Feed流系统设计(四):发布与读取:核心业务流程的落地实现

写在前面
前三篇分别聊了概念、架构选型和数据模型,这一篇终于到了最实在的部分——把核心业务流程用代码实现出来。
Feed流系统说到底,最核心的就两个操作:发布和读取。发布是把消息扩散出去,读取是把消息聚合回来。这两个操作做好了,整个系统就基本能跑了。
当然,除了发布和读取,还有几个绕不开的问题要处理:Feed流怎么翻页?消息删了怎么办?非活跃用户怎么处理?这些都会在这一篇里讲到。
1. 发布Feed流程
先来看发布流程。用户发了一条动态,系统需要做哪些事情?
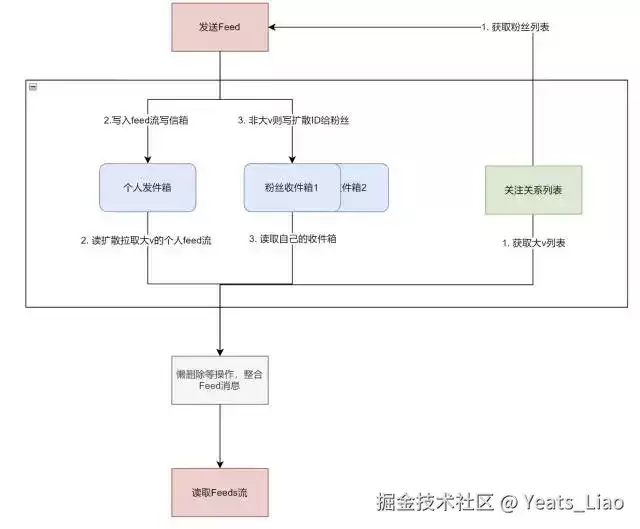
整个流程是这样的:
- 用户发布Feed消息
- 消息先进入消息队列(异步处理)
- 消费者从队列中取出消息,读取发布者的粉丝列表
- 判断发布者是否为大V
- 将消息写入发件箱(数据库)
- 根据发布者类型执行不同的扩散策略
为什么要通过消息队列异步处理?因为写扩散可能涉及大量的Redis写入操作(大V有几百万活跃粉丝),同步处理的话接口响应时间会很长,用户体验不好。异步处理可以让接口快速返回,后台慢慢做扩散。
发布服务的核心实现:
复制代码@Service
public class FeedPublishService { @Autowired
private MessageRepository messageRepository;
@Autowired
private FollowerService followerService;
@Autowired
private InboxService inboxService;
@Autowired
private UserService userService; @Async
public CompletableFuture<Void> publishFeed(long userId, FeedContent content) {
return CompletableFuture.runAsync(() -> {
try {
// 1. 创建消息记录
Message message = new Message();
message.setSenderId(userId);
message.setMsgTitle(content.getTitle());
message.setMsgContent(content.getContent());
message.setMsgType(content.getType());
message.setMsgChannel(content.getChannel()); // 2. 保存消息到数据库(发件箱)
long messageId = messageRepository.save(message); // 3. 判断用户类型
User user = userService.getUserById(userId);
boolean isInfluencer = userService.isInfluencer(user); // 4. 获取粉丝列表
List<Long> followerIds;
if (isInfluencer) {
// 大V只获取活跃粉丝
followerIds = followerService.getActiveFollowerIds(userId);
} else {
// 普通用户获取所有粉丝
followerIds = followerService.getAllFollowerIds(userId);
} // 5. 批量写入粉丝收件箱
long timestamp = System.currentTimeMillis();
for (Long followerId : followerIds) {
inboxService.addMessage(followerId, messageId, userId, timestamp);
} // 6. 更新用户发帖计数
userService.incrementPostCount(userId); } catch (Exception e) {
log.error("发布Feed失败, userId={}, error={}", userId, e.getMessage(), e);
throw e;
}
});
}
}
代码逻辑很直白,对照前面的流程图就能看懂。有几个点提一下:
批量写入可以优化。 上面的代码是用for循环逐条写入Redis的,如果粉丝量很大,可以考虑用Redis的pipeline批量操作来减少网络开销。或者把粉丝列表分批,每批用pipeline写入。
