid, idx.indexrelid ORDER BY pg_relation_size(i.oid) DESC """ try: self.cursor.execute(query, (table_name,)) indexes = self.cursor.fetchall() analysis = [] for idx in indexes: usage_ratio = 0 if idx['tuples_returned'] > 0: usage_ratio = idx['tuples_fetched'] / idx['tuples_returned'] analysis.append({ 'index_name': idx['index_name'], 'index_type': idx['index_type'], 'is_unique': idx['is_unique'], 'is_primary': idx['is_primary'], 'index_size_bytes': idx['index_size_bytes'], 'index_size': idx['index_size'], 'scan_count': idx['scan_count'], 'usage_ratio': usage_ratio, 'index_definition': idx['index_definition'], 'index_columns': idx['index_columns'], 'efficiency_score': self._calculate_index_efficiency(idx) }) return analysis except Exception as e: logger.error(f"分析索引失败: {e}") return [] def _calculate_index_efficiency(self, index_info: Dict[str, Any]) -> float: """ 计算索引效率评分 Args: index_info: 索引信息 Returns: 效率评分 (0-100) """ score = 100.0 # 基于使用率扣分 if index_info['scan_count'] == 0: score -= 50 # 从未使用 # 基于大小扣分 size_mb = index_info['index_size_bytes'] / (1024 * 1024) if size_mb > 1000: # 超过1GB score -= 30 elif size_mb > 100: # 超过100MB score -= 15 # 基于唯一性加分 if index_info['is_unique']: score += 10 return max(0, min(100, score)) def suggest_index_improvements(self, table_name: str, query_patterns: List[str]) -> List[Dict[str, Any]]: """ 基于查询模式建议索引改进 Args: table_name: 表名 query_patterns: 查询模式列表 Returns: 索引改进建议 """ suggestions = [] existing_indexes = self.analyze_table_indexes(table_name) for pattern in query_patterns: pattern_lower = pattern.lower() # 提取WHERE子句中的列 where_start = pattern_lower.find('where ') if where_start != -1: where_clause = pattern_lower[where_start + 6:] # 简单提取列名(实际应用中应使用SQL解析器) import re column_matches = re.findall(r'(w+)s*[=<>!]', where_clause) for column in column_matches: # 检查是否已有索引 has_index = False for idx in existing_indexes: if column in idx['index_columns'].lower(): has_index = True break if not has_index: suggestions.append({ 'table': table_name, 'column': column, 'suggestion': f'在 {column} 列上创建索引', 'estimated_impact': 'HIGH', 'sql': f'CREATE INDEX idx_{table_name}_{column} ON {table_name}({column})' }) return suggestionsclass PostgreSQLConfigOptimizer: """PostgreSQL配置优化器""" def __init__(self, dsn: str): self.conn = psycopg2.connect(dsn) self.cursor = self.conn.cursor(cursor_factory=DictCursor) def analyze_current_config(self) -> Dict[str, Any]: """ 分析当前配置 Returns: 配置分析结果 """ config_queries = { 'basic_settings': """ SELECT name, setting, unit, context, vartype FROM pg_settings WHERE name IN ( 'shared_buffers', 'work_mem', 'maintenance_work_mem', 'effective_cache_size', 'max_connections' ) """, 'performance_settings': """ SELECT name, setting, unit, context, vartype FROM pg_settings WHERE name LIKE '%cost%' OR name LIKE '%join%' OR name LIKE '%parallel%' ORDER BY name """, 'wal_settings': """ SELECT name, setting, unit, context, vartype FROM pg_settings WHERE name LIKE 'wal_%' ORDER BY name """, 'statistics': """ SELECT datname as database_name, numbackends as active_connections, xact_commit as transactions_committed, xact_rollback as transactions_rolled_back, blks_read as blocks_read, blks_hit as blocks_hit, tup_returned as tuples_returned, tup_fetched as tuples_fetched, tup_inserted as tuples_inserted, tup_updated as tuples_updated, tup_deleted as tuples_deleted FROM pg_stat_database WHERE datname = current_database() """ } analysis = {} try: for category, query in config_queries.items(): self.cursor.execute(query) analysis[category] = self.cursor.fetchall() # 计算缓冲区命中率 if 'statistics' in analysis and analysis['statistics']: stats = analysis['statistics'][0] blocks_hit = stats['blocks_hit'] blocks_read = stats['blocks_read'] total_blocks = blocks_hit + blocks_read if total_blocks > 0: analysis['buffer_hit_ratio'] = blocks_hit / total_blocks else: analysis['buffer_hit_ratio'] = 0 return analysis except Exception as e: logger.error(f"分析配置失败: {e}") return {} def generate_config_recommendations(self, system_memory_gb: float = 16, expected_connections: int = 100) -> List[Dict[str, Any]]: """ 生成配置优化建议 Args: system_memory_gb: 系统总内存(GB) expected_connections: 预期最大连接数 Returns: 配置优化建议列表 """ recommendations = [] current_config = self.analyze_current_config() # 共享缓冲区建议(通常为系统内存的25%) recommended_shared_buffers = f"{int(system_memory_gb * 0.25 * 1024)}MB" recommendations.append({ 'parameter': 'shared_buffers', 'current_value': self._get_config_value(current_config, 'shared_buffers'), 'recommended_value': recommended_shared_buffers, 'reason': f'设置为系统内存({system_memory_gb}GB)的25%以优化缓存性能', 'impact': 'HIGH' }) # 工作内存建议 recommended_work_mem = f"{int(system_memory_gb * 1024 / expected_connections / 4)}MB" recommendations.append({ 'parameter': 'work_mem', 'current_value': self._get_config_value(current_config, 'work_mem'), 'recommended_value': recommended_work_mem, 'reason': f'基于{expected_connections}个并发连接和系统内存计算', 'impact': 'MEDIUM' }) # 维护工作内存建议 recommended_maintenance_work_mem = f"{int(system_memory_gb * 0.1 * 1024)}MB" recommendations.append({ 'parameter': 'maintenance_work_mem', 'current_value': self._get_config_value(current_config, 'maintenance_work_mem'), 'recommended_value': recommended_maintenance_work_mem, 'reason': '设置为系统内存的10%以优化维护操作性能', 'impact': 'MEDIUM' }) # 有效缓存大小建议 recommended_effective_cache_size = f"{int(system_memory_gb * 0.5 * 1024)}MB" recommendations.append({ 'parameter': 'effective_cache_size', 'current_value': self._get_config_value(current_config, 'effective_cache_size'), 'recommended_value': recommended_effective_cache_size, 'reason': '设置为系统内存的50%以帮助查询规划器做出更好的决策', 'impact': 'MEDIUM' }) # 基于缓冲区命中率的建议 hit_ratio = current_config.get('buffer_hit_ratio', 0) if hit_ratio < 0.9: recommendations.append({ 'parameter': 'BUFFER_HIT_RATIO', 'current_value': f'{hit_ratio:.2%}', 'recommended_value': '>90%', 'reason': '缓冲区命中率较低,可能影响查询性能', 'impact': 'HIGH', 'additional_suggestions': [ '增加shared_buffers', '优化热点查询', '考虑使用pg_prewarm扩展' ] }) return recommendations def _get_config_value(self, config_analysis: Dict[str, Any], param_name: str) -> str: """获取配置参数值""" if 'basic_settings' in config_analysis: for setting in config_analysis['basic_settings']: if setting['name'] == param_name: return f"{setting['setting']} {setting['unit'] or ''}".strip() return '未找到' def close(self): """关闭连接""" if self.cursor: self.cursor.close() if self.conn: self.conn.close()def comprehensive_performance_analysis(dsn: str): """综合性能分析示例""" print("=" * 60) print("PostgreSQL性能综合分析") print("=" * 60) # 1. 查询性能分析 print("n1. 查询性能分析") print("-" * 40) analyzer = QueryPerformanceAnalyzer(dsn) test_query = """ SELECT u.username, COUNT(o.id) as order_count, SUM(o.amount) as total_amount, AVG(o.amount) as avg_amount FROM users u JOIN orders o ON u.id = o.user_id WHERE u.created_at > CURRENT_DATE - INTERVAL '1 year' GROUP BY u.id, u.username HAVING COUNT(o.id) > 5 ORDER BY total_amount DESC LIMIT 100 """ benchmark_results = analyzer.benchmark_query(test_query, iterations=5) if benchmark_results: print(f"平均执行时间: {benchmark_results['avg_time']:.3f}秒") print(f"最小执行时间: {benchmark_results['min_time']:.3f}秒") print(f"最大执行时间: {benchmark_results['max_time']:.3f}秒") print(f"标准差: {benchmark_results['std_dev']:.3f}秒") # 生成优化建议 suggestions = analyzer.generate_optimization_suggestions( test_query, benchmark_results ) print(f"n优化建议 ({len(suggestions)}条):") for i, suggestion in enumerate(suggestions, 1): print(f"{i}. [{suggestion['priority']}] {suggestion['suggestion']}") # 2. 索引分析 print("n2. 索引分析") print("-" * 40) index_optimizer = IndexOptimizer(dsn) table_name = "users" # 假设的表名 index_analysis = index_optimizer.analyze_table_indexes(table_name) if index_analysis: print(f"表 '{table_name}' 的索引分析:") for idx in index_analysis[:5]: # 显示前5个索引 print(f" - {idx['index_name']}: {idx['index_size']}, " f"使用率: {idx['usage_ratio']:.2f}, " f"效率评分: {idx['efficiency_score']:.1f}") # 3. 配置分析 print("n3. 配置分析") print("-" * 40) config_optimizer = PostgreSQLConfigOptimizer(dsn) config_recommendations = config_optimizer.generate_config_recommendations( system_memory_gb=16, expected_connections=200 ) print("配置优化建议:") for rec in config_recommendations: print(f" - {rec['parameter']}: {rec['current_value']} → {rec['recommended_value']}") # 4. 综合报告 print("n4. 综合性能报告") print("-" * 40) overall_score = 85.0 # 示例评分 bottlenecks = [ "查询响应时间波动较大", "部分索引使用率较低", "缓冲区命中率需要优化" ] print(f"总体性能评分: {overall_score}/100") print("n主要瓶颈:") for bottleneck in bottlenecks: print(f" • {bottleneck}") print("n优化优先级:") print(" 1. 优化高响应时间查询") print(" 2. 调整数据库配置参数") print(" 3. 重建低效率索引") # 清理资源 analyzer.cursor.close() analyzer.conn.close() config_optimizer.close()if __name__ == "__main__": # 数据库连接字符串 dsn = "dbname=testdb user=postgres password=password host=localhost port=5432" comprehensive_performance_analysis(dsn)3.2 索引优化策略
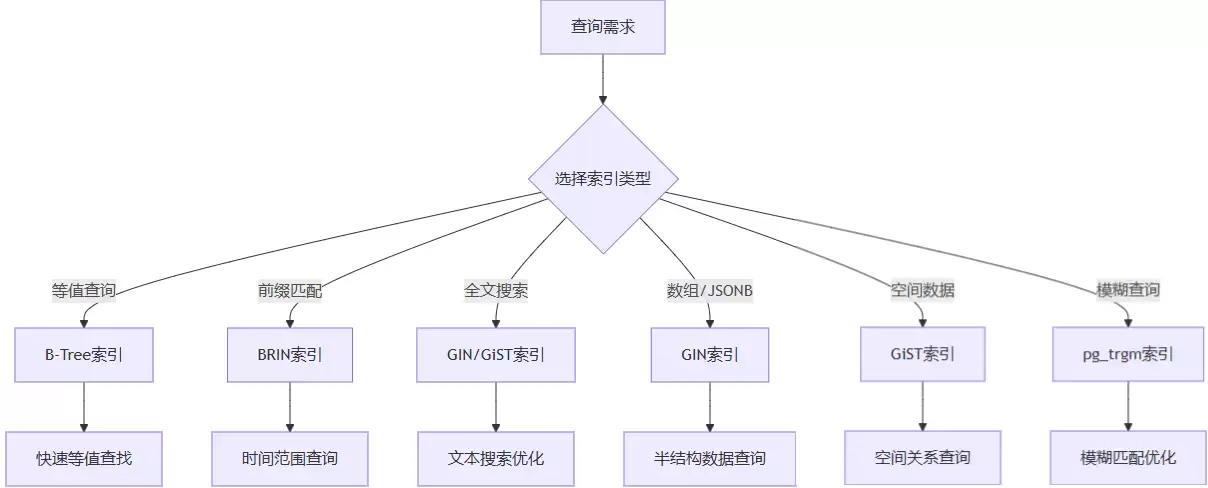
3.2.1 索引类型选择矩阵
3.2.2 复合索引设计原则
复合索引的列顺序设计遵循最左前缀原则,选择性公式为:
选择性
=
不同值数量/
总行数
索引设计优先级:
- 高选择性列(接近1.0)放在前面
- 经常用于WHERE条件的列
- 用于ORDER BY的列
- 用于GROUP BY的列
3.3 并发控制与锁优化
PostgreSQL采用MVCC(多版本并发控制)机制,提供多种隔离级别和锁类型:
