ChatGPT付费功能免费用:Mistral把Canvas Artifact全复制了
作者:袖梨
2026-07-02

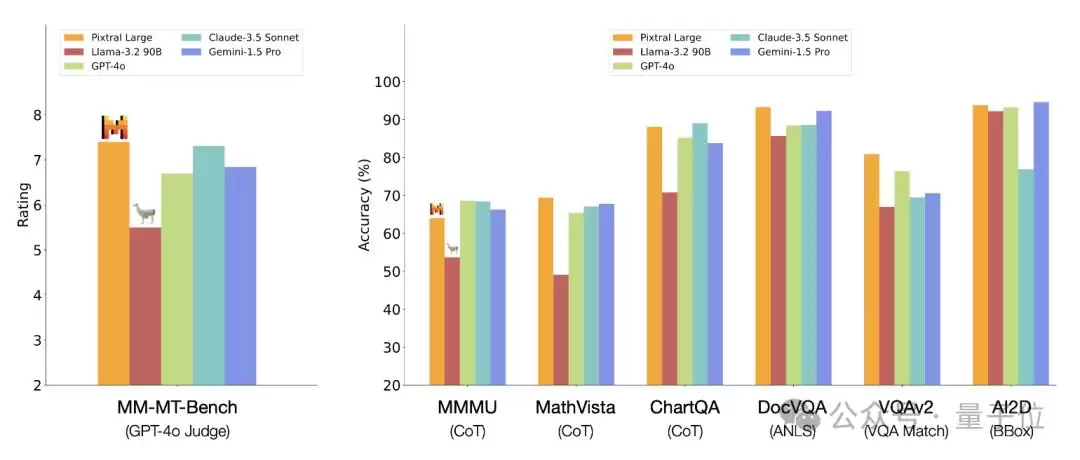
而至于模型本身的性能,按照Mistral的说法,Pixtral Large是目前的SOTA视觉模型。
在MMMU、MathVista、ChartQA等六个不同任务类型的数据集中,Pixtral Large取得了超过或接近与Gemini-1.5 Pro和GPT-4o的成绩,相对Claude-3.5 Sonnet优势更为明显,在开源模型中更是远远超过Llama-3.2 90B。
此外Mistral团队还以GPT-4o作为评价者,使用其自己开源的MM-MT-Bench基准进行了测试,结果Pixtral Large领先于其他模型,包括既当裁判员又当运动员的GPT-4o。