失败重试。 如果写入某个粉丝的收件箱失败了怎么办?这里有两种策略:一种是跳过失败的,记录日志,后续通过补偿机制修复;另一种是放入重试队列,反复尝试直到成功。具体选哪种取决于业务对消息必达性的要求。如果要求比较高,建议用消息队列自带的失败重试机制。
2. 读取Feed流流程
读取流程比发布流程要复杂一些,因为要处理多种情况。
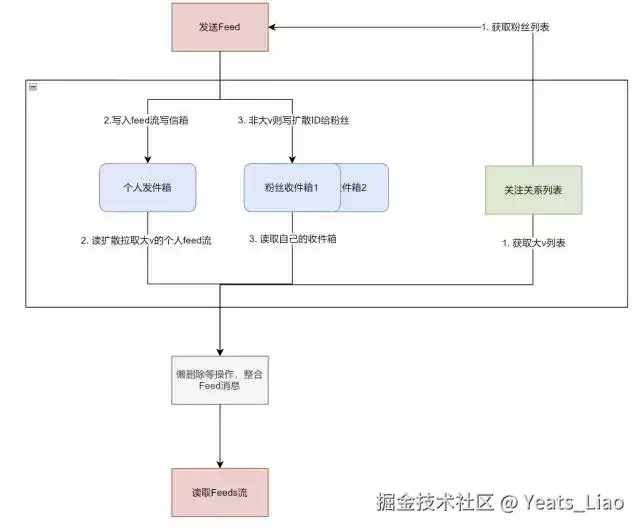
核心流程是这样的:
- 判断用户是否为活跃用户
- 从Redis收件箱中获取消息ID列表
- 如果是非活跃用户,还需要从关注的大V发件箱中拉取消息(读扩散)
- 合并结果,按时间排序
- 根据消息ID批量查询完整内容,过滤掉已删除的消息
- 返回最终结果
复制代码@Service
public class FeedQueryService { @Autowired
private InboxService inboxService;
@Autowired
private MessageRepository messageRepository;
@Autowired
private UserService userService;
@Autowired
private FollowService followService; public FeedResult getFeed(long userId, String cursor, int pageSize) {
// 1. 解析游标
FeedCursor feedCursor = cursor != null ? FeedCursor.fromString(cursor) : null; // 2. 从收件箱获取消息引用
List<MessageRef> inboxMessages = inboxService.getMessages(
userId,
feedCursor != null ? feedCursor.getLastMessageId() : null,
pageSize
); // 3. 非活跃用户需要额外查询大V发件箱
if (!userService.isActiveUser(userId)) {
List<Long> influencerIds = followService.getFollowedInfluencerIds(userId); for (Long influencerId : influencerIds) {
List<Message> influencerMessages = messageRepository.getRecentMessages(
influencerId,
feedCursor != null ? feedCursor.getLastTimestamp() : null,
pageSize
);
inboxMessages.addAll(convertToMessageRefs(influencerMessages, influencerId));
} // 按时间排序
inboxMessages.sort((a, b) -> Double.compare(b.getTimestamp(), a.getTimestamp())); // 限制结果数量
if (inboxMessages.size() > pageSize) {
inboxMessages = inboxMessages.subList(0, pageSize);
}
} // 4. 批量获取消息内容并过滤已删除消息
List<Message> messages = getMessagesWithLazyDelete(userId, inboxMessages); // 5. 构建Feed项(包含消息内容和发布者信息)
List<FeedItem> feedItems = buildFeedItems(messages); // 6. 生成下一页游标
String nextCursor = null;
if (!feedItems.isEmpty()) {
FeedItem lastItem = feedItems.get(feedItems.size() - 1);
nextCursor = new FeedCursor(lastItem.getMessageId(), lastItem.getTimestamp()).toString();
} return new FeedResult(feedItems, nextCursor);
}
}