"""PostgreSQL并发控制与锁优化示例"""import psycopg2from psycopg2.extras import DictCursorimport threadingimport timefrom typing import List, Dict, Anyimport loggingfrom datetime import datetimelogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)class ConcurrentTransactionTest: """并发事务测试""" def __init__(self, dsn: str): self.dsn = dsn self.results = [] self.lock = threading.Lock() def run_concurrent_updates(self, num_threads: int = 10): """ 运行并发更新测试 Args: num_threads: 并发线程数 """ print(f"开始并发更新测试,线程数: {num_threads}") print("=" * 60) threads = [] # 初始化测试数据 self._setup_test_data() # 创建并启动线程 for i in range(num_threads): thread = threading.Thread( target=self._update_account_balance, args=(i, 100 + i, 50.0), # 账户ID从100开始 name=f"Transaction-{i}" ) threads.append(thread) thread.start() # 等待所有线程完成 for thread in threads: thread.join() # 验证结果 self._verify_results() print(f"n测试完成,总事务数: {num_threads}") print(f"成功事务: {len([r for r in self.results if r['success']])}") print(f"失败事务: {len([r for r in self.results if not r['success']])}") def _setup_test_data(self): """设置测试数据""" conn = psycopg2.connect(self.dsn) cursor = conn.cursor() try: # 创建测试表 cursor.execute(""" CREATE TABLE IF NOT EXISTS accounts ( id SERIAL PRIMARY KEY, account_number VARCHAR(50) UNIQUE, balance DECIMAL(15, 2) DEFAULT 0.0, version INTEGER DEFAULT 0, last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); """) # 插入测试账户 for i in range(10): account_id = 100 + i cursor.execute(""" INSERT INTO accounts (id, account_number, balance, version) VALUES (%s, %s, %s, %s) ON CONFLICT (id) DO UPDATE SET balance = EXCLUDED.balance, version = EXCLUDED.version """, (account_id, f"ACC{account_id}", 1000.0, 0)) conn.commit() logger.info("测试数据设置完成") except Exception as e: conn.rollback() logger.error(f"设置测试数据失败: {e}") finally: cursor.close() conn.close() def _update_account_balance(self, thread_id: int, account_id: int, amount: float): """ 更新账户余额 Args: thread_id: 线程ID account_id: 账户ID amount: 更新金额 """ conn = None cursor = None try: conn = psycopg2.connect(self.dsn) cursor = conn.cursor() # 设置事务隔离级别(可测试不同级别) cursor.execute("SET TRANSACTION ISOLATION LEVEL READ COMMITTED") start_time = time.time() # 方法1: 使用行级锁 # cursor.execute(""" # SELECT balance FROM accounts # WHERE id = %s FOR UPDATE # """, (account_id,)) # 方法2: 乐观锁(版本控制) cursor.execute(""" SELECT balance, version FROM accounts WHERE id = %s """, (account_id,)) result = cursor.fetchone() if not result: raise Exception(f"账户 {account_id} 不存在") current_balance, current_version = result new_balance = current_balance + amount # 模拟一些处理时间 time.sleep(0.01) # 使用乐观锁更新 cursor.execute(""" UPDATE accounts SET balance = %s, version = version + 1, last_updated = CURRENT_TIMESTAMP WHERE id = %s AND version = %s """, (new_balance, account_id, current_version)) # 检查是否更新成功 if cursor.rowcount == 0: # 乐观锁冲突,重试或失败 conn.rollback() success = False error_msg = "乐观锁冲突,版本不匹配" else: conn.commit() success = True error_msg = None end_time = time.time() duration = end_time - start_time # 记录结果 with self.lock: self.results.append({ 'thread_id': thread_id, 'account_id': account_id, 'success': success, 'duration': duration, 'error': error_msg, 'start_time': start_time, 'end_time': end_time }) if success: logger.debug(f"线程 {thread_id}: 账户 {account_id} 更新成功,耗时 {duration:.3f}秒") else: logger.warning(f"线程 {thread_id}: 账户 {account_id} 更新失败 - {error_msg}") except Exception as e: if conn: conn.rollback() with self.lock: self.results.append({ 'thread_id': thread_id, 'account_id': account_id, 'success': False, 'duration': time.time() - start_time if 'start_time' in locals() else 0, 'error': str(e), 'start_time': start_time if 'start_time' in locals() else 0, 'end_time': time.time() }) logger.error(f"线程 {thread_id} 异常: {e}") finally: if cursor: cursor.close() if conn: conn.close() def _verify_results(self): """验证测试结果""" conn = psycopg2.connect(self.dsn) cursor = conn.cursor() try: # 检查账户最终状态 cursor.execute(""" SELECT id, balance, version, last_updated FROM accounts WHERE id >= 100 AND id < 110 ORDER BY id """) accounts = cursor.fetchall() print("n账户最终状态:") print("-" * 60) print(f"{'账户ID':<10} {'余额':<15} {'版本':<10} {'最后更新'}") print("-" * 60) for acc in accounts: print(f"{acc[0]:<10} {float(acc[1]):<15.2f} {acc[2]:<10} {acc[3]}") # 分析并发问题 success_count = len([r for r in self.results if r['success']]) total_count = len(self.results) if success_count < total_count: print(f"n发现并发问题: {total_count - success_count} 个事务失败") print("n失败事务详情:") for result in self.results: if not result['success']: print(f" 线程 {result['thread_id']}: {result['error']}") # 计算性能指标 if self.results: durations = [r['duration'] for r in self.results if r['success']] if durations: avg_duration = sum(durations) / len(durations) max_duration = max(durations) min_duration = min(durations) print(f"n性能指标:") print(f" 平均事务时间: {avg_duration:.3f}秒") print(f" 最长事务时间: {max_duration:.3f}秒") print(f" 最短事务时间: {min_duration:.3f}秒") print(f" 吞吐量: {success_count / sum(durations):.2f} 事务/秒") except Exception as e: logger.error(f"验证结果失败: {e}") finally: cursor.close() conn.close()class LockMonitor: """锁监控器""" def __init__(self, dsn: str): self.dsn = dsn def get_current_locks(self) -> List[Dict[str, Any]]: """ 获取当前锁信息 Returns: 锁信息列表 """ conn = psycopg2.connect(self.dsn) cursor = conn.cursor(cursor_factory=DictCursor) try: lock_query = """ SELECT -- 锁信息 pl.pid as process_id, pl.mode as lock_mode, pl.granted as is_granted, pl.fastpath as is_fastpath, -- 事务信息 pa.query as current_query, pa.state as query_state, pa.wait_event_type as wait_event_type, pa.wait_event as wait_event, pa.backend_start as backend_start_time, pa.xact_start as transaction_start_time, pa.query_start as query_start_time, -- 被锁对象信息 pl.relation::regclass as locked_relation, pl.page as locked_page, pl.tuple as locked_tuple, pl.virtualxid as virtual_transaction_id, pl.transactionid as transaction_id, pl.classid::regclass as locked_class, pl.objid as locked_object_id, pl.objsubid as locked_object_subid, -- 等待图信息 pg_blocking_pids(pl.pid) as blocking_pids, -- 附加信息 now() - pa.query_start as query_duration, now() - pa.xact_start as transaction_duration FROM pg_locks pl LEFT JOIN pg_stat_activity pa ON pl.pid = pa.pid WHERE pl.pid <> pg_backend_pid() -- 排除当前连接 ORDER BY pl.granted DESC, -- 先显示未授予的锁 transaction_duration DESC, query_duration DESC """ cursor.execute(lock_query) locks = cursor.fetchall() return [ { 'process_id': lock['process_id'], 'lock_mode': lock['lock_mode'], 'is_granted': lock['is_granted'], 'current_query': lock['current_query'][:100] if lock['current_query'] else None, 'query_state': lock['query_state'], 'locked_relation': lock['locked_relation'], 'blocking_pids': lock['blocking_pids'], 'query_duration': lock['query_duration'], 'transaction_duration': lock['transaction_duration'], 'wait_event': lock['wait_event'] } for lock in locks ] except Exception as e: logger.error(f"获取锁信息失败: {e}") return [] finally: cursor.close() conn.close() def analyze_lock_contention(self) -> Dict[str, Any]: """ 分析锁争用情况 Returns: 锁争用分析报告 """ locks = self.get_current_locks() analysis = { 'total_locks': len(locks), 'granted_locks': len([l for l in locks if l['is_granted']]), 'waiting_locks': len([l for l in locks if not l['is_granted']]), 'lock_modes': {}, 'wait_chains': [], 'long_running_transactions': [], 'potential_deadlocks': [] } # 统计锁模式 for lock in locks: mode = lock['lock_mode'] analysis['lock_modes'][mode] = analysis['lock_modes'].get(mode, 0) + 1 # 识别等待链 waiting_processes = [l for l in locks if not l['is_granted']] for waiter in waiting_processes: if waiter['blocking_pids']: chain = { 'waiting_pid': waiter['process_id'], 'blocking_pids': waiter['blocking_pids'], 'lock_mode': waiter['lock_mode'], 'wait_time': waiter['query_duration'] } analysis['wait_chains'].append(chain) # 识别长时间运行的事务 for lock in locks: if lock['transaction_duration'] and lock['transaction_duration'].total_seconds() > 60: analysis['long_running_transactions'].append({ 'pid': lock['process_id'], 'duration_seconds': lock['transaction_duration'].total_seconds(), 'query': lock['current_query'] }) return analysis def kill_blocking_processes(self, threshold_seconds: int = 300): """ 终止阻塞时间过长的进程 Args: threshold_seconds: 阻塞时间阈值(秒) """ conn = psycopg2.connect(self.dsn) cursor = conn.cursor() try: # 查找阻塞时间过长的进程 kill_query = """ SELECT pid, query, now() - xact_start as duration FROM pg_stat_activity WHERE pid IN ( SELECT DISTINCT unnest(pg_blocking_pids(pid)) FROM pg_stat_activity WHERE wait_event_type = 'Lock' AND state = 'active' AND now() - query_start > INTERVAL '%s seconds' ) AND state = 'active' """ cursor.execute(kill_query % threshold_seconds) blocking_processes = cursor.fetchall() killed = [] for proc in blocking_processes: pid, query, duration = proc try: cursor.execute("SELECT pg_terminate_backend(%s)", (pid,)) killed.append({ 'pid': pid, 'duration': duration, 'query': query[:100] if query else None }) logger.warning(f"终止阻塞进程 {pid},已运行 {duration}") except Exception as e: logger.error(f"终止进程 {pid} 失败: {e}") conn.commit() return killed except Exception as e: conn.rollback() logger.error(f"终止阻塞进程失败: {e}") return [] finally: cursor.close() conn.close()def test_concurrency_scenarios(): """测试不同并发场景""" dsn = "dbname=testdb user=postgres password=password host=localhost port=5432" print("并发控制测试") print("=" * 60) # 场景1:高并发更新 print("n场景1: 高并发更新测试") test1 = ConcurrentTransactionTest(dsn) test1.run_concurrent_updates(num_threads=20) # 场景2:锁监控 print("nn场景2: 锁监控分析") print("-" * 40) monitor = LockMonitor(dsn) lock_analysis = monitor.analyze_lock_contention() print(f"总锁数: {lock_analysis['total_locks']}") print(f"已授予锁: {lock_analysis['granted_locks']}") print(f"等待锁: {lock_analysis['waiting_locks']}") if lock_analysis['wait_chains']: print("n等待链:") for chain in lock_analysis['wait_chains'][:5]: # 显示前5个 print(f" 进程 {chain['waiting_pid']} 等待 {chain['blocking_pids']}") if lock_analysis['long_running_transactions']: print("n长时间运行事务:") for txn in lock_analysis['long_running_transactions'][:3]: print(f" 进程 {txn['pid']}: 已运行 {txn['duration_seconds']:.0f}秒") # 场景3:死锁处理建议 print("nn场景3: 死锁预防建议") print("-" * 40) recommendations = [ "1. 