MySQL库与表的全面操作指南
前言:
作为 C++ 开发者,我们在编写高性能后端服务时,不可避免地要与底层存储打交道。MySQL 作为主流的关系型数据库,其基础的“库操作”与“表操作”是每一位程序员的看家本领。今天博主将结合底层原理,带大家一次性吃透 MySQL 库与表的核心操纵技巧。
一、 数据库(Database)操作深度解析
数据库是表的载体。理解数据库的字符集与校验规则,是避免中文乱码和检索异常的关键。
1.1 创建数据库
创建数据库的标准语法如下:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification]...];
其中,
create_specification
? 实战案例
默认创建(系统默认采用
utf8
字符集,校验规则为
utf8_general_ci
CREATE DATABASE db1;
指定 utf8 字符集:
CREATE DATABASE db2 CHARSET=utf8;
同时指定字符集与校验规则:
CREATE DATABASE db3 CHARSET=utf8 COLLATE utf8_general_ci;
1.2 校验规则的“深水区”:区分大小写的影响
字符集决定了存储哪些语言,而校验规则(Collation)决定了如何对字符进行比较和排序。
MySQL 中常见的两种
utf8
校验规则:
utf8_general_ci:不区分大小写(Case-Insensitive)。utf8_bin:区分大小写(Binary,按二进制比对)。
实验对比:
数据库 | 校验规则 | 插入数据 | 查询 where name='a' 的结果 | order by name 排序结果 |
|---|---|---|---|---|
test1 | utf8_general_ci | a, A, b, B | 返回 a 和 A (共2行) | a -> A -> b -> B |
test2 | utf8_bin | a, A, b, B | 仅返回 a (共1行) | A -> B -> a -> b (大写在前) |
博主敲黑板:在设计用户登录、唯一标识等字段时,一定要根据业务逻辑选对校验规则。如果需要密码或账号严格区分大小写,请务必使用
_bin结尾的二进制校验规则!
1.3 数据库日常维护指令
查看系统默认字符集与校验规则:
SHOW VARIABLES LIKE 'character_set_database';SHOW VARIABLES LIKE 'collation_database';
查看系统支持的所有字符集及校验规则:
SHOW CHARSET;SHOW COLLATION;
1.3.1 查看所有数据库
SHOW DATABASES;
1.3.2 查看数据库创建语句
验证数据库的字符集、校验规则等配置:
SHOW CREATE DATABASE mytest;
注:返回的语句中,数据库名会被加上反引号 ` ,这是为了防止数据库名与系统保留关键字冲突;同时形如
/*!40100 DEFAULT ... */的代码并不是普通的注释,而是条件注释,表示当 MySQL 版本大于 4.01 时将执行该语句。
1.3.3 修改数据库(仅字符集和校验规则)
数据库创建后,仅支持修改字符集和校验规则,不支持修改库名(需通过备份恢复间接修改):
ALTER DATABASE mytest CHARSET=gbk;
1.3.4 删除数据库(谨慎操作!)
删除数据库会级联删除所有表和数据,且无法恢复:
DROP DATABASE [IF EXISTS] db_name;
⚠️ 极其重要提示:数据库删除是级联删除,里面的所有数据表和数据都会被一并抹除。千万不要在生产环境下轻易尝试!
1.4 数据库备份与还原(核心运维技能)
在退出 MySQL 连接的终端下,我们可以使用
mysqldump
进行备份。
1.4.1 备份整个数据库
# 注意 -B 参数会带上创建数据库的语句mysqldump -P3306 -u root -p密码 -B 数据库名 > 备份存储的路径.sql# 示例:mysqldump -P3306 -u root -p123456 -B mytest > D:/mytest.sql
1.4.2 还原数据库
进入 MySQL 客户端后,执行
source
指令:
mysql> SOURCE D:/mytest.sql;
1.4.3 进阶备份场景
仅备份数据库中的特定表:
mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql
同时备份多个数据库:
mysqldump -u root -p -B 数据库名1 数据库名2... > D:/multi_db.sql
避坑指南:如果备份时没有带
-B
CREATE DATABASE
USE 数据库名
SOURCE
还原!