这段代码里有一个关键的设计决策:非活跃用户在读取Feed流的时候,除了从自己的收件箱读取,还要额外去关注的大V发件箱里拉取消息。这就是读写结合中"读扩散"的部分——因为大V发布消息时没有给冷粉丝做写扩散,所以冷粉丝需要自己来拉。
这里有个性能问题需要注意:如果用户关注了10个大V,那就要发起10次数据库查询。可以用并发的方式同时查询多个大V的发件箱,减少总等待时间。
3. Feed流的翻页方案
Feed流的翻页是一个很容易被忽视但非常关键的问题。
传统的分页方式是用page_num和page_size——第1页、第2页、第3页。这种方式在静态数据列表中没问题,但在Feed流中会出大问题。
为什么?因为Feed流是动态的。用户在看第1页的时候,可能有人发了新消息,这些新消息会被插入到Feed流的顶部。等用户翻到第2页的时候,由于顶部插入了新内容,原来的第2页实际上已经变成了第3页——用户会看到重复的内容,或者跳过一些内容。
这就是所谓的"错位问题"。
解决这个问题的标准方案是基于游标的分页(cursor-based pagination)。不用页码,而是用上一页最后一条消息的ID(或者ID+时间戳的组合)作为游标,下一页从这个游标之后开始取数据。
复制代码@RestController
@RequestMapping("/feed")
public class FeedController { @Autowired
private FeedService feedService; @GetMapping
public ResponseEntity<List<FeedItem>> getFeed(
@RequestParam(required = false) String cursor,
@RequestParam(defaultValue = "20") int size) { FeedResult result = feedService.getFeed(getCurrentUserId(), cursor, size); HttpHeaders headers = new HttpHeaders();
if (result.getNextCursor() != null) {
headers.add("X-Next-Cursor", result.getNextCursor());
} return new ResponseEntity<>(result.getItems(), headers, HttpStatus.OK);
}
}
游标的设计一般包含两个信息:上一页最后一条消息的ID和时间戳。
复制代码public class FeedCursor {
private long lastMessageId;
private long lastTimestamp; // 将游标编码为字符串,传给前端
public String toString() {
return Base64.getEncoder().encodeToString(
String.format("%d:%d", lastMessageId, lastTimestamp).getBytes()
);
} // 从前端传来的字符串解析出游标
public static FeedCursor fromString(String cursor) {
String decoded = new String(Base64.getDecoder().decode(cursor));
String[] parts = decoded.split(":");
return new FeedCursor(Long.parseLong(parts[0]), Long.parseLong(parts[1]));
}
}
用Base64编码是为了让游标对前端透明——前端不需要知道游标的内部结构,只需要在请求下一页的时候把上一次响应中返回的游标原样传回来就行。
基于游标的分页有一个前提条件:数据不能被物理删除。因为游标是基于消息ID定位的,如果这条消息被删了,系统就找不到对应的记录了。这也是为什么我们采用软删除——消息不会被真的删掉,只是标记为已删除状态。
4. 软删除与懒删除
上一篇提到过,收件箱里存的是消息ID的引用,完整内容需要回查数据库获取。这个设计天然支持了消息的修改同步——回查的时候拿到的就是最新版本。但删除的场景需要额外处理。
当发布者删除了一条消息,他的粉丝收件箱里还留着这条消息的引用。粉丝读取Feed流的时候,回查数据库发现这条消息的msg_status已经是0(已删除)了,需要把它过滤掉。
但这里有个问题:过滤掉之后,这一页返回的消息数量就不够pageSize了。比如用户请求20条,过滤掉了3条已删除的,实际只返回了17条。怎么办?