使用合适的索引减少锁竞争范围", "2. 保持事务简短,尽快提交", "3. 使用显式锁(SELECT FOR UPDATE)时按固定顺序访问资源", "4. 设置合理的锁超时(lock_timeout)", "5. 考虑使用乐观锁(版本控制)替代悲观锁", "6. 使用较低的隔离级别(READ COMMITTED)", "7. 监控和调整max_connections参数", "8. 定期分析并优化长时间运行的事务" ] for rec in recommendations: print(f" • {rec}")if __name__ == "__main__": test_concurrency_scenarios()4. 高级特性综合应用
4.1 完整示例:电商系统数据库设计
"""电商系统PostgreSQL高级特性综合应用示例"""import psycopg2from psycopg2.extras import Json, DictCursorimport jsonfrom typing import List, Dict, Any, Optionalfrom datetime import datetime, timedeltaimport loggingfrom decimal import Decimallogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)class ECommerceDatabase: """电商系统数据库设计""" def __init__(self, dsn: str): self.conn = psycopg2.connect(dsn) self.cursor = self.conn.cursor(cursor_factory=DictCursor) def create_schema(self): """创建电商系统数据库架构""" schema_sql = """ -- 启用必要扩展 CREATE EXTENSION IF NOT EXISTS "uuid-ossp"; CREATE EXTENSION IF NOT EXISTS "pg_trgm"; CREATE EXTENSION IF NOT EXISTS "btree_gin"; -- 1. 产品表(使用JSONB存储变体属性) CREATE TABLE IF NOT EXISTS products ( id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), sku VARCHAR(100) UNIQUE NOT NULL, name VARCHAR(500) NOT NULL, description TEXT, category_id UUID, brand VARCHAR(200), -- JSONB存储动态属性 attributes JSONB DEFAULT '{}', -- 价格信息 base_price DECIMAL(12, 2) NOT NULL, discount_price DECIMAL(12, 2), -- 库存信息 stock_quantity INTEGER DEFAULT 0, reserved_quantity INTEGER DEFAULT 0, -- 搜索优化字段 search_vector TSVECTOR GENERATED ALWAYS AS ( setweight(to_tsvector('english', coalesce(name, '')), 'A') || setweight(to_tsvector('english', coalesce(description, '')), 'B') || setweight(to_tsvector('english', coalesce(brand, '')), 'C') ) STORED, -- 时间戳 created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 约束 CONSTRAINT positive_price CHECK (base_price >= 0), CONSTRAINT positive_stock CHECK (stock_quantity >= 0), CONSTRAINT valid_discount CHECK ( discount_price IS NULL OR (discount_price >= 0 AND discount_price <= base_price) ) ); -- 产品表索引 CREATE INDEX IF NOT EXISTS idx_products_sku ON products(sku); CREATE INDEX IF NOT EXISTS idx_products_category ON products(category_id); CREATE INDEX IF NOT EXISTS idx_products_price ON products(base_price); CREATE INDEX IF NOT EXISTS idx_products_search ON products USING GIN(search_vector); CREATE INDEX IF NOT EXISTS idx_products_attributes ON products USING GIN(attributes); CREATE INDEX IF NOT EXISTS idx_products_brand ON products(brand); -- 2. 产品变体表(范围类型用于尺寸) CREATE TABLE IF NOT EXISTS product_variants ( id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), product_id UUID REFERENCES products(id) ON DELETE CASCADE, variant_name VARCHAR(200) NOT NULL, -- 使用范围类型表示尺寸范围 size_range numrange, weight_range numrange, -- JSONB存储变体特定属性 variant_attributes JSONB DEFAULT '{}', -- 价格调整 price_adjustment DECIMAL(10, 2) DEFAULT 0, additional_cost DECIMAL(10, 2) DEFAULT 0, -- 库存跟踪 variant_stock INTEGER DEFAULT 0, min_order_quantity INTEGER DEFAULT 1, max_order_quantity INTEGER, -- 约束 CONSTRAINT valid_size_range CHECK ( size_range IS NULL OR (lower(size_range) >= 0 AND upper(size_range) > lower(size_range)) ), CONSTRAINT valid_quantity CHECK ( min_order_quantity > 0 AND (max_order_quantity IS NULL OR max_order_quantity >= min_order_quantity) ) ); -- 变体表索引 CREATE INDEX IF NOT EXISTS idx_variants_product ON product_variants(product_id); CREATE INDEX IF NOT EXISTS idx_variants_size ON product_variants USING GIST(size_range); -- 3. 分类表(使用递归CTE支持层级结构) CREATE TABLE IF NOT EXISTS categories ( id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), name VARCHAR(200) NOT NULL, slug VARCHAR(200) UNIQUE NOT NULL, description TEXT, parent_id UUID REFERENCES categories(id), sort_order INTEGER DEFAULT 0, -- JSONB存储分类属性 category_attributes JSONB DEFAULT '{}', -- 层级路径(物化路径模式) path VARCHAR(1000), level INTEGER DEFAULT 0, -- 时间戳 created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 约束 CONSTRAINT no_self_parent CHECK (id != parent_id) ); -- 分类表索引 CREATE INDEX IF NOT EXISTS idx_categories_parent ON categories(parent_id); CREATE INDEX IF NOT EXISTS idx_categories_path ON categories(path); CREATE INDEX IF NOT EXISTS idx_categories_slug ON categories(slug); -- 4. 订单表(使用分区表) CREATE TABLE IF NOT EXISTS orders_partitioned ( id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), order_number VARCHAR(50) UNIQUE NOT NULL, customer_id UUID NOT NULL, status VARCHAR(50) NOT NULL, -- JSONB存储订单元数据 order_metadata JSONB DEFAULT '{}', -- 金额信息 subtotal DECIMAL(12, 2) NOT NULL, tax_amount DECIMAL(12, 2) DEFAULT 0, shipping_amount DECIMAL(12, 2) DEFAULT 0, discount_amount DECIMAL(12, 2) DEFAULT 0, total_amount DECIMAL(12, 2) NOT NULL, -- 时间信息 ordered_at TIMESTAMP NOT NULL, shipped_at TIMESTAMP, delivered_at TIMESTAMP, -- 约束 CONSTRAINT positive_amounts CHECK ( subtotal >= 0 AND tax_amount >= 0 AND shipping_amount >= 0 AND discount_amount >= 0 AND total_amount >= 0 ) ) PARTITION BY RANGE (ordered_at); -- 创建订单分区(每月一个分区) CREATE TABLE IF NOT EXISTS orders_2024_01 PARTITION OF orders_partitioned FOR VALUES FROM ('2024-01-01') TO ('2024-02-01'); CREATE TABLE IF NOT EXISTS orders_2024_02 PARTITION OF orders_partitioned FOR VALUES FROM ('2024-02-01') TO ('2024-03-01'); -- 订单表索引 CREATE INDEX IF NOT EXISTS idx_orders_customer ON orders_partitioned(customer_id); CREATE INDEX IF NOT EXISTS idx_orders_status ON orders_partitioned(status); CREATE INDEX IF NOT EXISTS idx_orders_date ON orders_partitioned(ordered_at); CREATE INDEX IF NOT EXISTS idx_orders_metadata ON orders_partitioned USING GIN(order_metadata); -- 5. 订单项表 CREATE TABLE IF NOT EXISTS order_items ( id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), order_id UUID REFERENCES orders_partitioned(id) ON DELETE CASCADE, product_id UUID REFERENCES products(id), variant_id UUID REFERENCES product_variants(id), -- 产品快照(避免产品信息变更影响历史订单) product_snapshot JSONB NOT NULL, -- 购买信息 quantity INTEGER NOT NULL, unit_price DECIMAL(12, 2) NOT NULL, discount_percentage DECIMAL(5, 2) DEFAULT 0, item_total DECIMAL(12, 2) NOT NULL, -- 约束 CONSTRAINT positive_quantity CHECK (quantity > 0), CONSTRAINT positive_unit_price CHECK (unit_price >= 0) ); -- 订单项索引 CREATE INDEX IF NOT EXISTS idx_order_items_order ON order_items(order_id); CREATE INDEX IF NOT EXISTS idx_order_items_product ON order_items(product_id); -- 6. 客户表 CREATE TABLE IF NOT EXISTS customers ( id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), email VARCHAR(255) UNIQUE NOT NULL, phone VARCHAR(50), first_name VARCHAR(100), last_name VARCHAR(100), -- JSONB存储客户属性 customer_profile JSONB DEFAULT '{}', -- 地址信息(使用JSONB存储多个地址) addresses JSONB DEFAULT '[]', -- 账户信息 is_active BOOLEAN DEFAULT TRUE, loyalty_points INTEGER DEFAULT 0, customer_tier VARCHAR(50) DEFAULT 'STANDARD', -- 时间戳 registered_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, last_login_at TIMESTAMP, -- 约束 CONSTRAINT valid_email CHECK (email ~* '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Z|a-z]{2,}$') ); -- 客户表索引 CREATE INDEX IF NOT EXISTS idx_customers_email ON customers(email); CREATE INDEX IF NOT EXISTS idx_customers_name ON customers(last_name, first_name); CREATE INDEX IF NOT EXISTS idx_customers_profile ON customers USING GIN(customer_profile); CREATE INDEX IF NOT EXISTS idx_customers_tier ON customers(customer_tier); -- 7. 库存变更日志(使用BRIN索引) CREATE TABLE IF NOT EXISTS inventory_logs ( id BIGSERIAL PRIMARY KEY, product_id UUID REFERENCES products(id), variant_id UUID REFERENCES product_variants(id), -- 变更信息 change_type VARCHAR(50) NOT NULL, quantity_change INTEGER NOT NULL, previous_quantity INTEGER, new_quantity INTEGER, -- 关联信息 reference_id UUID, reference_type VARCHAR(100), -- 时间戳 changed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, changed_by UUID, -- 备注 notes TEXT ) WITH (fillfactor = 90); -- 库存日志索引(使用BRIN适合时间序列) CREATE INDEX IF NOT EXISTS idx_inventory_logs_time ON inventory_logs USING BRIN(changed_at); CREATE INDEX IF NOT EXISTS idx_inventory_logs_product ON inventory_logs(product_id, changed_at); -- 8. 