Oracle BLOB 实时同步为何如此艰难?一次看懂背后的5个技术挑战
合同扫描件、电子票据、业务附件、图片、影像文件……这些关键业务资料经常存储在 Oracle BLOB 字段中,实时同步到下游数仓或备库是很多企业的常见需求。
但这个看似常见的需求,挑战却比普通字段大得多。一旦同步链路处理不当,就可能出现文件损坏、内容缺失、已回滚的数据被同步出去等问题。表面上看任务还在正常运行,实际上源端和目标端的数据已经产生偏差。
那么,Oracle BLOB 实时同步到底难在哪里?下面先看一个典型场景,再逐一拆解背后的 5 个技术挑战。
一个典型场景
我们先看一个很容易在项目里遇到的场景。
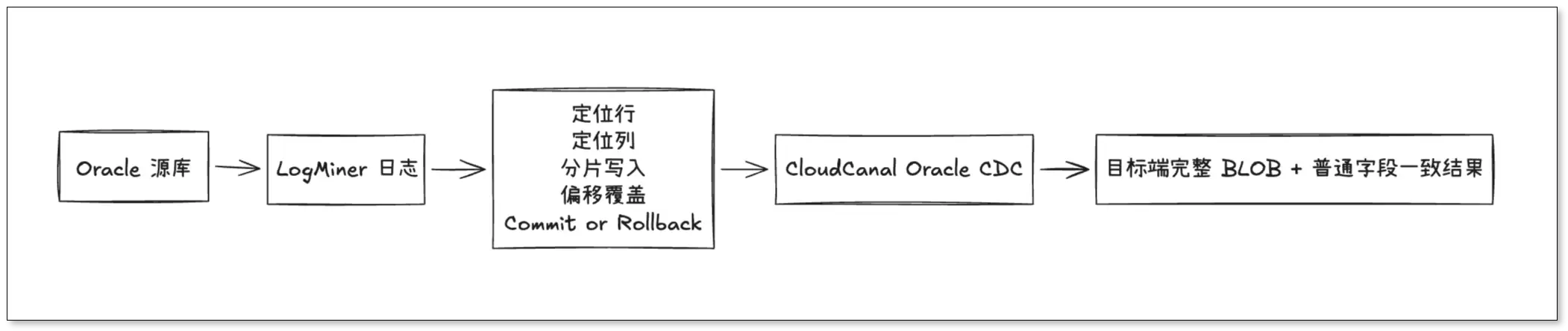
假设某企业将合同原件、票据影像和审批附件存储在 Oracle BLOB 字段中。用户上传一份新的合同文件后,系统会在同一个事务内更新合同附件内容、修改合同状态、写入审批信息,甚至同时更新多个 BLOB 字段。对业务系统来说,这只是一次普通提交。
但在 Oracle 日志中,这些变更并不会天然表现为一条完整的 UPDATE。对于 BLOB 字段,LogMiner 中通常会出现定位目标行、定位目标列、写入数据片段、按偏移位置覆盖、提交或回滚等多个离散事件。
如果同步系统只把日志事件简单搬到下游,就可能出现:合同状态同步成功,但附件内容缺失;A 字段的片段写到了 B 字段;或者业务事务已经回滚,目标端却留下了一份无效附件。
这也是 Oracle BLOB 实时同步最容易踩坑的地方:问题不是任务能不能跑,而是目标端能不能还原源端事务提交后的真实结果。
从这个场景可以看到,难点已经不只是文件大小,而是同步系统能不能读懂日志里的事务关系、字段归属和最终结果。
为什么 BLOB 不是简单“传文件”
普通字段的增量变更通常更接近一条明确的行级变更。而 BLOB 不同,一次业务上的 BLOB 更新,在日志中可能被拆成多个步骤。
同步系统需要从这些离散日志里重新识别出:片段和事务的归属、表/行/列的上下文、写入顺序和偏移位置、事务提交或回滚状态,以及大对象处理过程中的资源占用。