两种处理方式:
- 接受不足pageSize的结果,前端继续翻页时自然能拿到更多数据
- 自动补充查询,从收件箱中多取几条来填补被过滤掉的位置
第一种方式实现简单,但用户体验稍差(每页可能不满)。第二种方式体验更好,但实现稍复杂。建议采用第二种,具体做法是:每次从收件箱多取一些(比如取pageSize + 预估删除率),过滤后再截取pageSize条返回。
复制代码public List<Message> getMessagesWithLazyDelete(long userId, List<MessageRef> messageRefs) {
// 1. 批量获取消息内容
List<Long> messageIds = messageRefs.stream()
.map(MessageRef::getMessageId)
.collect(Collectors.toList());
List<Message> messages = messageRepository.findByIds(messageIds); // 2. 过滤已删除消息
List<Message> validMessages = messages.stream()
.filter(msg -> msg.getMsgStatus() == MessageStatus.NORMAL.getValue())
.collect(Collectors.toList()); // 3. 懒删除 - 异步清理收件箱中的无效引用
Set<Long> validMessageIds = validMessages.stream()
.map(Message::getMsgId)
.collect(Collectors.toSet()); List<MessageRef> deletedRefs = messageRefs.stream()
.filter(ref -> !validMessageIds.contains(ref.getMessageId()))
.collect(Collectors.toList()); if (!deletedRefs.isEmpty()) {
asyncTaskExecutor.execute(() -> {
for (MessageRef ref : deletedRefs) {
inboxService.removeMessage(userId, ref.getMessageId(), ref.getSenderId());
}
});
} return validMessages;
}
这里用到了"懒删除"的概念:不是在消息被删除的时候立刻清理所有收件箱中的引用,而是在粉丝读取Feed流的时候,顺带把无效引用清理掉。这样做的好处是删除操作零成本,缺点是清理不及时——但如果某个粉丝长期不活跃,他的收件箱里会积累一些无效引用。不过这些引用占用的内存很小(每条就几十字节),影响不大。
构建Feed项
最后一步是把消息内容和发布者信息组装成前端需要的格式。
复制代码private List<FeedItem> buildFeedItems(List<Message> messages) {
if (messages.isEmpty()) {
return Collections.emptyList();
} // 1. 收集所有发布者ID
Set<Long> senderIds = messages.stream()
.map(Message::getSenderId)
.collect(Collectors.toSet()); // 2. 批量获取用户信息(避免N+1查询问题)
Map<Long, UserInfo> userInfoMap = userService.getUserInfoByIds(senderIds); // 3. 组装Feed项
return messages.stream().map(message -> {
FeedItem item = new FeedItem();
item.setMessageId(message.getMsgId());
item.setContent(message.getMsgContent());
item.setTitle(message.getMsgTitle());
item.setType(message.getMsgType());
item.setTimestamp(message.getCtime().getTime()); UserInfo userInfo = userInfoMap.get(message.getSenderId());
if (userInfo != null) {
item.setSenderId(userInfo.getUserId());
item.setSenderName(userInfo.getNickname());
item.setSenderAvatar(userInfo.getAvatarUrl());
} return item;
}).collect(Collectors.toList());
}
这里有一个经典的性能陷阱——N+1查询问题。如果拿到20条消息,然后逐条去查发布者的用户信息,就要发起20次数据库查询。正确的做法是先收集所有发布者ID,然后一次性批量查询,再通过Map关联。这样只需要1次额外的数据库查询。
6. 小结
这一篇把Feed流系统最核心的两个操作——发布和读取——完整地实现了一遍。同时解决了几个关键问题:
- 基于游标的分页,避免动态列表的错位问题
- 软删除 + 懒删除,让消息删除操作零扩散成本
- 批量查询避免N+1问题
- 异步处理提升发布接口的响应速度
到目前为止,一个基础的Feed流系统已经能跑起来了。但要从"能跑"变成"好用",还有很多细节要打磨。最后一篇我们会聊一些进阶话题:关注和取关时的收件箱刷新、缓存防护策略、监控告警,以及推荐类型Feed流的设计思路。