组件语义分类和漂移模式匹配:从观察到归类的结构化规范
> 本文基于 [《组件语义快照与模式诊断:AI 生成界面的第一道检查》](https://cloud.tencent.com/developer/article/2700576) 中的概念继续展开。

---
一、为什么需要分类与匹配
在使用组件语义快照记录界面证据的过程中,我很快遇到一个问题:当快照数量从 10 张增加到 50 张时,单纯按产品名称或时间顺序归档,已经无法满足分析需求。
具体表现为:
- 按产品归档时,通用对话产品的"Error in message stream"和搜索增强产品的"连接断开"被分在不同文件夹,但它们本质上是同一类语义断层- 按时间归档时,三个月前记录的 代码生成产品过程状态问题和上周记录的秘塔过程状态问题,被时间线割裂,无法横向对比
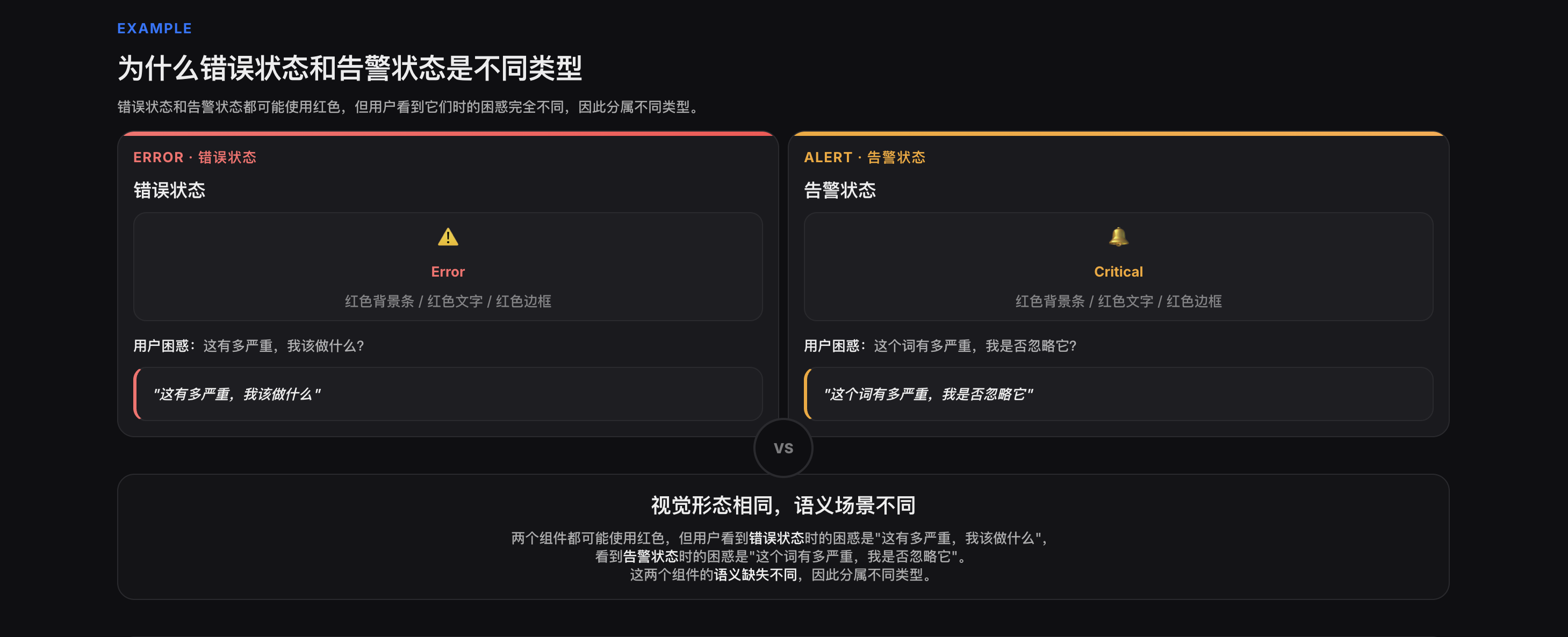
- 按视觉特征归档时,红色错误和红色告警被混为一谈,但它们的组件类型和语义缺失完全不同这说明:组件语义快照需要一层**分类维度**,使得不同产品、不同时间的记录,能够按语义规律聚类。我选择的分类维度是 **component_type**(组件类型),依据是用户交互路径而非视觉形态。**同一组件类型在不同产品中的语义漂移,往往指向同一个缺失的语义令牌。**---## 二、组件分类:5 种高频语义组件基于对8类AI产品的观察,我将语义漂移高发的组件归纳为5种。**这个分类不是穷尽式的,而是基于当前样本的归纳,随着观察范围扩展可能调整。