所以,Oracle BLOB 增量同步考验的不是“能不能传一个文件”,而是整个 Oracle CDC 链路对日志完整性、事务语义、回滚处理和字段最终值还原的能力。
挑战一:分片写入后,如何还原完整内容
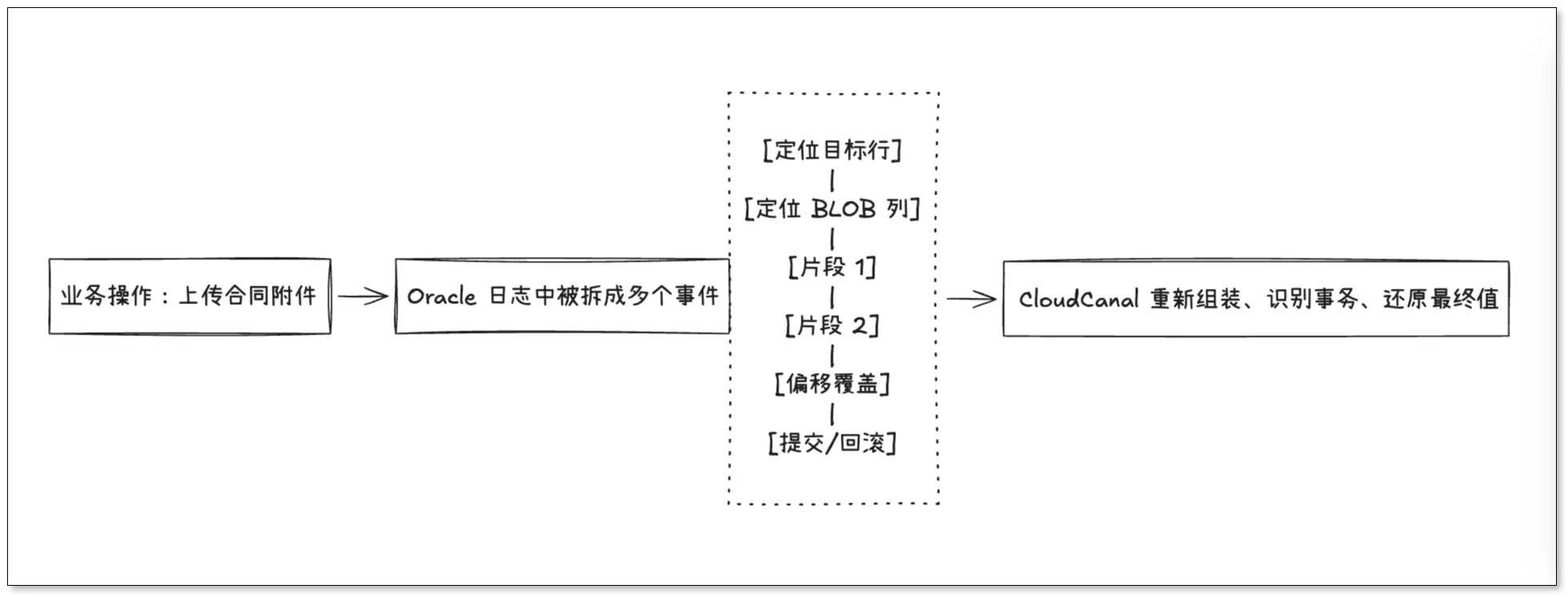
Oracle BLOB 可能会被拆成多个日志片段写入。同步系统如果漏掉某个片段,或者片段组装顺序错误,目标端得到的文件就可能无法打开,或者内容与源端不一致。
这里的关键不是简单拼接,而是要识别同一个 BLOB 对象产生的所有相关片段,并按 Oracle 日志语义完成还原。
CloudCanal 在处理 BLOB 增量变更时,会识别 BLOB 写入过程中的相关日志事件,并在事务上下文中完成片段组装,确保目标端获得的是完整内容,而不是中间状态或残缺片段。
挑战二:多列、多片段和覆盖写入,如何避免数据串扰
真实业务里,一个事务可能同时更新多个 BLOB 字段。例如合同原件、身份证扫描件、审批附件都在同一张表中,且在一次业务操作中一起更新。
这时,同一个事务下会产生多组 BLOB 日志片段。如果同步系统无法区分它们的归属,就可能发生片段混写:A 文件内容写入 B 字段,当前行的附件片段写入另一行,甚至多个 BLOB 列的片段互相覆盖。
更复杂的是,Oracle 日志中还可能出现按指定偏移位置覆盖写入的情况。也就是说,最终结果不一定是把所有片段按出现顺序拼起来,而是要符合源端 BLOB 的写入语义。
CloudCanal 会按事务、表、行和列维度维护独立的 BLOB 上下文,避免不同字段或不同行的数据片段互相干扰。同时支持按偏移位置写入,保证最终还原结果符合 Oracle BLOB 的更新语义。
挑战三:长事务跨日志窗口,如何保证上下文不丢
Oracle 实时同步通常基于 LogMiner 持续解析日志。在大型业务系统中,长事务并不少见,一个事务可能持续数分钟甚至数小时,其日志分散在多个解析窗口中。
对于普通字段,这已经会增加同步复杂度;对于高度依赖上下文的 BLOB 字段,风险会进一步放大。
一个长事务中的事务开始、BLOB 定位信息、数据写入片段、最终提交或回滚,可能分散在不同的 LogMiner 解析窗口里。如果同步链路只从上一轮读取位置继续解析,而没有保留必要上下文,就可能丢失早期定位信息,无法判断后续片段属于哪个 BLOB 列,甚至因为回滚状态识别不完整,让目标端得到错误或不完整的大对象内容。
