从心出发:从架构原本到训推工坊
2022 年的上海,发生了很多事情。
因为固有工作较难找出新的增长点,那时候也是在大模型爆发的前夜,传统技术如何做出新的花样? 团队和个人如何有新的发展?
在工作的间隙,想写一个 架构原本 的公众号。这个名字的意思,是想回到架构的原本:不只讲某一个技术点,也不只讲某一个漂亮方案,而是去找技术背后的内核。
这个内核既包括技术本身,也包括一个架构师、高阶技术人员应该具备的判断力、表达能力、协同能力和交付能力。
那篇发刊词里,我写过一个想法:最好的投资,是投资自己。
这句话听起来很朴素,但越往后越觉得重要。无论外部环境怎么变,逼出更好的自己,长期看都是最稳的投资。写文章就是其中一种方式。因为写作会逼你重新组织知识,逼你分辨自己到底是真懂,还是只是听过。
后来因为工作变化,这个公众号没有持续写下去。
这是遗憾。但现在,我想从新开始。
这一次,名字从“架构原本”变成“训推工坊”。
关注点也从更宽泛的架构设计,收束到 AI 时代最核心的一条工程链路:训练和推理如何组成一个可持续生产模型能力的系统。
为什么是现在
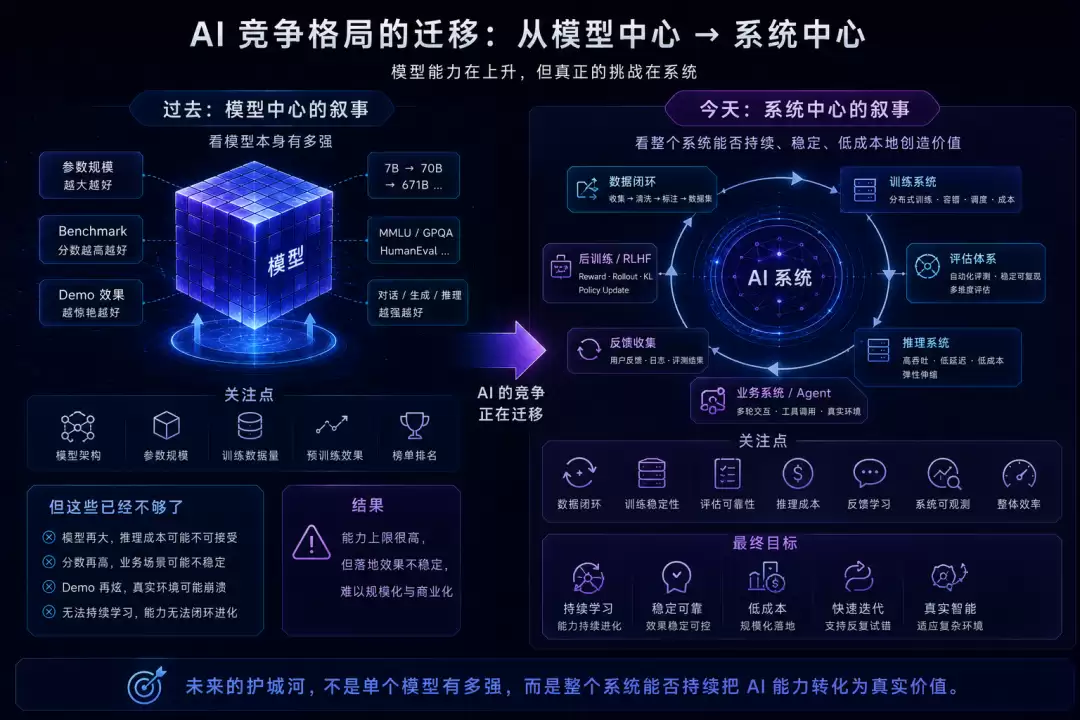