**### 2.1 分类依据分类标准不是"长什么样"(视觉形态),而是**"用户在什么场景下看到它"(交互路径)**。例如:- 错误状态和告警状态都可能使用红色,但用户看到错误状态时的困惑是"这有多严重,我该做什么",看到告警状态时的困惑是"这个词有多严重,我是否忽略它"- 这两个组件的语义缺失不同,因此分属不同类型
### 2.2 5 种组件类型
| 组件类型 | 用户交互场景 | 用户核心困惑 | 典型产品实例 |
|---------|-------------|-------------|-------------|| **错误状态** | 用户遇到系统故障时看到的提示 | "这有多严重?我该做什么?" | 通用对话产品 报错、搜索增强产品连接断开、通义千问 429 |
| **过程状态** | AI 执行多步任务时显示的进度 | "AI 现在是在查资料还是在编答案?" | 代码生成产品 Searching/Reading、秘塔搜索过程 || **边界动作** | AI 拒绝、终止或升级审核时 | "我的权利还在吗?对话还能继续吗?" | Claude 拒绝/终止、通用对话产品内容审核 |
| **操作按钮** | 用户点击执行某个操作时 | "点了会出大事吗?能撤销吗?" | v0 删除按钮、Claude Code 数据管理按钮 || **告警状态** | 系统提示用户注意某个状态时 | "这个词有多严重?我是否忽略它?" | AI 运维告警、系统状态提示 |
### 2.3 分类的边界说明
这 5 种组件类型之间存在边界模糊地带:
- **错误状态 vs 告警状态**:两者都可能使用红色,但错误状态出现在用户操作受阻时,告警状态出现在系统主动提示风险时。区分依据是"用户是否触发了该状态"。
- **操作按钮 vs 边界动作**:操作按钮是用户主动发起的,边界动作是系统主动发起的。但当操作按钮触发系统级后果(如删除账户)时,两者的语义约束需要叠加。这些边界模糊地带不是分类的失败,而是提示:某些场景需要同时应用多个组件类型的语义约束。
---
三、从快照到模式:归纳方法
当快照按组件类型分组后,下一步是识别同一组件类型内的共性规律,即**漂移模式**。
### 3.1 归纳步骤
我使用的归纳方法包含四步:
**第一步:聚类**
将同一 component_type 下的快照按 user_confusion 分组,提取困惑描述中的共性关键词。例如,错误状态组件下的快照,user_confusion 反复出现"不知道多严重""不知道该刷新还是该等""红色让我以为系统崩了"。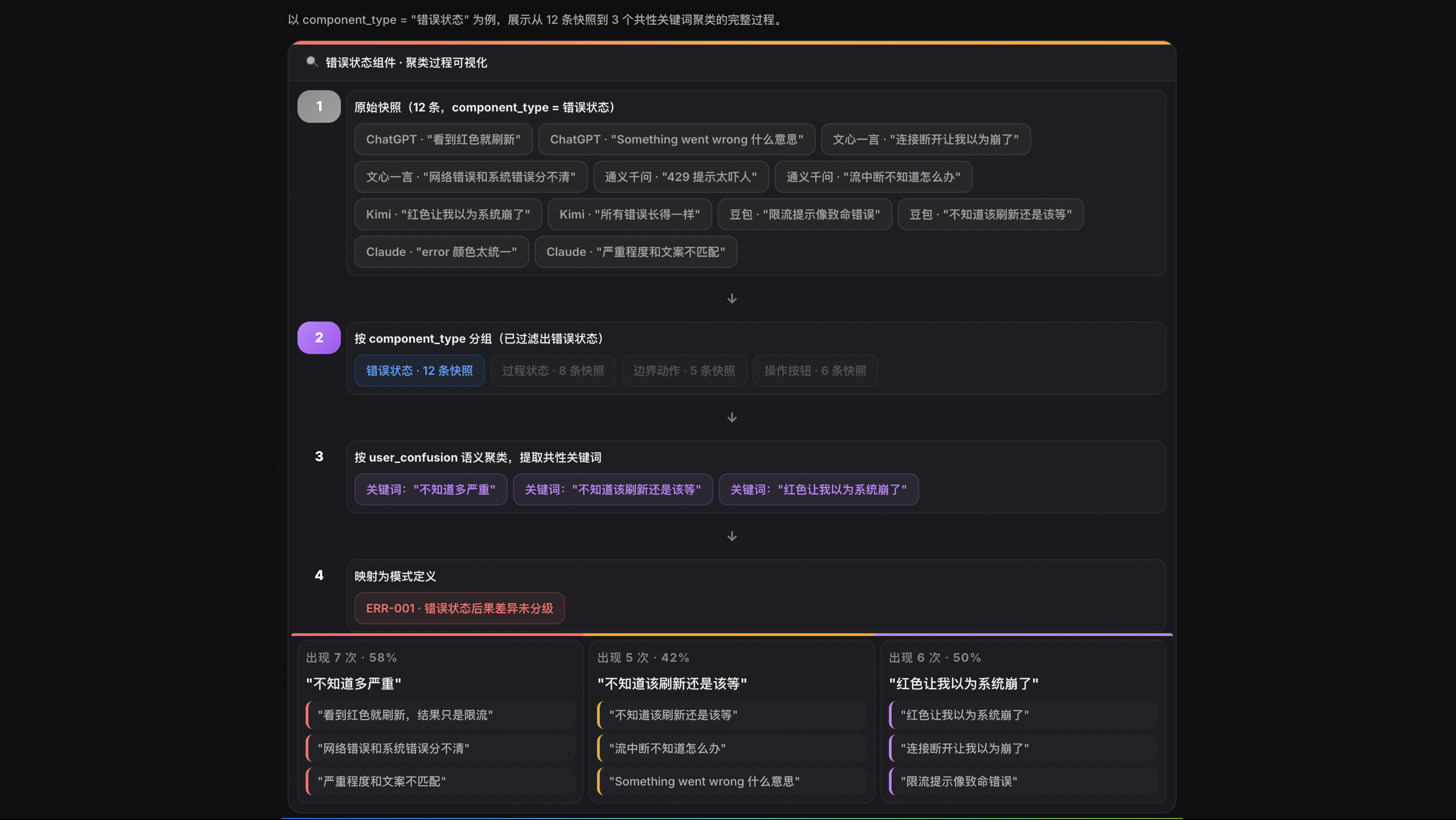
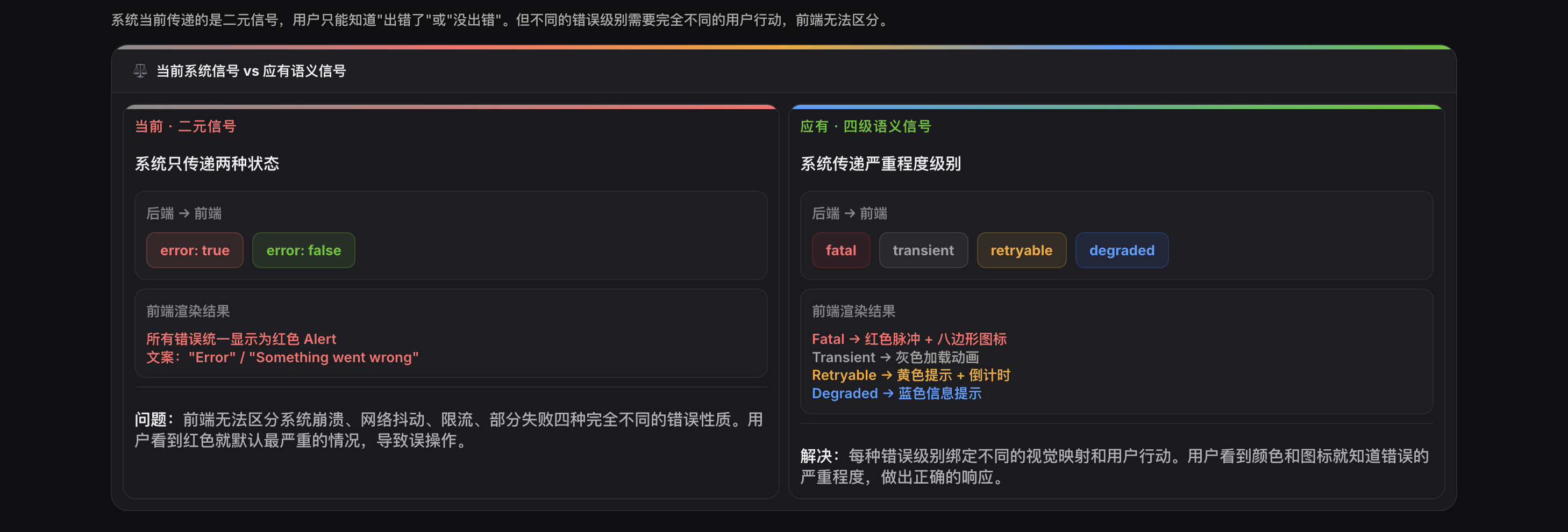
**第二步:归因**分析共性困惑背后的语义缺失。上述困惑的共同归因是:系统没有定义错误的严重程度级别,前端只接收到"出错了"的二元信号,没有接收到"这是什么级别的错误"的语义信息。
**第三步:跨产品验证**
将归因结论放到不同产品中验证。如果 通用对话产品、搜索增强产品、代码生成产品、企业组件库 的错误状态都呈现"多种错误共用同一种视觉"的现象,则归因结论的跨产品复现性成立。