1.5 数据库监控:查看连接情况
当你发现数据库响应变慢,或者怀疑遭遇外部恶意连接时,可以使用以下命令:
SHOW PROCESSLIST;
输出样例:
+----+------+-----------+------+---------+------+-------+------------------+| Id | User | Host | db | Command | Time | State | Info |+----+------+-----------+------+---------+------+-------+------------------+| 2 | root | localhost | test1| Sleep | 120 | | NULL || 3 | root | localhost | NULL | Query | 0 | NULL | show processlist |+----+------+-----------+------+---------+------+-------+------------------+
该命令可以实时显示当前有哪些用户连接到了 MySQL,以及他们正在执行的命令、所处的状态和消耗的时间。
二、 数据表(Table)操作全攻关
学完了库,我们来啃最硬的骨头——表结构的操作。
2.1 创建数据表
标准语法:
CREATE TABLE table_name ( field1 datatype, field2 datatype, ...) CHARACTER SET 字符集 COLLATE 校验规则 ENGINE 存储引擎;
?️ 实战演练:
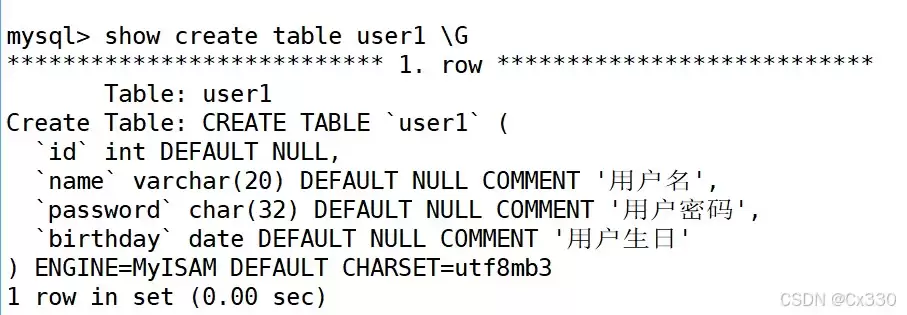
CREATE TABLE users ( id INT, name VARCHAR(20) COMMENT '用户名', password CHAR(32) COMMENT '密码是32位的md5值', birthday DATE COMMENT '生日') CHARACTER SET utf8 ENGINE MyISAM;
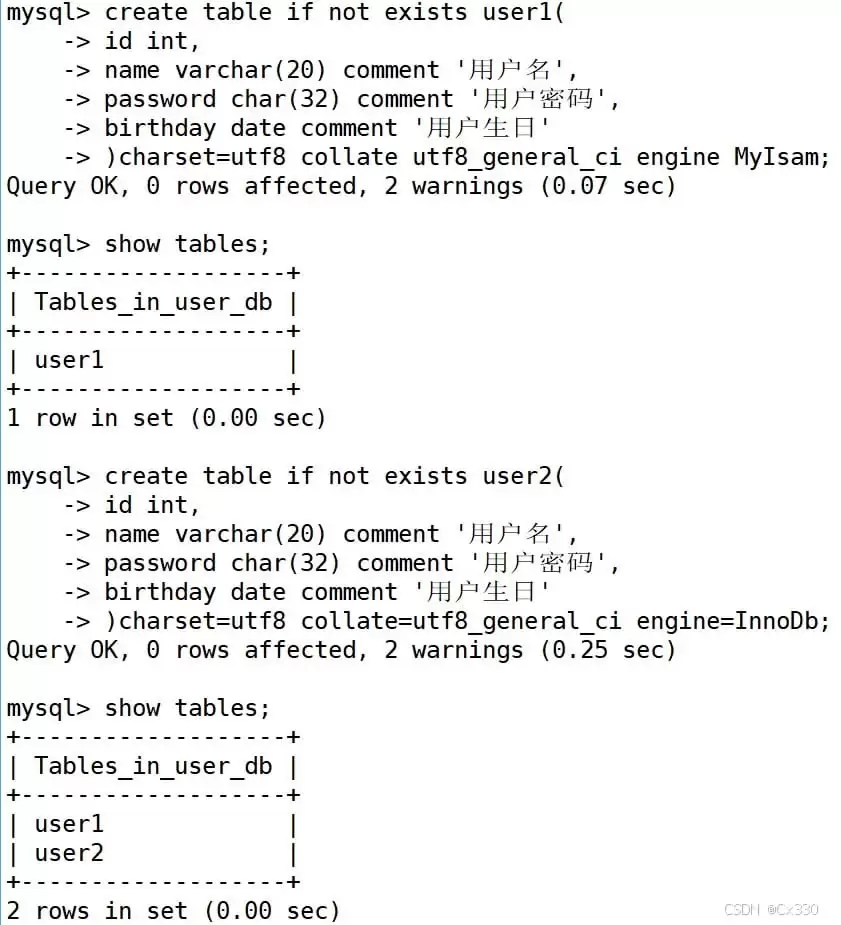
? 底层探秘:不同的存储引擎,物理文件大不相同!