过去几年,AI 行业的叙事变得很快。
一开始大家看模型参数,看 benchmark,看 demo。模型越大、分数越高、回答越惊艳,似乎就越能代表技术先进性。
但到了今天,这已经不够了。
模型能力还在继续上升,但能力本身不再是唯一问题。一个 AI 系统能不能被持续训练,能不能稳定评估,能不能低成本推理,能不能把业务反馈重新变成训练信号,能不能在真实环境里支撑 Agent 多轮交互,这些问题越来越重要。
换句话说,AI 的竞争正在从“模型中心”进入“系统中心”。
如果只看模型,我们会问:
模型多大?数据多少?榜单多少分?但如果看系统,我们要问的问题会变成:
训练系统能不能支撑反复试错?推理系统能不能承受真实流量?后训练能不能把 reward、rollout、policy update 串成稳定闭环?多轮 Agent 的轨迹能不能精确还原到 token 级别?GPU 时间到底花在有效计算上,还是花在等待、通信、搬数据和空转上?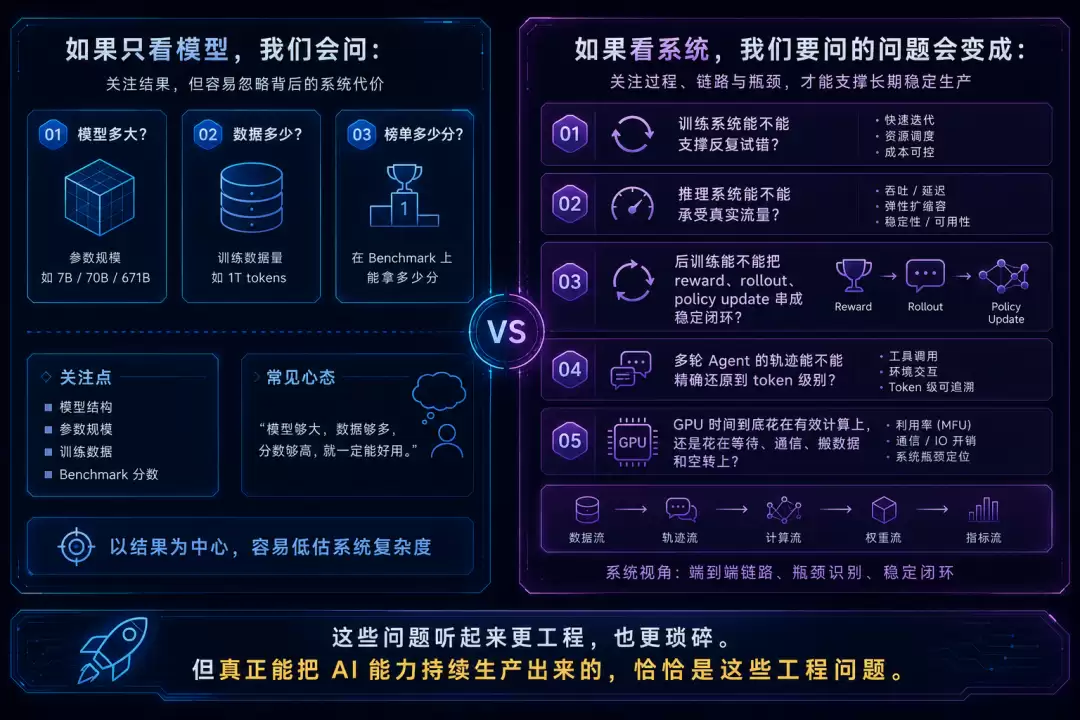
这些问题听起来更工程,也更琐碎。
但真正能把 AI 能力持续生产出来的,恰恰是这些工程问题。
为什么是训推