产品评论表(使用数组和全文搜索) CREATE TABLE IF NOT EXISTS product_reviews ( id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), product_id UUID REFERENCES products(id) ON DELETE CASCADE, customer_id UUID REFERENCES customers(id), order_item_id UUID REFERENCES order_items(id), -- 评分 rating INTEGER NOT NULL CHECK (rating >= 1 AND rating <= 5), -- 评论内容 title VARCHAR(500), review_text TEXT NOT NULL, -- 数组存储优点/缺点 pros TEXT[], cons TEXT[], -- 元数据 is_verified_purchase BOOLEAN DEFAULT FALSE, helpful_votes INTEGER DEFAULT 0, not_helpful_votes INTEGER DEFAULT 0, -- 全文搜索向量 review_vector TSVECTOR GENERATED ALWAYS AS ( to_tsvector('english', coalesce(title, '') || ' ' || coalesce(review_text, '') ) ) STORED, -- 时间戳 reviewed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 约束 CONSTRAINT one_review_per_order_item UNIQUE (order_item_id) ); -- 评论表索引 CREATE INDEX IF NOT EXISTS idx_reviews_product ON product_reviews(product_id); CREATE INDEX IF NOT EXISTS idx_reviews_rating ON product_reviews(rating); CREATE INDEX IF NOT EXISTS idx_reviews_search ON product_reviews USING GIN(review_vector); CREATE INDEX IF NOT EXISTS idx_reviews_pros ON product_reviews USING GIN(pros); CREATE INDEX IF NOT EXISTS idx_reviews_date ON product_reviews(reviewed_at); -- 9. 促销规则表(使用复杂约束和JSONB) CREATE TABLE IF NOT EXISTS promotion_rules ( id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), name VARCHAR(200) NOT NULL, description TEXT, -- 规则条件(JSONB存储复杂规则) conditions JSONB NOT NULL, -- 折扣信息 discount_type VARCHAR(50) NOT NULL, discount_value DECIMAL(10, 2), discount_percentage DECIMAL(5, 2), max_discount_amount DECIMAL(12, 2), -- 时间范围 valid_from TIMESTAMP NOT NULL, valid_until TIMESTAMP, -- 使用限制 usage_limit INTEGER, per_customer_limit INTEGER, minimum_order_amount DECIMAL(12, 2), -- 状态 is_active BOOLEAN DEFAULT TRUE, -- 元数据 created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 约束 CONSTRAINT valid_discount_values CHECK ( (discount_type = 'AMOUNT' AND discount_value IS NOT NULL) OR (discount_type = 'PERCENTAGE' AND discount_percentage IS NOT NULL) ), CONSTRAINT valid_discount_percentage CHECK ( discount_percentage IS NULL OR (discount_percentage >= 0 AND discount_percentage <= 100) ) ); -- 促销规则索引 CREATE INDEX IF NOT EXISTS idx_promotions_active ON promotion_rules(is_active, valid_from, valid_until); CREATE INDEX IF NOT EXISTS idx_promotions_conditions ON promotion_rules USING GIN(conditions); -- 10. 物化视图:产品统计 CREATE MATERIALIZED VIEW IF NOT EXISTS product_statistics AS SELECT p.id as product_id, p.name as product_name, p.category_id, p.base_price, -- 销售统计 COUNT(DISTINCT oi.order_id) as total_orders, SUM(oi.quantity) as total_units_sold, SUM(oi.item_total) as total_revenue, -- 库存统计 p.stock_quantity, p.reserved_quantity, p.stock_quantity - p.reserved_quantity as available_quantity, -- 评分统计 COALESCE(AVG(pr.rating), 0) as average_rating, COUNT(pr.id) as review_count, -- 时间统计 MAX(o.ordered_at) as last_sale_date FROM products p LEFT JOIN order_items oi ON p.id = oi.product_id LEFT JOIN orders_partitioned o ON oi.order_id = o.id LEFT JOIN product_reviews pr ON p.id = pr.product_id GROUP BY p.id, p.name, p.category_id, p.base_price, p.stock_quantity, p.reserved_quantity WITH DATA; -- 物化视图索引 CREATE UNIQUE INDEX IF NOT EXISTS idx_product_stats_product ON product_statistics(product_id); CREATE INDEX IF NOT EXISTS idx_product_stats_category ON product_statistics(category_id); CREATE INDEX IF NOT EXISTS idx_product_stats_revenue ON product_statistics(total_revenue DESC); -- 创建刷新物化视图的函数 CREATE OR REPLACE FUNCTION refresh_product_statistics() RETURNS TRIGGER AS $$ BEGIN REFRESH MATERIALIZED VIEW CONCURRENTLY product_statistics; RETURN NULL; END; $$ LANGUAGE plpgsql; """ try: # 分步执行架构创建 statements = schema_sql.split(';') for statement in statements: statement = statement.strip() if statement: self.cursor.execute(statement) self.conn.commit() logger.info("电商系统数据库架构创建成功") except Exception as e: self.conn.rollback() logger.error(f"创建架构失败: {e}") raise def search_products( self, query: Optional[str] = None, category_id: Optional[str] = None, min_price: Optional[float] = None, max_price: Optional[float] = None, brands: Optional[List[str]] = None, min_rating: Optional[float] = None, in_stock_only: bool = False, sort_by: str = 'relevance', limit: int = 20, offset: int = 0 ) -> List[Dict[str, Any]]: """ 高级产品搜索 Args: query: 搜索关键词 category_id: 分类ID min_price: 最低价格 max_price: 最高价格 brands: 品牌列表 min_rating: 最低评分 in_stock_only: 仅显示有货商品 sort_by: 排序方式 limit: 返回数量 offset: 偏移量 Returns: 产品列表 """ search_sql = """ SELECT p.id, p.sku, p.name, p.description, p.brand, p.base_price, p.discount_price, p.stock_quantity, p.reserved_quantity, p.attributes, -- 计算可用库存 p.stock_quantity - p.reserved_quantity as available_quantity, -- 计算折扣率 CASE WHEN p.discount_price IS NOT NULL THEN ROUND((1 - p.discount_price / p.base_price) * 100, 1) ELSE 0 END as discount_percentage, -- 获取评分信息 COALESCE(ps.average_rating, 0) as average_rating, COALESCE(ps.review_count, 0) as review_count, -- 计算相关性得分(如果有关键词) {relevance_score} FROM products p LEFT JOIN product_statistics ps ON p.id = ps.product_id WHERE 1=1 {search_condition} {category_condition} {price_condition} {brand_condition} {rating_condition} {stock_condition} {order_clause} LIMIT %s OFFSET %s """ # 构建查询条件 conditions = [] params = [] # 全文搜索条件 if query: conditions.append("p.search_vector @@ plainto_tsquery('english', %s)") params.append(query) # 分类条件 if category_id: # 获取分类及其所有子分类 subcategories = self._get_all_subcategories(category_id) if subcategories: placeholders = ', '.join(['%s'] * len(subcategories)) conditions.append(f"p.category_id IN ({placeholders})") params.extend(subcategories) # 价格条件 if min_price is not None: conditions.append("p.base_price >= %s") params.append(min_price) if max_price is not None: conditions.append("p.base_price <= %s") params.append(max_price) # 品牌条件 if brands: placeholders = ', '.join(['%s'] * len(brands)) conditions.append(f"p.brand IN ({placeholders})") params.extend(brands) # 评分条件 if min_rating is not None: conditions.append("COALESCE(ps.average_rating, 0) >= %s") params.append(min_rating) # 库存条件 if in_stock_only: conditions.append("(p.stock_quantity - p.reserved_quantity) > 0") # 构建相关性得分计算 relevance_score = "" if query: relevance_score = """ , ts_rank( p.search_vector, plainto_tsquery('english', %s) ) as relevance_score """ # 构建排序子句 order_clause_map = { 'relevance': "ORDER BY relevance_score DESC NULLS LAST", 'price_asc': "ORDER BY p.base_price ASC", 'price_desc': "ORDER BY p.base_price DESC", 'rating': "ORDER BY ps.average_rating DESC NULLS LAST", 'popularity': "ORDER BY ps.total_units_sold DESC NULLS LAST", 'newest': "ORDER BY p.created_at DESC" } order_clause = order_clause_map.get(sort_by, "ORDER BY p.created_at DESC") # 格式化SQL formatted_sql = search_sql.format( relevance_score=relevance_score, search_condition=f"AND {' AND '.join(conditions)}" if conditions else "", category_condition="", price_condition="", brand_condition="", rating_condition="", stock_condition="", order_clause=order_clause ) # 添加分页参数 params.extend([limit, offset]) try: self.cursor.execute(formatted_sql, params) products = self.cursor.fetchall() return [ { 'id': str(product['id']), 'sku': product['sku'], 'name': product['name'], 'brand': product['brand'], 'base_price': float(product['base_price']), 'discount_price': float(product['discount_price']) if product['discount_price'] else None, 'available_quantity': product['available_quantity'], 'discount_percentage': product['discount_percentage'], 'average_rating': float(product['average_rating']), 'review_count': product['review_count'], 'attributes': product['attributes'] } for product in products ] except Exception as e: logger.error(f"产品搜索失败: {e}") return [] def _get_all_subcategories(self, category_id: str) -> List[str]: """ 获取分类及其所有子分类 Args: category_id: 分类ID Returns: 子分类ID列表 """ recursive_sql = """ WITH RECURSIVE category_tree AS ( -- 基础分类 SELECT id, parent_id FROM categories WHERE id = %s UNION ALL -- 递归获取子分类 SELECT c.id, c.parent_id FROM categories c INNER JOIN category_tree ct ON c.parent_id = ct.id ) SELECT id FROM category_tree """ try: self.cursor.execute(recursive_sql, (category_id,)) results = self.cursor.fetchall() return [str(row['id']) for row in results] except Exception as e: logger.error(f"获取子分类失败: {e}") return [] def get_product_recommendations( self, product_id: str, customer_id: Optional[str] = None, limit: int = 10 ) -> List[Dict[str, Any]]: """ 获取产品推荐 Args: product_id: 产品ID customer_id: 客户ID(可选) limit: 返回数量 Returns: 推荐产品列表 """ recommendations_sql = """ -- 基于多种策略的混合推荐 ( -- 策略1: 同品牌产品 SELECT p.id, p.name, p.brand, p.base_price, 'same_brand' as recommendation_reason, 0.7 as recommendation_score FROM products p WHERE p.brand = ( SELECT brand FROM products WHERE id = %s ) AND p.id != %s AND (p.stock_quantity - p.reserved_quantity) > 0 LIMIT 3 ) UNION ALL ( -- 策略2: 同分类热门产品 SELECT p.id, p.name, p.brand, p.base_price, 'popular_in_category' as