php中解压压缩文件实例源码
做这个之前,没有接触过php压缩这一块,网上搜了一些,大多数都是php压缩类、压缩函数,少则几百行,多的就几千行代码。这对于我这种新手来说很摸不到头脑,再说我也不用这么复杂的功能。最后参考函数手册,理清楚了几个相关的函数后,就明白了怎么去整了。
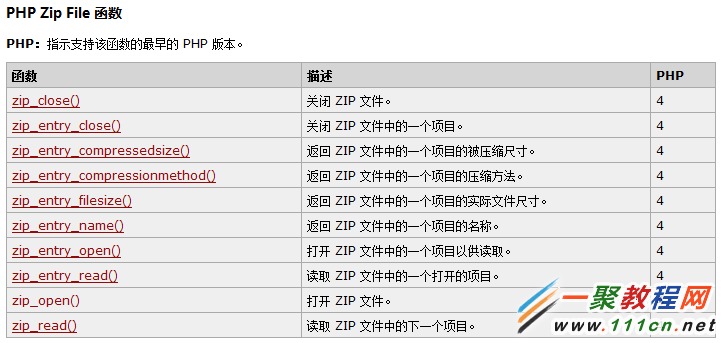
PHP Zip File 函数
记得要开启 zip ,把 php.ini 中的 extension=php_zip.dll 前面的分号去掉。
源码范例:
| 代码如下 | 复制代码 |
|
//phpinfo(); header("Content-type:text/html;charset=utf-8");
//先判断待解压的文件是否存在 if(!file_exists($filename)){ die("文件 $filename 不存在!"); } $starttime = explode(' ',microtime()); //解压开始的时间 //将文件名和路径转成windows系统默认的gb2312编码,否则将会读取不到 $filename = iconv("utf-8","gb2312",$filename); $path = iconv("utf-8","gb2312",$path); //打开压缩包 $resource = zip_open($filename); $i = 1; //遍历读取压缩包里面的一个个文件 while ($dir_resource = zip_read($resource)) { //如果能打开则继续 if (zip_entry_open($resource,$dir_resource)) { //获取当前项目的名称,即压缩包里面当前对应的文件名 $file_name = $path.zip_entry_name($dir_resource); //以最后一个“/”分割,再用字符串截取出路径部分 $file_path = substr($file_name,0,strrpos($file_name, "/")); //如果路径不存在,则创建一个目录,true表示可以创建多级目录 if(!is_dir($file_path)){ mkdir($file_path,0777,true); } //如果不是目录,则写入文件 if(!is_dir($file_name)){ //读取这个文件 $file_size = zip_entry_filesize($dir_resource); //最大读取6M,如果文件过大,跳过解压,继续下一个 if($file_size $file_content = zip_entry_read($dir_resource,$file_size); file_put_contents($file_name,$file_content); }else{ www.111com.net echo " ".$i++." 此文件已被跳过,原因:文件过大, -> ".iconv("gb2312","utf-8",$file_name)." ";} } //关闭当前 zip_entry_close($dir_resource); } } //关闭压缩包 zip_close($resource); $endtime = explode(' ',microtime()); //解压结束的时间 $thistime = $endtime[0]+$endtime[1]-($starttime[0]+$starttime[1]); $thistime = round($thistime,3); //保留3为小数 echo " 解压完毕!,本次解压花费:$thistime 秒。 ";}
|
|
测试解压了一个300多KB的小文件,花了0.115秒,测试解压了一个30多MB的(网页文件,小文件比较多),花了20多秒。
php解压程序
跟系统比起来确实慢了一些,但是这也很不错了!刚刚入门,代码还不优良,但是实现了解压,而且代码也比网上的简介易懂,如果你看到这篇文章,相信对你是有帮助的!程序中用到了程序运行的时间,具体可以看看: 。

最后,我觉得:
| 代码如下 | 复制代码 |
|
//最大读取6M,如果文件过大,跳过解压,继续下一个 if($file_size $file_content = zip_entry_read($dir_resource,$file_size); file_put_contents($file_name,$file_content); } |
|
这一块做的不太好,这样对大文件解压就没办法了,等会再优化一下。