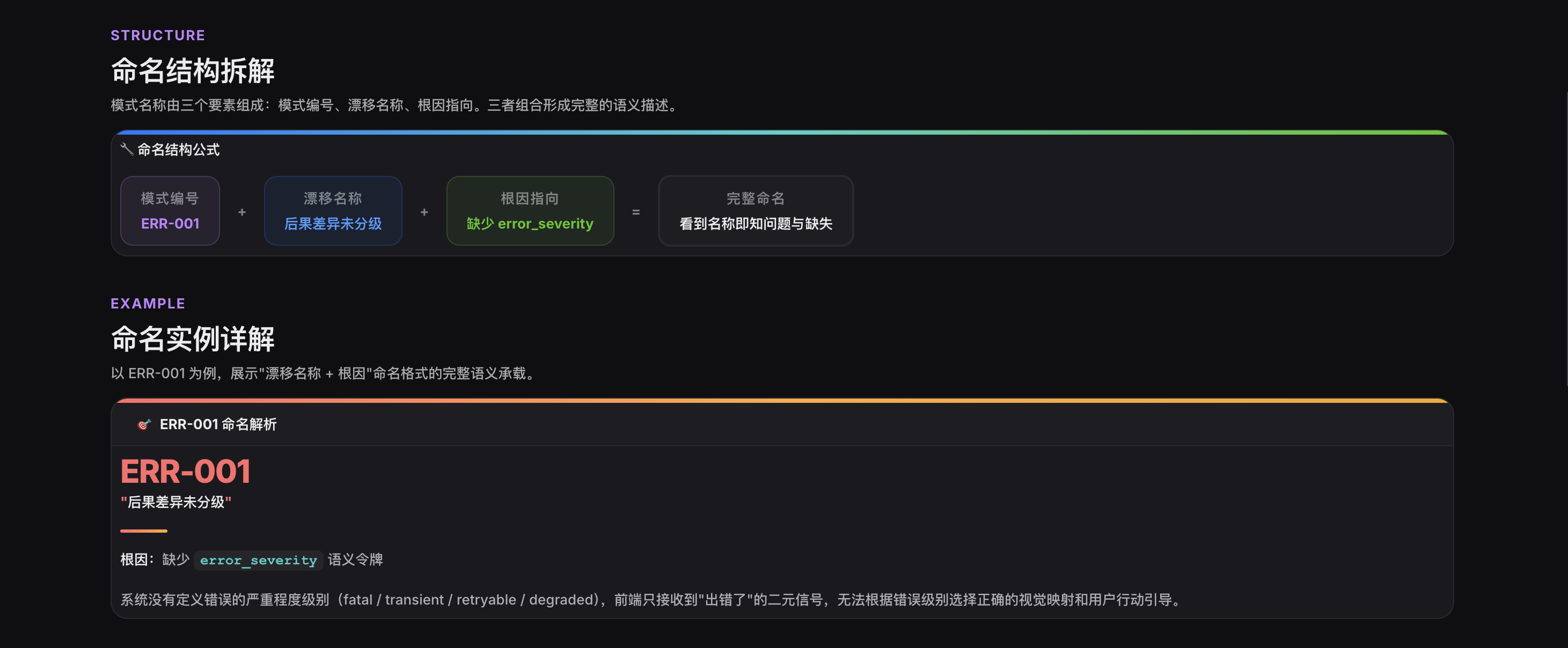
**第四步:命名**用"漂移名称 根因"的格式命名模式,确保模式名称本身即包含问题描述和缺失的语义令牌。例如:ERR-001"后果差异未分级",根因是缺少 `error_severity` 语义令牌。
### 3.2 模式与组件类型的对应关系每个组件类型对应一个或多个漂移模式。当前观察样本中,5 种组件类型共归纳出 6 个模式:| 组件类型 | 模式数量 | 模式 ID | 漂移名称 ||---------|---------|---------|---------|
| 错误状态 | 1 | ERR-001 | 后果差异未分级 || 过程状态 | 1 | PRO-001 | 认知阶段未显化 |
| 边界动作 | 1 | BND-001 | 权利差异未区分 || 操作按钮 | 1 | ACT-001 | 高危操作未约束 |
| 告警状态 | 1 | ALR-001 | 语义降级 || 表单验证 | 1 | FRM-001 | 校验反馈缺失 |
> 注:表单验证未列入 5 种高频组件类型,是因为当前样本中其出现频率低于前 5 种,但已观察到足够证据支持独立模式。
---
四、结构化诊断规范:从快照到模式的匹配流程
组件分类和模式归纳完成后,需要建立一套可复用的匹配流程,使得新的快照记录能够快速归类到已有模式,或触发新模式创建。
我将其定义为**结构化诊断规范**,包含 3 个判定维度。
### 4.1 判定维度一:组件类型识别
根据界面的交互场景,确定其属于 5 种组件类型中的哪一种:
- 用户遇到故障时看到的 → 错误状态
- AI 干活时显示的进度 → 过程状态- AI 拒绝/终止/升级时 → 边界动作
- 用户点击执行的 → 操作按钮- 系统主动提示风险时 → 告警状态
如果无法明确归入单一类型,则标记为"复合类型",需要同时应用多个组件类型的语义约束。
### 4.2 判定维度二:语义缺失识别
根据 user_confusion 的描述,判断用户的核心困惑属于哪一类语义缺失:
| 用户困惑关键词 | 语义缺失类型 | 对应模式 |
|-------------|------------|---------|| "不知道多严重""不知道该做什么" | 后果差异未分级 | ERR-001 |
| "不知道在干什么""不知道查资料还是编答案" | 认知阶段未显化 | PRO-001 || "我的权利还在吗""对话还能继续吗" | 权利差异未区分 | BND-001 |
| "点了会出大事吗""能撤销吗" | 高危操作未约束 | ACT-001 || "这个词有多严重""是否忽略它" | 语义降级 | ALR-001 |
| "不知道哪一格填错了""不知道怎么修正" | 校验反馈缺失 | FRM-001 |### 4.3 判定维度三:视觉表达校验记录当前界面的视觉表达,作为后续契约定义时的映射依据:- 颜色使用:是否全部使用同一种颜色?是否颜色与语义级别不匹配?- 文案表达:是否使用了模糊词汇(如"出错了""Something went wrong")?是否使用了被禁止的同义词?