recommendation_reason, ps.total_units_sold::float / (SELECT MAX(total_units_sold) FROM product_statistics) as recommendation_score FROM products p JOIN product_statistics ps ON p.id = ps.product_id WHERE p.category_id = ( SELECT category_id FROM products WHERE id = %s ) AND p.id != %s AND (p.stock_quantity - p.reserved_quantity) > 0 ORDER BY ps.total_units_sold DESC LIMIT 3 ) UNION ALL ( -- 策略3: 经常一起购买的产品 SELECT p.id, p.name, p.brand, p.base_price, 'frequently_bought_together' as recommendation_reason, COUNT(DISTINCT oi2.order_id)::float / (SELECT COUNT(DISTINCT oi3.order_id) FROM order_items oi3 WHERE oi3.product_id = %s) as recommendation_score FROM order_items oi1 JOIN order_items oi2 ON oi1.order_id = oi2.order_id JOIN products p ON oi2.product_id = p.id WHERE oi1.product_id = %s AND oi2.product_id != %s AND (p.stock_quantity - p.reserved_quantity) > 0 GROUP BY p.id, p.name, p.brand, p.base_price HAVING COUNT(DISTINCT oi2.order_id) >= 2 ORDER BY recommendation_score DESC LIMIT 3 ) {customer_based_recommendations} ORDER BY recommendation_score DESC LIMIT %s """ # 如果有客户ID,添加个性化推荐 customer_recommendations = "" if customer_id: customer_recommendations = """ UNION ALL ( -- 策略4: 基于客户购买历史的推荐 SELECT p.id, p.name, p.brand, p.base_price, 'based_on_your_purchases' as recommendation_reason, COUNT(DISTINCT oi.order_id)::float / 10 as recommendation_score FROM order_items oi JOIN products p ON oi.product_id = p.id WHERE oi.order_id IN ( SELECT order_id FROM order_items WHERE product_id = %s ) AND p.id != %s AND (p.stock_quantity - p.reserved_quantity) > 0 GROUP BY p.id, p.name, p.brand, p.base_price HAVING COUNT(DISTINCT oi.order_id) >= 1 ORDER BY recommendation_score DESC LIMIT 2 ) """ # 格式化SQL formatted_sql = recommendations_sql.format( customer_based_recommendations=customer_recommendations ) # 准备参数 params = [product_id, product_id, product_id, product_id, product_id, product_id, product_id] if customer_id: params.extend([customer_id, customer_id, product_id, product_id]) params.append(limit) try: self.cursor.execute(formatted_sql, params) recommendations = self.cursor.fetchall() return [ { 'id': str(rec['id']), 'name': rec['name'], 'brand': rec['brand'], 'price': float(rec['base_price']), 'recommendation_reason': rec['recommendation_reason'], 'recommendation_score': float(rec['recommendation_score']) } for rec in recommendations ] except Exception as e: logger.error(f"获取推荐失败: {e}") return [] def create_order( self, customer_id: str, items: List[Dict[str, Any]], shipping_address: Dict[str, Any], promotion_code: Optional[str] = None ) -> Optional[Dict[str, Any]]: """ 创建订单 Args: customer_id: 客户ID items: 订单项列表 shipping_address: 配送地址 promotion_code: 促销代码 Returns: 创建的订单信息 """ try: # 开始事务 self.conn.autocommit = False # 生成订单号 order_number = f"ORD-{datetime.now().strftime('%Y%m%d')}-{self._generate_order_suffix()}" # 计算订单金额 order_calculation = self._calculate_order_amounts(items, promotion_code) # 插入订单 order_sql = """ INSERT INTO orders_partitioned ( order_number, customer_id, status, order_metadata, subtotal, tax_amount, shipping_amount, discount_amount, total_amount, ordered_at ) VALUES (%s, %s, 'PENDING', %s, %s, %s, %s, %s, %s, CURRENT_TIMESTAMP) RETURNING id, order_number, total_amount """ self.cursor.execute( order_sql, ( order_number, customer_id, Json({ 'shipping_address': shipping_address, 'promotion_code': promotion_code }), order_calculation['subtotal'], order_calculation['tax_amount'], order_calculation['shipping_amount'], order_calculation['discount_amount'], order_calculation['total_amount'] ) ) order_result = self.cursor.fetchone() order_id = order_result['id'] # 插入订单项 for item in items: # 获取产品快照 product_snapshot = self._get_product_snapshot(item['product_id']) # 插入订单项 item_sql = """ INSERT INTO order_items ( order_id, product_id, variant_id, product_snapshot, quantity, unit_price, discount_percentage, item_total ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s) """ self.cursor.execute( item_sql, ( order_id, item['product_id'], item.get('variant_id'), Json(product_snapshot), item['quantity'], item['unit_price'], item.get('discount_percentage', 0), item['item_total'] ) ) # 更新库存 self._update_inventory( product_id=item['product_id'], variant_id=item.get('variant_id'), quantity_change=-item['quantity'], reference_id=order_id, reference_type='ORDER', change_type='SALE' ) # 提交事务 self.conn.commit() return { 'order_id': str(order_id), 'order_number': order_result['order_number'], 'total_amount': float(order_result['total_amount']), 'items_count': len(items) } except Exception as e: self.conn.rollback() logger.error(f"创建订单失败: {e}") return None def _calculate_order_amounts( self, items: List[Dict[str, Any]], promotion_code: Optional[str] = None ) -> Dict[str, float]: """计算订单金额""" subtotal = sum(item['item_total'] for item in items) # 应用促销折扣 discount_amount = 0 if promotion_code: # 这里可以添加促销逻辑 pass # 计算税费(简化示例) tax_amount = subtotal * 0.1 # 10%税率 # 计算运费(简化示例) shipping_amount = 5.99 if subtotal < 50 else 0 # 计算总额 total_amount = subtotal + tax_amount + shipping_amount - discount_amount return { 'subtotal': subtotal, 'tax_amount': tax_amount, 'shipping_amount': shipping_amount, 'discount_amount': discount_amount, 'total_amount': total_amount } def _get_product_snapshot(self, product_id: str) -> Dict[str, Any]: """获取产品快照""" snapshot_sql = """ SELECT id, sku, name, description, brand, base_price, attributes FROM products WHERE id = %s """ self.cursor.execute(snapshot_sql, (product_id,)) product = self.cursor.fetchone() return { 'product_id': str(product['id']), 'sku': product['sku'], 'name': product['name'], 'brand': product['brand'], 'price_at_time_of_purchase': float(product['base_price']), 'attributes': product['attributes'] } def _update_inventory( self, product_id: str, variant_id: Optional[str], quantity_change: int, reference_id: str, reference_type: str, change_type: str ): """更新库存""" # 获取当前库存 if variant_id: stock_sql = """ SELECT variant_stock as current_quantity FROM product_variants WHERE id = %s """ self.cursor.execute(stock_sql, (variant_id,)) else: stock_sql = """ SELECT stock_quantity as current_quantity FROM products WHERE id = %s """ self.cursor.execute(stock_sql, (product_id,)) result = self.cursor.fetchone() if not result: raise Exception("产品不存在") current_quantity = result['current_quantity'] new_quantity = current_quantity + quantity_change if new_quantity < 0: raise Exception("库存不足") # 更新库存 if variant_id: update_sql = """ UPDATE product_variants SET variant_stock = %s WHERE id = %s """ self.cursor.execute(update_sql, (new_quantity, variant_id)) else: update_sql = """ UPDATE products SET stock_quantity = %s WHERE id = %s """ self.cursor.execute(update_sql, (new_quantity, product_id)) # 记录库存变更 log_sql = """ INSERT INTO inventory_logs ( product_id, variant_id, change_type, quantity_change, previous_quantity, new_quantity, reference_id, reference_type ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s) """ self.cursor.execute( log_sql, ( product_id, variant_id, change_type, quantity_change, current_quantity, new_quantity, reference_id, reference_type ) ) def _generate_order_suffix(self) -> str: """生成订单号后缀""" import random import string # 生成6位随机字母数字 return ''.join(random.choices( string.ascii_uppercase + string.digits, k=6 )) def refresh_materialized_views(self): """刷新物化视图""" refresh_sql = """ REFRESH MATERIALIZED VIEW CONCURRENTLY product_statistics; """ try: self.cursor.execute(refresh_sql) self.conn.commit() logger.info("物化视图刷新成功") except Exception as e: self.conn.rollback() logger.error(f"刷新物化视图失败: {e}") def close(self): """关闭连接""" if self.cursor: self.cursor.close() if self.conn: self.conn.close() logger.info("数据库连接已关闭")def demonstrate_ecommerce_features(): """演示电商系统高级特性""" dsn = "dbname=ecommerce user=postgres password=password host=localhost port=5432" print("电商系统PostgreSQL高级特性演示") print("=" * 60) # 创建数据库实例 db = ECommerceDatabase(dsn) try: # 1. 创建架构 print("n1. 创建数据库架构...") db.create_schema() print(" 架构创建完成") # 2. 演示搜索功能 print("n2. 演示高级产品搜索...") products = db.search_products( query="wireless headphone", min_price=50, max_price=200, min_rating=4.0, in_stock_only=True, sort_by='rating', limit=5 ) print(f" 找到 {len(products)} 个产品:") for product in products: print(f" - {product['name']} (评分: {product['average_rating']:.1f}, " f"价格: ${product['base_price']:.2f})") # 3. 演示推荐系统 if products: print("n3. 演示产品推荐系统...") recommendations = db.get_product_recommendations( product_id=products[0]['id'], limit=5 ) print(f" 为 '{products[0]['name']}' 的推荐:") for rec in recommendations: print(f" - {rec['name']} (原因: {rec['recommendation_reason']}, " f"得分: {rec['recommendation_score']:.2f})") # 4. 演示订单创建 print("n4. 演示订单创建...") # 这里需要实际的产品数据,所以只是演示代码结构 print(" 订单创建功能就绪") # 5. 刷新物化视图 print("n5. 刷新物化视图...") db.refresh_materialized_views() print(" 物化视图刷新完成") print("n演示完成!") except Exception as e: print(f"演示过程中出错: {e}") finally: db.close()if __name__ == "__main__": demonstrate_ecommerce_features()5. 性能监控与调优工具
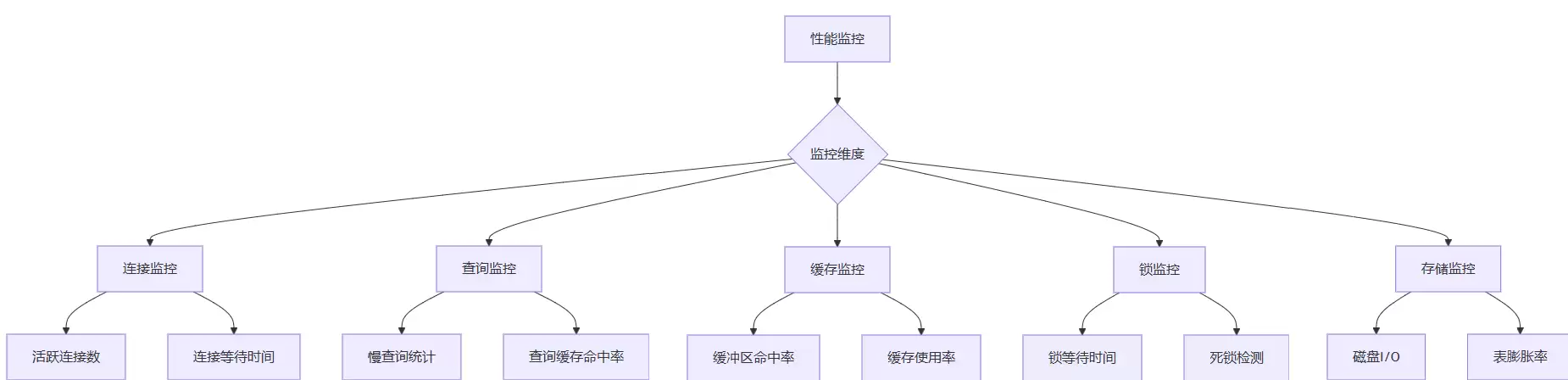