当我们创建了上面的
user1
表(引擎为
MyISAM
InnoDB
引擎的表时,切换到 MySQL 的数据目录下,你会发现:
- MyISAM 引擎的表会生成三个文件:
user1.frm:表结构定义user1.MYD:表数据(Data)user1.MYI:表索引(Index)
- InnoDB 引擎的表会生成两个文件:
user2.frm:表结构定义user2.ibd:表数据与索引合并存储的文件
2.2 查看表结构
使用
desc
或者是
describe
命令可以快速查看表的字段属性:
DESC users;
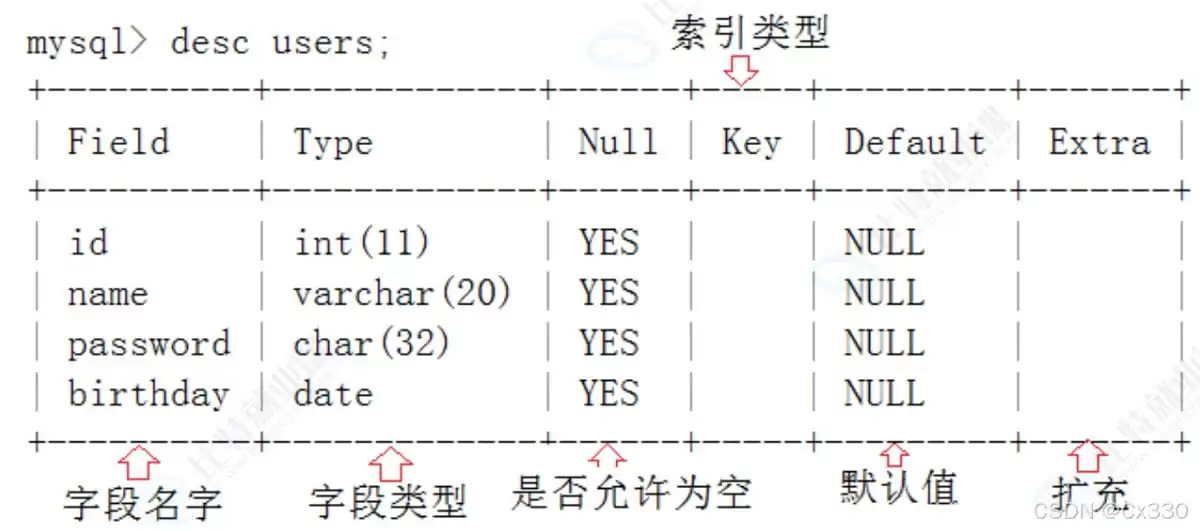
输出字段包括:
Field
(字段名)、
Type
(类型)、
Null
(是否允许为空)、
Key
(索引类型)、
Default
(默认值)、
Extra
(扩充属性)。

2.3 动态修改表结构(DDL 操作)
在实际项目迭代中,需求的变更往往伴随着表结构的调整。以下是高频使用的
ALTER TABLE
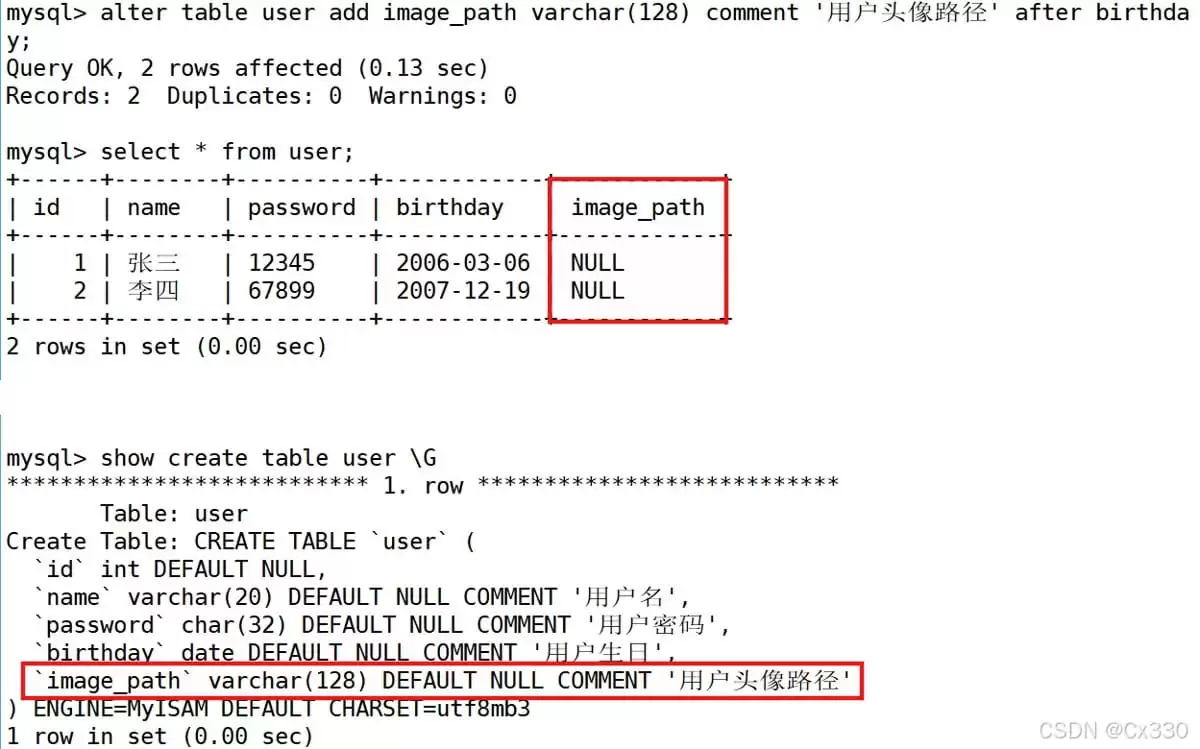
1. 添加新字段(ADD)
在
birthday
字段后面添加一个名为
image_path
的图片路径字段:ALTER TABLE users ADD image_path VARCHAR(100) COMMENT '图片路径' AFTER birthday;
注意:插入新字段后,原来表中已有的历史数据的该字段值会自动填充为