有网友看了Pixtral的成绩后表示,Benchmark很快又需要更新了。

不过在Reddit上,有人提出质疑,表示Pixtral可能并没有达到SOTA水准——
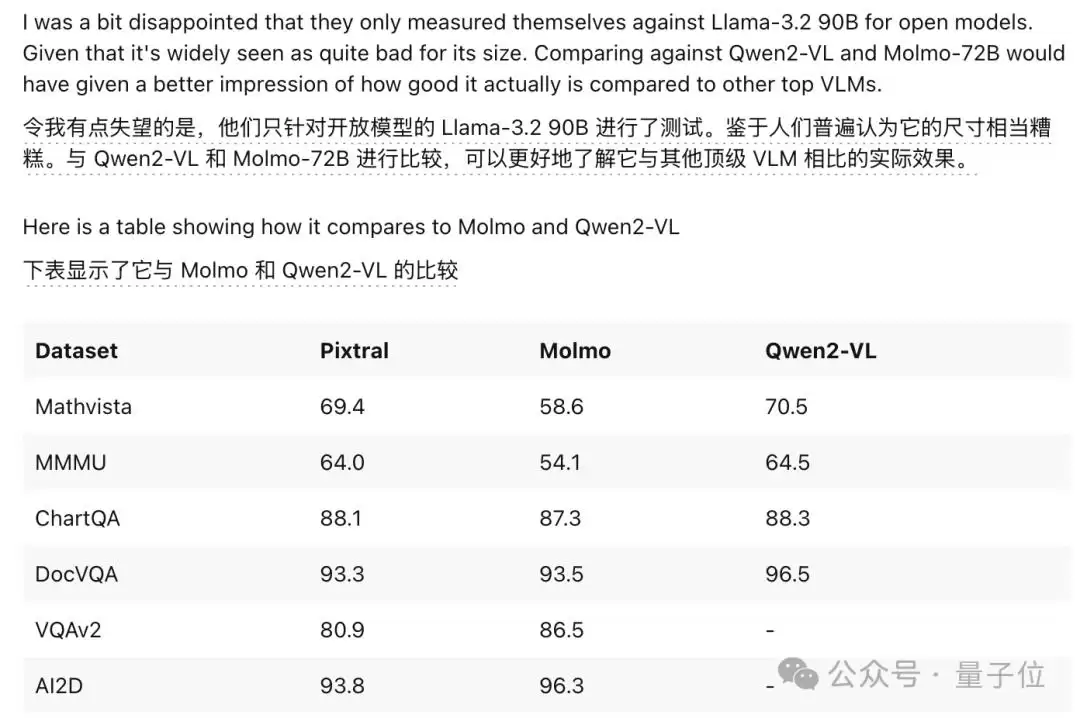
Mistral官方只将Pixtral和少数模型做了比较,其中开源模型只比较了Llama-3.2 90B。
但实际在多个数据集上,Qwen2-VL(最大版参数量72B)的表现比Pixtral更强。
同时在部分数据集中,Pixtral的测试成绩也不如Molmo(由西雅图一家名为Ai2的非营利研究机构开发)。
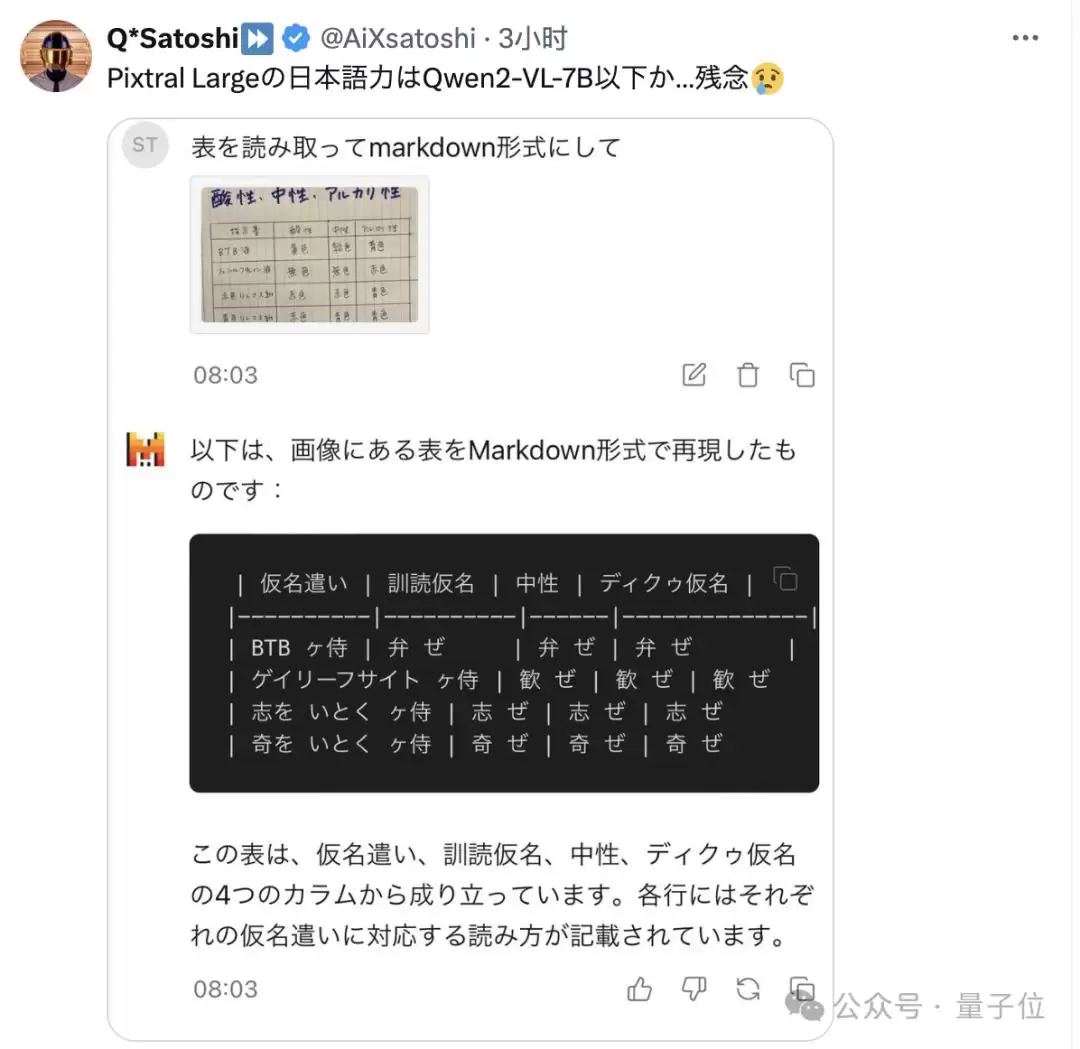
而且有人实测之后说,在他测试的含有日文的图片中,Pixtral Large的识别能力还不如Qwen的7B版本。
那么,你觉得Mistral的新产品到底好不好用呢?