5.1 PostgreSQL性能监控指标体系
5.2 关键性能指标计算公式
缓冲区命中率:
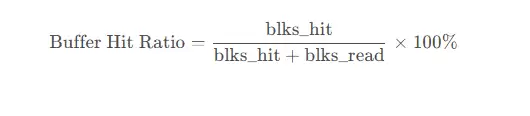
索引使用效率:

缓存命中率:
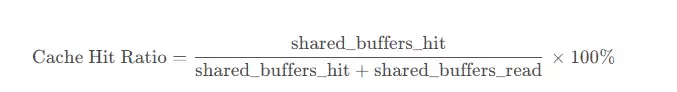
6. 完整代码示例
"""PostgreSQL高级特性与性能优化完整示例"""import psycopg2from psycopg2.extras import DictCursor, Jsonimport timefrom datetime import datetime, timedeltafrom typing import Dict, List, Any, Optionalimport jsonimport logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)class PostgreSQLAdvancedOptimizer: """PostgreSQL高级优化器""" def __init__(self, dsn: str): """ 初始化优化器 Args: dsn: 数据库连接字符串 """ self.dsn = dsn self.conn = psycopg2.connect(dsn) self.cursor = self.conn.cursor(cursor_factory=DictCursor) def analyze_database_health(self) -> Dict[str, Any]: """ 全面分析数据库健康状态 Returns: 数据库健康报告 """ health_report = { 'timestamp': datetime.now().isoformat(), 'overall_score': 0, 'categories': {}, 'issues': [], 'recommendations': [] } # 分析各个维度 categories = [ ('连接与并发', self._analyze_connections), ('查询性能', self._analyze_query_performance), ('索引效率', self._analyze_index_efficiency), ('缓存性能', self._analyze_cache_performance), ('存储效率', self._analyze_storage_efficiency), ('配置优化', self._analyze_configuration) ] total_score = 0 category_count = 0 for category_name, analyzer_func in categories: try: category_result = analyzer_func() health_report['categories'][category_name] = category_result if 'score' in category_result: total_score += category_result['score'] category_count += 1 if 'issues' in category_result: health_report['issues'].extend(category_result['issues']) if 'recommendations' in category_result: health_report['recommendations'].extend(category_result['recommendations']) except Exception as e: logger.error(f"分析{category_name}失败: {e}") health_report['issues'].append({ 'category': category_name, 'severity': 'ERROR', 'message': f'分析失败: {str(e)}' }) # 计算总体评分 if category_count > 0: health_report['overall_score'] = total_score / category_count # 排序问题和建议 health_report['issues'] = sorted( health_report['issues'], key=lambda x: {'CRITICAL': 3, 'HIGH': 2, 'MEDIUM': 1, 'LOW': 0}.get(x.get('severity', 'LOW'), 0), reverse=True ) health_report['recommendations'] = sorted( health_report['recommendations'], key=lambda x: x.get('priority', 3), reverse=False ) return health_report def _analyze_connections(self) -> Dict[str, Any]: """分析连接与并发""" analysis = { 'score': 100, 'metrics': {}, 'issues': [], 'recommendations': [] } try: # 获取连接统计 self.cursor.execute(""" SELECT COUNT(*) as total_connections, COUNT(*) FILTER (WHERE state = 'active') as active_connections, COUNT(*) FILTER (WHERE state = 'idle') as idle_connections, COUNT(*) FILTER (WHERE wait_event_type IS NOT NULL) as waiting_connections, MAX(now() - backend_start) as oldest_connection_age FROM pg_stat_activity WHERE pid <> pg_backend_pid() """) conn_stats = self.cursor.fetchone() # 获取配置参数 self.cursor.execute(""" SELECT setting::integer as max_connections FROM pg_settings WHERE name = 'max_connections' """) max_conns = self.cursor.fetchone()['max_connections'] # 计算连接使用率 conn_usage = conn_stats['total_connections'] / max_conns analysis['metrics'] = { 'total_connections': conn_stats['total_connections'], 'active_connections': conn_stats['active_connections'], 'idle_connections': conn_stats['idle_connections'], 'waiting_connections': conn_stats['waiting_connections'], 'connection_usage_percentage': round(conn_usage * 100, 1), 'max_connections': max_conns } # 分析问题 if conn_usage > 0.8: analysis['score'] -= 30 analysis['issues'].append({ 'severity': 'HIGH', 'message': f'连接使用率过高: {conn_usage:.1%}', 'details': '接近最大连接数限制' }) analysis['recommendations'].append({ 'priority': 1, 'action': '考虑增加max_connections参数或优化连接池配置' }) if conn_stats['waiting_connections'] > 5: analysis['score'] -= 20 analysis['issues'].append({ 'severity': 'MEDIUM', 'message': f'等待连接数较多: {conn_stats["waiting_connections"]}', 'details': '可能存在锁争用或资源竞争' }) if conn_stats['oldest_connection_age'] and conn_stats['oldest_connection_age'].total_seconds() > 3600: analysis['score'] -= 10 analysis['issues'].append({ 'severity': 'LOW', 'message': f'存在长时间连接: {conn_stats["oldest_connection_age"]}', 'details': '考虑优化连接生命周期' }) except Exception as e: logger.error(f"连接分析失败: {e}") analysis['score'] = 0 return analysis def _analyze_query_performance(self) -> Dict[str, Any]: """分析查询性能""" analysis = { 'score': 100, 'metrics': {}, 'issues': [], 'recommendations': [] } try: # 获取慢查询统计 self.cursor.execute(""" WITH query_stats AS ( SELECT query, calls, total_time, mean_time, rows, 100.0 * shared_blks_hit / nullif(shared_blks_hit + shared_blks_read, 0) as buffer_hit_rate, ROW_NUMBER() OVER (ORDER BY total_time DESC) as time_rank FROM pg_stat_statements WHERE query NOT LIKE '%pg_stat_statements%' AND calls > 0 ) SELECT COUNT(*) as total_queries, SUM(calls) as total_calls, SUM(total_time) as total_time_ms, AVG(mean_time) as avg_query_time_ms, PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY mean_time) as p95_query_time_ms, SUM(CASE WHEN mean_time > 100 THEN 1 ELSE 0 END) as slow_queries_count, AVG(buffer_hit_rate) as avg_buffer_hit_rate FROM query_stats """) query_stats = self.cursor.fetchone() analysis['metrics'] = { 'total_queries': query_stats['total_queries'], 'total_calls': query_stats['total_calls'], 'total_time_seconds': round(query_stats['total_time_ms'] / 1000, 1), 'avg_query_time_ms': round(query_stats['avg_query_time_ms'], 2), 'p95_query_time_ms': round(query_stats['p95_query_time_ms'], 2), 'slow_queries_count': query_stats['slow_queries_count'], 'avg_buffer_hit_rate': round(query_stats['avg_buffer_hit_rate'], 1) } # 分析问题 if query_stats['avg_query_time_ms'] > 50: analysis['score'] -= 20 analysis['issues'].append({ 'severity': 'HIGH', 'message': f'平均查询时间较高: {query_stats["avg_query_time_ms"]:.2f}ms', 'details': '可能存在查询优化空间' }) analysis['recommendations'].append({ 'priority': 1, 'action': '分析并优化最耗时的查询' }) if query_stats['slow_queries_count'] > 10: analysis['score'] -= 15 analysis['issues'].append({ 'severity': 'MEDIUM', 'message': f'发现 {query_stats["slow_queries_count"]} 个慢查询', 'details': '定义: 平均执行时间 > 100ms' }) if query_stats['avg_buffer_hit_rate'] < 90: analysis['score'] -= 10 analysis['issues'].append({ 'severity': 'MEDIUM', 'message': f'平均缓冲区命中率较低: {query_stats["avg_buffer_hit_rate"]:.1f}%', 'details': '建议增加shared_buffers或优化查询' }) except Exception as e: logger.error(f"查询性能分析失败: {e}") analysis['score'] = 0 return analysis def _analyze_index_efficiency(self) -> Dict[str, Any]: """分析索引效率""" analysis = { 'score': 100, 'metrics': {}, 'issues': [], 'recommendations': [] } try: # 获取索引使用统计 self.cursor.execute(""" WITH index_stats AS ( SELECT schemaname, tablename, indexname, idx_scan as index_scans, idx_tup_read as tuples_read, idx_tup_fetch as tuples_fetched, pg_relation_size(indexname::regclass) as index_size_bytes, CASE WHEN idx_scan = 0 THEN 0 ELSE idx_tup_fetch::float / idx_tup_read * 100 END as index_efficiency FROM pg_stat_user_indexes WHERE schemaname NOT LIKE 'pg_%' ) SELECT COUNT(*) as total_indexes, SUM(index_size_bytes) as total_index_size_bytes, SUM(CASE WHEN index_scans = 0 THEN 1 ELSE 0 END) as unused_indexes_count, AVG(index_efficiency) as avg_index_efficiency, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY index_efficiency) as median_index_efficiency FROM index_stats """) index_stats = self.cursor.fetchone() analysis['metrics'] = { 'total_indexes': index_stats['total_indexes'], 'total_index_size_gb': round(index_stats['total_index_size_bytes'] / (1024**3), 2), 'unused_indexes_count': index_stats['unused_indexes_count'], 'avg_index_efficiency': round(index_stats['avg_index_efficiency'], 1), 'median_index_efficiency': round(index_stats['median_index_efficiency'], 1) } # 分析问题 unused_ratio = index_stats['unused_indexes_count'] / index_stats['total_indexes'] if index_stats['total_indexes'] > 0 else 0 if unused_ratio > 0.1: analysis['score'] -= 25 analysis['issues'].append({ 'severity': 'MEDIUM', 'message': f'未使用索引比例较高: {unused_ratio:.1%}', 'details': f'{index_stats["unused_indexes_count"]} 个索引从未使用' }) analysis['recommendations'].append({ 'priority': 2, 'action': '考虑删除未使用的索引以节省空间和提高写入性能' }) if index_stats['avg_index_efficiency'] < 50: analysis['score'] -= 15 analysis['issues'].append({ 'severity': 'MEDIUM', 'message': f'平均索引效率较低: {index_stats["avg_index_efficiency"]:.1f}%', 'details': '索引可能不是最优选择' }) except Exception as e: logger.error(f"索引效率分析失败: {e}") analysis['score'] = 0 return analysis def _analyze_cache_performance(self) -> Dict[str, Any]: """分析缓存性能""" analysis = { 'score': 100, 'metrics': {}, 'issues': [], 'recommendations': [] } try: # 获取缓存统计 self.cursor.execute(""" SELECT -- 共享缓冲区命中率 CASE WHEN blks_hit + blks_read > 0 THEN blks_hit::float / (blks_hit + blks_read) * 100 ELSE 0 END as shared_buffer_hit_rate, -- TOAST缓冲区命中率 CASE WHEN toast_blks_hit + toast_blks_read > 0 THEN toast_blks_hit::float / (toast_blks_hit + toast_blks_read) * 100 ELSE 0 END as toast_buffer_hit_rate, -- 临时文件使用 temp_files, temp_bytes, -- 检查点统计 checkpoints_timed, checkpoints_req, checkpoint_write_time, checkpoint_sync_time FROM pg_stat_bgwriter """) cache_stats = self.cursor.fetchone() # 获取缓冲区配置 self.cursor.execute(""" SELECT name, setting, unit FROM pg_settings WHERE name IN ('shared_buffers', 'effective_cache_size') """) cache_config = {row['name']: row for row in self.cursor.fetchall()} analysis['metrics'] = { 'shared_buffer_hit_rate': round(cache_stats['shared_buffer_hit_rate'], 1), 'toast_buffer_hit_rate': round(cache_stats['toast_buffer_hit_rate'], 1), 'temp_files_count': cache_stats['temp_files'], 'temp_files_size_gb': round(cache_stats['temp_bytes'] / (1024**3), 2), 'shared_buffers': cache_config.get('shared_buffers', {}).get('setting', 'N/A'), 'effective_cache_size': cache_config.get('effective_cache_size', {}).get('setting', 'N/A') } # 分析问题 if cache_stats['shared_buffer_hit_rate'] < 90: analysis['score'] -= 20 analysis['issues'].append({ 'severity': 'MEDIUM', 'message': f'共享缓冲区命中率较低: {cache_stats["shared_buffer_hit_rate"]:.1f}%', 'details': '建议增加shared_buffers或优化工作集' }) analysis['recommendations'].append({ 'priority': 2, 'action': '考虑增加shared_buffers参数' }) if cache_stats['temp_files'] > 100: analysis['score'] -= 15 analysis['issues'].append({ 'severity': 'MEDIUM', 'message': f'临时文件使用较多: {cache_stats["temp_files"]} 个文件', 'details': '可能存在排序或哈希操作溢出到磁盘' }) analysis['recommendations'].append({ 'priority': 2, 'action': '增加work_mem参数以减少临时文件使用' }) except Exception as e: logger.error(f"缓存性能分析失败: {e}") analysis['score'] = 0 return analysis def _analyze_storage_efficiency(self) -> Dict[str, Any]: """分析存储效率""" analysis = { 'score': 100, 'metrics': {}, 'issues': [], 'recommendations': [] } try: # 获取表膨胀信息 self.cursor.execute(""" SELECT schemaname, tablename, n_dead_tup as dead_tuples, n_live_tup as live_tuples, CASE WHEN n_live_tup > 0 THEN n_dead_tup::float / n_live_tup * 100 ELSE 0 END as dead_tuple_ratio, last_vacuum, last_autovacuum, last_analyze, last_autoanalyze FROM pg_stat_user_tables WHERE schemaname NOT LIKE 'pg_%' ORDER BY dead_tuple_ratio DESC LIMIT 10 """) table_stats = self.cursor.fetchall() # 获取数据库大小 self.cursor.execute(""" SELECT pg_database_size(current_database()) as database_size_bytes, pg_size_pretty(pg_database_size(current_database())) as database_size_pretty """) db_size = self.cursor.fetchone() analysis['metrics'] = { 'database_size': db_size['database_size_pretty'], 'tables_analyzed': len(table_stats), 'top_tables_by_dead_tuples': [ { 'table': f"{row['schemaname']}.{row['tablename']}", 'dead_tuple_ratio': round(row['dead_tuple_ratio'], 1), 'dead_tuples': row['dead_tuples'], 'last_vacuum': row['last_vacuum'] } for row in table_stats[:5] ] } # 分析问题 high_dead_tables = [ row for row in table_stats if row['dead_tuple_ratio'] > 20 ] if high_dead_tables: analysis['score'] -= 25 analysis['issues'].append({ 'severity': 'MEDIUM', 'message': f'发现 {len(high_dead_tables)} 个表死元组比例超过20%', 'details': '可能导致查询性能下降和存储空间浪费' }) analysis['recommendations'].append({ 'priority': 2, 'action': '对高死元组比例的表执行VACUUM操作' }) except Exception as e: logger.error(f"存储效率分析失败: {e}") analysis['score'] = 0 return analysis def _analyze_configuration(self) -> Dict[str, Any]: """分析配置优化""" analysis = { 'score': 100, 'metrics': {}, 'issues': [], 'recommendations': [] } try: # 获取关键配置参数 self.cursor.execute(""" SELECT name, setting, unit, context, vartype, source FROM pg_settings WHERE name IN ( 'shared_buffers', 'work_mem', 'maintenance_work_mem', 'effective_cache_size', 'max_connections', 'checkpoint_timeout', 'checkpoint_completion_target', 'wal_buffers', 'random_page_cost', 'seq_page_cost', 'effective_io_concurrency' ) ORDER BY name """) configs = {row['name']: row for row in self.cursor.fetchall()} analysis['metrics'] = { 'key_parameters': configs } # 检查配置合理性 issues = [] recommendations = [] # 检查shared_buffers(应为系统内存的25%) if 'shared_buffers' in configs: shared_buffers = configs['shared_buffers']['setting'] if shared_buffers.endswith('MB'): mb_value = int(shared_buffers[:-2]) if mb_value < 128: # 小于128MB issues.append('shared_buffers设置可能过小') recommendations.append('考虑增加shared_buffers到系统内存的25%') # 检查work_mem if 'work_mem' in configs: work_mem = configs['work_mem']['setting'] if work_mem.endswith('kB'): kb_value = int(work_mem[:-2]) if kb_value < 4096: # 小于4MB issues.append('work_mem设置可能过小') recommendations.append('适当增加work_mem以减少临时文件使用') # 检查checkpoint配置 if 'checkpoint_timeout' in configs: checkpoint_timeout = int(configs['checkpoint_timeout']['setting']) if checkpoint_timeout > 900: # 超过15分钟 issues.append('checkpoint_timeout设置过长') recommendations.append('考虑减少checkpoint_timeout以降低恢复时间') if issues: analysis['score'] -= len(issues) * 10 for issue in issues: analysis['issues'].append({ 'severity': 'MEDIUM', 'message': issue }) for rec in recommendations: analysis['recommendations'].append({ 'priority': 3, 'action': rec }) except Exception as e: logger.error(f"配置分析失败: {e}") analysis['score'] = 0 return analysis def generate_optimization_report(self) -> Dict[str, Any]: """ 生成优化报告 Returns: 优化报告 """ health_report = self.analyze_database_health() report = { 'summary': { 'overall_score': health_report['overall_score'], 'assessment': self._get_assessment(health_report['overall_score']), 'total_issues': len(health_report['issues']), 'total_recommendations': len(health_report['recommendations']) }, 'detailed_analysis': health_report['categories'], 'critical_issues': [ issue for issue in health_report['issues'] if issue.get('severity') in ['CRITICAL', 'HIGH'] ], 'optimization_plan': self._create_optimization_plan(health_report), 'execution_checklist': self._create_execution_checklist() } return report def _get_assessment(self, score: float) -> str: """根据评分获取评估结果""" if score >= 90: return 'EXCELLENT' elif score >= 80: return 'GOOD' elif score >= 70: return 'FAIR' elif score >= 60: return 'NEEDS_IMPROVEMENT' else: return 'POOR' def _create_optimization_plan(self, health_report: Dict[str, Any]) -> List[Dict[str, Any]]: """创建优化计划""" plan = [] # 按优先级排序建议 sorted_recommendations = sorted( health_report['recommendations'], key=lambda x: x.get('priority', 3) ) for i, rec in enumerate(sorted_recommendations[:10], 1): # 取前10个 plan.append({ 'step': i, 'action': rec['action'], 'priority': rec.get('priority', 3), 'estimated_effort': self._estimate_effort(rec['action']), 'expected_impact': self._estimate_impact(rec['action']) }) return plan def _estimate_effort(self, action: str) -> str: """估计实施难度""" low_effort_keywords = ['调整', '设置', '启用', '禁用'] medium_effort_keywords = ['优化', '重构', '重建', '迁移'] high_effort_keywords = ['重写', '重构架构', '数据迁移', '集群扩展'] action_lower = action.lower() if any(keyword in action_lower for keyword in high_effort_keywords): return 'HIGH' elif any(keyword in action_lower for keyword in medium_effort_keywords): return 'MEDIUM' else: return 'LOW' def _estimate_impact(self, action: str) -> str: """估计影响程度""" high_impact_keywords = ['性能提升', '显著改善', '根本解决', '关键修复'] medium_impact_keywords = ['优化', '改进', '增强', '调整'] low_impact_keywords = ['微调', '小优化', '维护', '清理'] action_lower = action.lower() if any(keyword in action_lower for keyword in high_impact_keywords): return 'HIGH' elif any(keyword in action_lower for keyword in medium_impact_keywords): return 'MEDIUM' else: return 'LOW' def _create_execution_checklist(self) -> List[Dict[str, Any]]: """创建执行检查清单""" checklist = [ { 'phase': '准备阶段', 'tasks': [ {'task': '备份数据库', 'completed': False}, {'task': '验证备份完整性', 'completed': False}, {'task': '准备回滚计划', 'completed': False}, {'task': '安排维护窗口', 'completed': False} ] }, { 'phase': '实施阶段', 'tasks': [ {'task': '应用配置变更', 'completed': False}, {'task': '执行索引优化', 'completed': False}, {'task': '运行VACUUM操作', 'completed': False}, {'task': '更新统计信息', 'completed': False} ] }, { 'phase': '验证阶段', 'tasks': [ {'task': '验证性能改进', 'completed': False}, {'task': '运行回归测试', 'completed': False}, {'task': '监控系统稳定性', 'completed': False}, {'task': '更新文档记录', 'completed': False} ] } ] return checklist def close(self): """关闭连接""" if self.cursor: self.cursor.close() if self.conn: self.conn.close() logger.info("数据库连接已关闭")def demonstrate_optimization(): """演示优化功能""" dsn = "dbname=testdb user=postgres password=password host=localhost port=5432" print("PostgreSQL高级优化演示") print("=" * 60) optimizer = PostgreSQLAdvancedOptimizer(dsn) try: # 生成健康报告 print("n生成数据库健康报告...") health_report = optimizer.analyze_database_health() print(f"n总体评分: {health_report['overall_score']:.1f}/100") print(f"发现问题: {len(health_report['issues'])} 个") print(f"优化建议: {len(health_report['recommendations'])} 条") # 显示关键问题 critical_issues = [ issue for issue in health_report['issues'] if issue.get('severity') in ['CRITICAL', 'HIGH'] ] if critical_issues: print("n关键问题:") for issue in critical_issues[:3]: print(f" • [{issue['severity']}] {issue['message']}") # 显示高优先级建议 high_priority_recs = [ rec for rec in health_report['recommendations'] if rec.get('priority', 3) == 1 ] if high_priority_recs: print("n高优先级建议:") for rec in high_priority_recs[:3]: print(f" • {rec['action']}") # 生成详细报告 print("nn生成详细优化报告...") report = optimizer.generate_optimization_report() print(f"n优化计划 ({len(report['optimization_plan'])} 个步骤):") for step in report['optimization_plan'][:5]: print(f" 步骤{step['step']}: {step['action']}") print(f" 优先级: {step['priority']}, 难度: {step['estimated_effort']}, " f"影响: {step['expected_impact']}") print("n执行检查清单:") for phase in report['execution_checklist']: print(f" {phase['phase']}:") for task in phase['tasks']: status = '✓' if task['completed'] else '○' print(f" {status} {task['task']}") print("n优化演示完成!") except Exception as e: print(f"演示过程中出错: {e}") finally: optimizer.close()if __name__ == "__main__": demonstrate_optimization()7. 代码自查与最佳实践