NULL。
2. 修改字段属性(MODIFY)
将
name
字段的长度从 20 扩展到 60:
ALTER TABLE users MODIFY name VARCHAR(60);
3. 删除字段(DROP)
⚠️ 注意:删除字段会同时将该列对应的所有历史数据删除,请谨慎操作!
ALTER TABLE users DROP password;
4. 修改表名(RENAME)
将
users
表改名为
xingming
(TO 关键字可以省略):ALTER TABLE users RENAME TO employee;
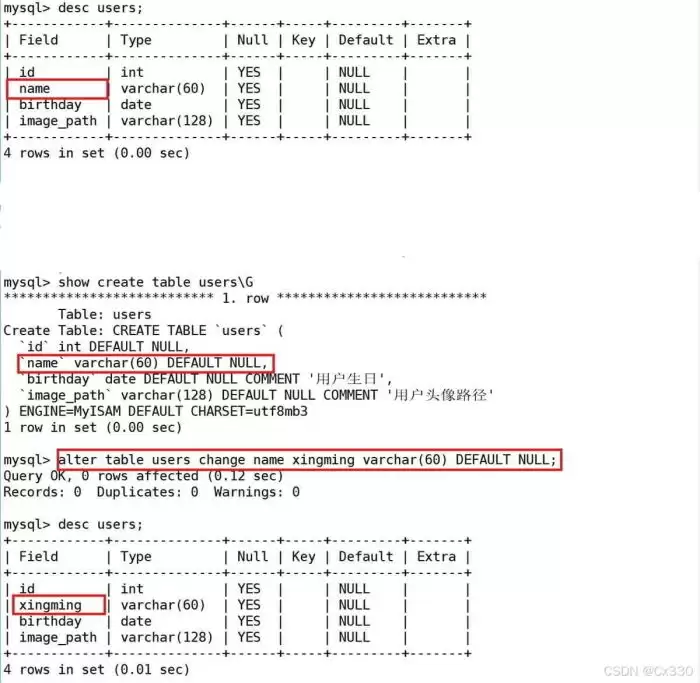
5. 修改字段名与定义(CHANGE)
如果要将
name
列的名字修改为
xingming
ALTER TABLE employee CHANGE name xingming VARCHAR(60);
2.4 删除数据表
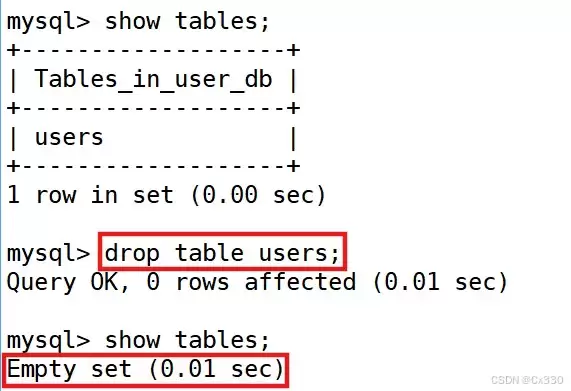
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name;
示例:
DROP TABLE IF EXISTS t1;
? 结语
掌握了 MySQL 库与表的基本功,我们就拿到了通往高并发、分布式后端开发的第一张入场券。规范的 SQL 编写习惯与合理的引擎、字符集选择,能够帮助我们在项目初期避开 90% 的底层性能和乱码深坑。