为此,CloudCanal 对增量读取窗口和事务暂存逻辑进行了增强:在事务尚未结束时保留必要上下文,降低跨窗口丢失关键事件的风险。对于 BLOB 这种强依赖上下文的字段,这一点尤其关键。
挑战四:事务回滚后,如何避免无效数据进入下游
很多同步准确性问题并不是发生在提交阶段,而是发生在回滚阶段。
比如用户上传了一份附件,随后业务校验失败,整个事务被回滚。从 Oracle 源库的结果看,这次修改从未生效。但如果同步系统提前把 BLOB 内容写入目标端,就会造成源端和目标端状态不一致。
因此,Oracle CDC 链路必须具备完整的事务感知能力:只有确认事务真正提交后,相关 BLOB 数据才能进入下游;对于已回滚的事务,则需要及时清理对应缓存和临时资源,避免无效变更继续投递。
CloudCanal 在增量同步过程中保留事务语义,结合提交和回滚状态处理 BLOB 暂存数据,减少回滚事务带来的错误同步风险。
挑战五:大对象处理,如何兼顾准确性与稳定性
BLOB 数据通常远大于普通字段。一个字段可能是几 MB 的图片、数十 MB 的扫描件,甚至上百 MB 的业务文件。
如果同步系统把这些内容长期放在内存中处理,很容易带来内存增长、GC 压力增加,最终影响同步任务稳定性。
CloudCanal 采用文件化方式承载 BLOB 组装过程:日志片段按位置写入本地临时文件,事务提交后再交给目标端写入。
这种方式既能支持更大体量的 BLOB 数据,降低大对象对内存的压力,也能在事务回滚时清理无效临时文件,减少无效大对象占用磁盘或进入下游的风险。
也就是说,BLOB 同步不仅要还原得准,还要在长时间运行中保持稳定。
CloudCanal 增强后,对企业用户意味着什么
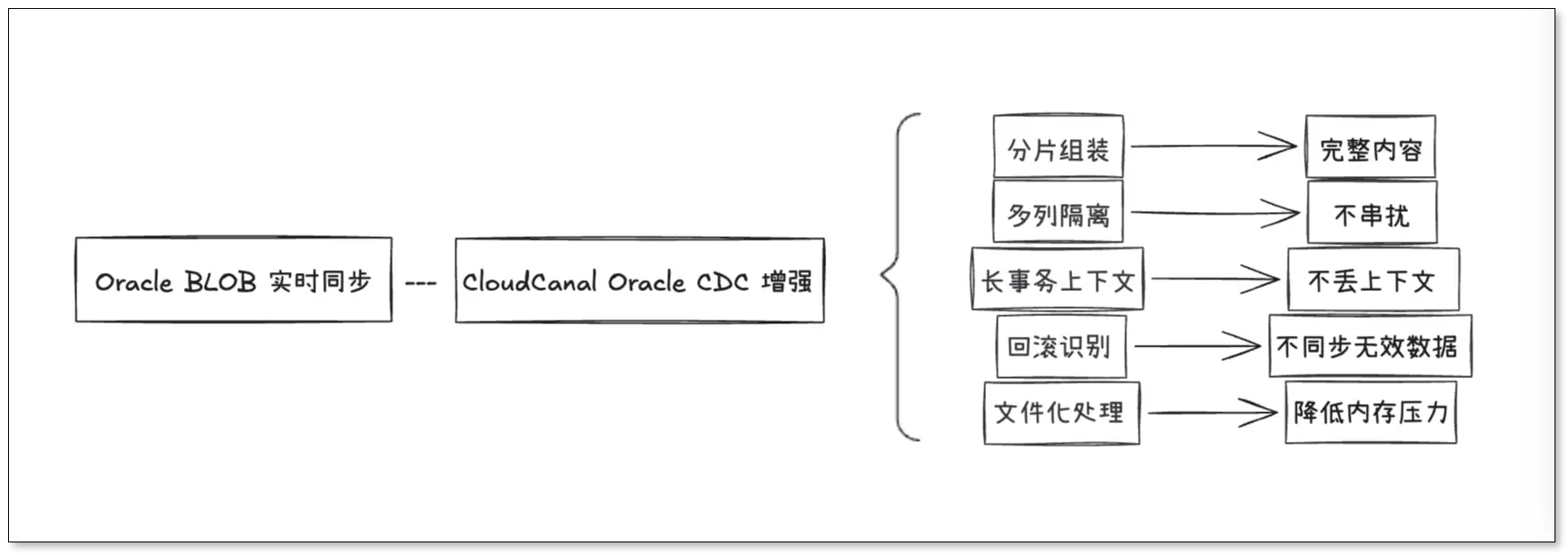
面对 Oracle BLOB 实时同步中的各种复杂场景,CloudCanal 将相关处理逻辑沉到 Oracle CDC 链路内部,能帮助业务侧少改造、少排障,并持续获得可信的数据同步结果。
不再因为 BLOB 字段而拆分同步方案