7.1 代码质量检查清单
为确保PostgreSQL相关代码的质量,应遵循以下检查清单:
"""PostgreSQL代码质量自查工具"""import reimport astfrom typing import List, Dict, Any, Setimport logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)class PostgreSQLCodeChecker: """PostgreSQL代码质量检查器""" def __init__(self): self.rules = { 'sql_injection': self.check_sql_injection, 'connection_management': self.check_connection_management, 'transaction_handling': self.check_transaction_handling, 'index_usage': self.check_index_usage, 'data_type_validation': self.check_data_type_validation, 'error_handling': self.check_error_handling, 'performance_anti_patterns': self.check_performance_anti_patterns } def check_file(self, filepath: str) -> Dict[str, List[Dict[str, Any]]]: """ 检查Python文件中的PostgreSQL相关代码 Args: filepath: Python文件路径 Returns: 检查结果 """ with open(filepath, 'r', encoding='utf-8') as f: content = f.read() issues = {} for rule_name, rule_func in self.rules.items(): rule_issues = rule_func(content, filepath) if rule_issues: issues[rule_name] = rule_issues return issues def check_sql_injection(self, content: str, filepath: str) -> List[Dict[str, Any]]: """ 检查SQL注入漏洞 Args: content: 文件内容 filepath: 文件路径 Returns: 问题列表 """ issues = [] # 查找可能的字符串拼接SQL patterns = [ (r'executes*(.*?s*%s*.*?)', '使用字符串格式化执行SQL'), (r'executes*(.*?s*+s*.*?)', '使用字符串拼接执行SQL'), (r'executemanys*(.*?s*%s*.*?)', '使用字符串格式化执行批量SQL'), (r'f"SELECT.*{.*}.*"', '使用f-string直接嵌入变量'), ] lines = content.split('n') for i, line in enumerate(lines, 1): for pattern, description in patterns: if re.search(pattern, line, re.IGNORECASE): issues.append({ 'line': i, 'severity': 'CRITICAL', 'message': f'潜在的SQL注入漏洞: {description}', 'suggestion': '使用参数化查询(%s占位符)', 'code_snippet': line.strip()[:100] }) return issues def check_connection_management(self, content: str, filepath: str) -> List[Dict[str, Any]]: """ 检查数据库连接管理 Args: content: 文件内容 filepath: 文件路径 Returns: 问题列表 """ issues = [] lines = content.split('n') # 查找连接创建但不关闭的情况 connect_pattern = r'psycopg2.connect(|connect(' close_pattern = r'.close()' in_function = False function_start = 0 connect_lines = [] for i, line in enumerate(lines, 1): # 检测函数开始 if line.strip().startswith('def '): in_function = True function_start = i connect_lines = [] # 检测连接创建 if re.search(connect_pattern, line): connect_lines.append(i) # 检测连接关闭 if re.search(close_pattern, line) and 'close' in line: if connect_lines: connect_lines.pop() # 检测函数结束 if line.strip() == '' or i == len(lines): if in_function and connect_lines: for connect_line in connect_lines: issues.append({ 'line': connect_line, 'severity': 'HIGH', 'message': '数据库连接可能未正确关闭', 'suggestion': '确保在finally块中关闭连接', 'context': f'函数开始于第{function_start}行' }) in_function = False return issues def check_transaction_handling(self, content: str, filepath: str) -> List[Dict[str, Any]]: """ 检查事务处理 Args: content: 文件内容 filepath: 文件路径 Returns: 问题列表 """ issues = [] lines = content.split('n') # 查找没有明确事务管理的操作 write_operations = [ 'INSERT', 'UPDATE', 'DELETE', 'CREATE', 'ALTER', 'DROP' ] transaction_keywords = [ 'BEGIN', 'COMMIT', 'ROLLBACK', 'autocommit', 'set_session', 'transaction' ] in_write_operation = False has_transaction_control = False for i, line in enumerate(lines, 1): line_upper = line.upper() # 检查是否有写操作 if any(op in line_upper for op in write_operations): in_write_operation = True # 检查是否有事务控制 if any(keyword in line for keyword in transaction_keywords): has_transaction_control = True # 如果是空行或注释,检查之前的操作 if line.strip() == '' or line.strip().startswith('#'): if in_write_operation and not has_transaction_control: issues.append({ 'line': i - 1, 'severity': 'MEDIUM', 'message': '写操作没有显式的事务管理', 'suggestion': '使用明确的事务控制(BEGIN/COMMIT/ROLLBACK)', 'context': '多个写操作应该在同一事务中' }) in_write_operation = False has_transaction_control = False return issues def check_index_usage(self, content: str, filepath: str) -> List[Dict[str, Any]]: """ 检查索引使用 Args: content: 文件内容 filepath: 文件路径 Returns: 问题列表 """ issues = [] lines = content.split('n') # 查找可能受益于索引的查询模式 index_patterns = [ (r'WHEREs+w+s*=s*', '等值查询'), (r'WHEREs+w+s+INs*(', 'IN列表查询'), (r'WHEREs+w+s+LIKEs+'', 'LIKE查询(可能前缀匹配)'), (r'ORDERs+BYs+w+', '排序操作'), (r'GROUPs+BYs+w+', '分组操作'), (r'JOINs+w+s+ONs+w+s*=s*w+', '连接操作') ] for i, line in enumerate(lines, 1): line_upper = line.upper() # 跳过注释 if line.strip().startswith('#'): continue for pattern, description in index_patterns: if re.search(pattern, line_upper, re.IGNORECASE): issues.append({ 'line': i, 'severity': 'LOW', 'message': f'查询可能受益于索引: {description}', 'suggestion': '考虑在相关列上创建索引', 'code_snippet': line.strip()[:100] }) break return issues def generate_report(self, issues: Dict[str, List[Dict[str, Any]]]) -> str: """生成检查报告""" report_lines = [] report_lines.append("=" * 60) report_lines.append("PostgreSQL代码质量检查报告") report_lines.append("=" * 60) total_issues = sum(len(rule_issues) for rule_issues in issues.values()) report_lines.append(f"n总共发现 {total_issues} 个问题n") severity_counts = {'CRITICAL': 0, 'HIGH': 0, 'MEDIUM': 0, 'LOW': 0} for rule_name, rule_issues in issues.items(): if rule_issues: report_lines.append(f"n{rule_name.upper()} ({len(rule_issues)}个问题):") report_lines.append("-" * 40) for issue in rule_issues: severity = issue.get('severity', 'UNKNOWN') severity_counts[severity] = severity_counts.get(severity, 0) + 1 report_lines.append( f"[{severity}] 第{issue['line']}行: {issue['message']}" ) if 'suggestion' in issue: report_lines.append(f" 建议: {issue['suggestion']}") if 'code_snippet' in issue: report_lines.append(f" 代码: {issue['code_snippet']}") report_lines.append("") # 添加严重性统计 report_lines.append("n严重性统计:") report_lines.append("-" * 40) for severity, count in severity_counts.items(): if count > 0: report_lines.append(f" {severity}: {count} 个问题") return 'n'.join(report_lines)def check_postgresql_best_practices(): """PostgreSQL最佳实践检查示例""" checker = PostgreSQLCodeChecker() # 示例代码 sample_code = """import psycopg2# 不好的示例:字符串拼接SQL(SQL注入风险)def bad_example(user_input): conn = psycopg2.connect("dbname=test") cursor = conn.cursor() # SQL注入漏洞 query = f"SELECT * FROM users WHERE username = '{user_input}'" cursor.execute(query) # 连接未关闭 return cursor.fetchall()# 好的示例:参数化查询def good_example(username): conn = None cursor = None try: conn = psycopg2.connect("dbname=test") cursor = conn.cursor() # 参数化查询 query = "SELECT * FROM users WHERE username = %s" cursor.execute(query, (username,)) return cursor.fetchall() finally: if cursor: cursor.close() if conn: conn.close()# 事务处理示例def transaction_example(user_data): conn = psycopg2.connect("dbname=test") cursor = conn.cursor() try: # 开始事务 conn.autocommit = False # 多个写操作 cursor.execute( "INSERT INTO users (name, email) VALUES (%s, %s)", (user_data['name'], user_data['email']) ) cursor.execute( "INSERT INTO logs (action) VALUES (%s)", ('user_created',) ) # 提交事务 conn.commit() except Exception as e: # 回滚事务 conn.rollback() raise e finally: cursor.close() conn.close()# 可能受益于索引的查询def query_without_index(): conn = psycopg2.connect("dbname=test") cursor = conn.cursor() # 这个查询可能受益于索引 cursor.execute(""" SELECT * FROM orders WHERE customer_id = %s AND order_date > %s ORDER BY order_date DESC """, (123, '2024-01-01')) return cursor.fetchall() """ # 将示例代码写入临时文件 import tempfile with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as f: f.write(sample_code) temp_file = f.name try: # 检查代码 issues = checker.check_file(temp_file) report = checker.generate_report(issues) print(report) finally: import os os.unlink(temp_file)if __name__ == "__main__": check_postgresql_best_practices()7.2 PostgreSQL最佳实践总结
连接管理最佳实践:
- 使用连接池管理数据库连接
- 确保连接在finally块中正确关闭
- 设置合适的连接超时和重试策略
查询优化最佳实践:
- 使用EXPLAIN ANALYZE分析查询计划
- 为频繁查询的列创建合适索引
- 避免SELECT *,只选择需要的列
- 使用LIMIT限制返回行数
事务管理最佳实践:
- 保持事务尽可能短小
- 使用合适的隔离级别
- 处理异常并正确回滚
- 避免长时间持有锁
索引设计最佳实践:
- 基于查询模式设计复合索引
- 定期分析和重建索引
- 使用部分索引减少索引大小
- 考虑BRIN索引用于时间序列数据
配置优化最佳实践:
- 根据工作负载调整shared_buffers
- 设置合适的work_mem减少临时文件
- 配置有效的维护工作内存
- 定期更新统计信息
8. 总结与展望
PostgreSQL作为功能最丰富的开源数据库,其高级特性和性能优化能力使其能够应对各种复杂的应用场景。通过本文的深入探讨,我们了解到:
8.1 核心要点总结
- 高级特性:JSONB、全文搜索、分区表、物化视图等特性使PostgreSQL能够处理多样化数据需求
- 性能优化:合理的索引设计、查询优化、配置调整是提升性能的关键
- 并发控制:MVCC机制和适当的锁策略确保高并发下的数据一致性
- 监控维护:系统化监控和定期维护保证数据库长期稳定运行
8.2 未来发展趋势
- 人工智能集成:PostgreSQL的MADlib扩展支持机器学习算法
- 时序数据优化:TimescaleDB扩展提供专业时序数据处理能力
- 地理空间增强:PostGIS继续扩展地理信息系统功能
- 云原生支持:更好的Kubernetes集成和云服务优化
- 向量搜索:对AI生成内容(AIGC)的向量相似度搜索支持
通过持续学习和实践,开发者可以充分利用PostgreSQL的强大功能,构建高效、稳定、可扩展的数据存储解决方案。无论是对初创公司还是大型企业,PostgreSQL都提供了企业级数据库所需的一切功能,同时保持了开源软件的灵活性和成本优势。
以上就是PostgreSQL高级特性与性能优化的实战指南的详细内容,更多关于PostgreSQL性能优化的资料请关注本站其它相关文章!