- 行动指引:是否提供了明确的用户下一步行动?行动按钮的视觉权重是否与后果级别匹配?### 4.4 输出结果完成 3 个判定维度后,输出:- **模式匹配结果**:匹配到已有模式(如 ERR-001),或标记为"待归类"- **缺失语义令牌**:该模式对应的缺失语义维度(如 `error_severity`)
- **归档路径**:该快照在模式库中的存储位置- **后续行动**:是否需要创建新模式,或补充已有模式的证据
---
五、模式库的结构化存储
诊断规范的输出需要归档到模式库中,以便后续查询和复用。模式库的结构如下:
```
模式库├── 错误状态
│ └── ERR-001 后果差异未分级│ ├── 症状:多种错误共用同一种视觉表达
│ ├── 根因:缺少 error_severity 语义令牌│ ├── 产品实例:通用对话产品 / 搜索增强产品 / 代码生成产品 / 企业组件库
│ └── 快照证据:SNAP-202506-001, SNAP-202506-003...├── 过程状态
│ └── PRO-001 认知阶段未显化│ ├── 症状:过程标签只描述动作,不描述认知阶段
│ ├── 根因:缺少 process_phase 语义令牌│ ├── 产品实例:代码生成产品 / 秘塔
│ └── 快照证据:SNAP-202506-002......
```每个模式节点包含 4 个标准字段:症状、根因、产品实例、快照证据。这种结构使得模式库可以被机器解析,也可以被人阅读。---## 六、局限与边界1. **组件分类未穷尽**:当前 5 种组件类型基于 8 类 AI 产品的观察归纳,随着产品类型扩展(如 AR/VR 界面、语音交互),分类可能需要调整。2. **诊断规范的主观性**:判定维度二(语义缺失识别)依赖 user_confusion 的准确记录。如果 user_confusion 字段缺失或推断不准确,匹配结果可能出现偏差。3. **模式库的版本管理**:当前模式库为 v0.1 草案,随着新快照的增加,已有模式可能被拆分、合并或重新定义。需要建立版本管理机制。4. **跨语言适配**:当前诊断规范基于中文和英文界面观察,其他语言界面的语义漂移规律可能不同。---## 七、衔接:从模式库到契约库组件分类和模式匹配规范解决的是"把分散的证据组织成可追踪的知识"。但这只是阶段一的后半段。阶段二(Contract)将基于模式库中的每个模式,定义对应的语义约束契约(YAML 格式)。具体而言:- ERR-001 对应 `error_severity` 语义令牌定义- PRO-001 对应 `process_phase` 语义令牌定义
- BND-001 对应 `boundary_action` 语义令牌定义- ACT-001 对应 `action_risk` 语义令牌定义
- ALR-001 对应 `synonym_firewall` 语义约束定义- FRM-001 对应 `validation_semantics` 语义令牌定义
这些契约将在后续文章中展开。
---
**Gap 期局限性声明**
当前状态: 架构推演与最小可行原型阶段。YAML 规范、校验逻辑为定义层实现,尚未接入生产级 LLM API 或 CI 流水线。欢迎基于现有思路共建。
**关于作者**
魏雯,体验架构设计师。
专注于:AI 界面的语义治理。解决的核心问题:让 LLM 生成的界面不偏离设计规范。
10 年互联网设计经验。设计系统 体验工程 AI 原生|广州 / 深圳","createTime":1782794548,"ext":{"closeTextLink":0,"comment_ban":0,"description":"","focusRead":0},"favNum":0,"html":"","isOriginal":0,"likeNum":0,