合同、附件、图片、票据、影像文件等字段可以直接纳入 Oracle 实时同步范围,减少因为字段类型限制而拆表、改字段或额外开发同步逻辑。
提升复杂场景下的数据可信度
面对分片写入、事务回滚、长事务跨窗口、多 BLOB 列同时更新等高风险路径,CloudCanal 在增量链路中保留事务语义并还原最终字段值,帮助目标端获得与 Oracle 源库提交结果一致的数据。
降低迁移、同步和灾备项目成本
在 Oracle 数据迁移、实时同步和灾备场景中,业务侧无需为 BLOB 字段单独设计绕行方案,可以沿用 CloudCanal 的标准任务配置和运行方式,降低方案复杂度和后续运维成本。
支持更稳定的大对象同步
通过文件化方式处理 BLOB 内容,CloudCanal 减少了大对象对任务内存的压力,更适合处理体量较大的二进制数据,也提升了复杂 Oracle 增量任务的长期运行稳定性。
适用场景
对于使用 Oracle 存储附件、图片、合同、票据等二进制大对象,并希望进行实时同步、数据迁移或灾备建设的企业场景,CloudCanal 可以提供更完整的大对象同步能力,例如:
- 合同、票据、图片、影像、业务附件等 BLOB 字段的实时同步。
- Oracle 向数据库、数据仓库、大数据平台等目标端的实时迁移或持续同步。
- 包含大对象字段(BLOB/CLOB)的增量同步任务。
- 对事务一致性要求较高的核心业务系统,例如金融、政务、制造等场景。
- 存在长事务、多字段同时更新或事务回滚等复杂数据变更场景。
- 希望减少业务改造和人工排除 BLOB 字段工作的数据同步项目。
总结
回到开头的问题,Oracle BLOB 实时同步难就难在:它不只是传一个文件,而是要在分片组装、多列隔离、长事务上下文、事务回滚和大对象资源控制之间,持续保证目标端结果与源端提交结果一致。
这也是 CloudCanal 持续增强 Oracle CDC 能力的重点:面对真实业务中的大字段、长事务和回滚场景,尽可能把复杂性留在同步链路内部,把可信的数据结果交给下游。
如果你正在处理 Oracle 实时同步、迁移或灾备中的 BLOB/大字段问题,欢迎在评论区留言。下一期 Oracle 专题,我们计划聊聊 Oracle DataGuard 备库同步优化,也欢迎点赞、转发或收藏这篇内容。