传统理解里,训练和推理是两个阶段。
训练是离线的,负责更新模型权重。
推理是在线的,负责服务用户请求。
但在 RLHF、PPO、GRPO、DAPO、Agentic RL 这些后训练场景里,这个边界正在消失。
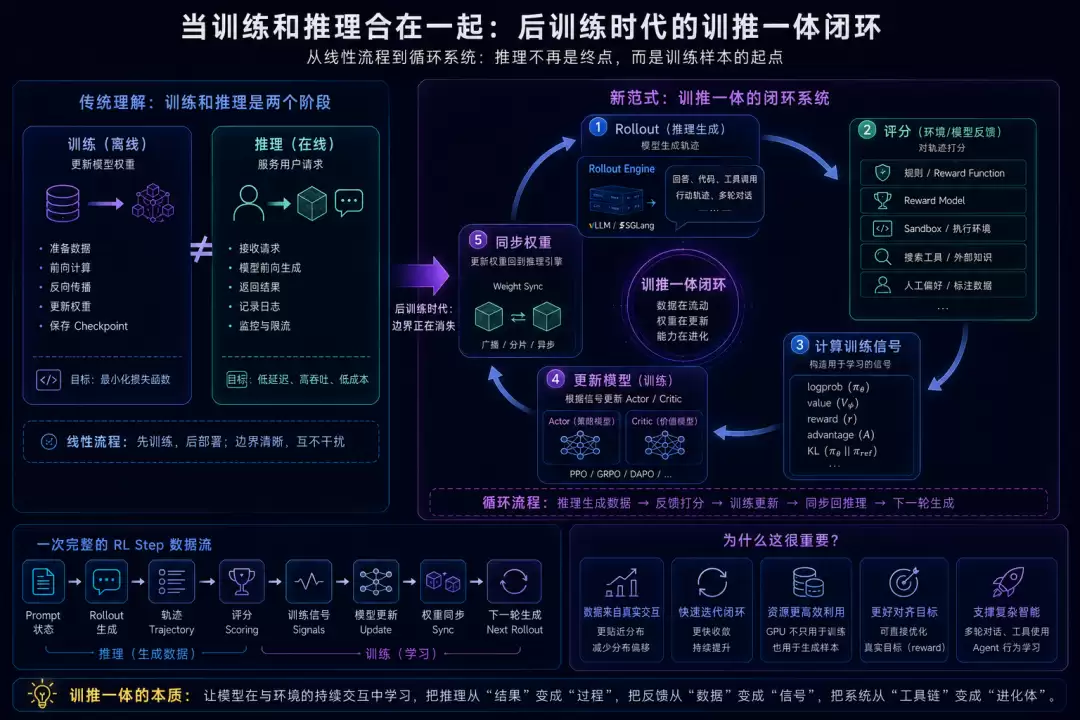
推理不再只是训练结束后的部署结果。它会进入训练循环,成为训练样本的生产过程。
模型先 rollout,生成回答、代码、工具调用或行动轨迹;
系统再根据规则、reward model、sandbox、搜索工具、环境反馈或人工偏好给轨迹打分;
训练引擎根据 reward、logprob、value、advantage、KL 等信号更新 actor;
更新后的权重再同步回 rollout engine;
然后开始下一轮生成。
这就是“训推”两个字真正合在一起的地方。
它不是训练加推理两个模块的简单拼接,而是一条从数据到轨迹、从轨迹到 reward、从 reward 到梯度、从梯度到新权重、再从新权重回到推理生成的闭环。
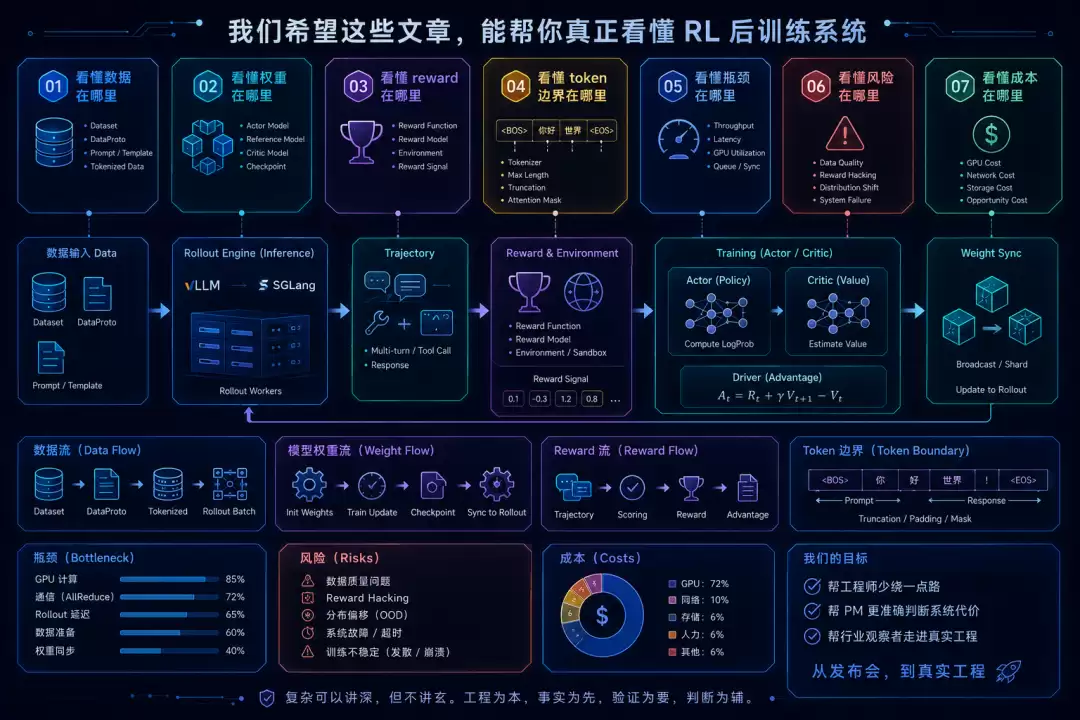
如果把这条链路展开,它至少包括 8 个环节。
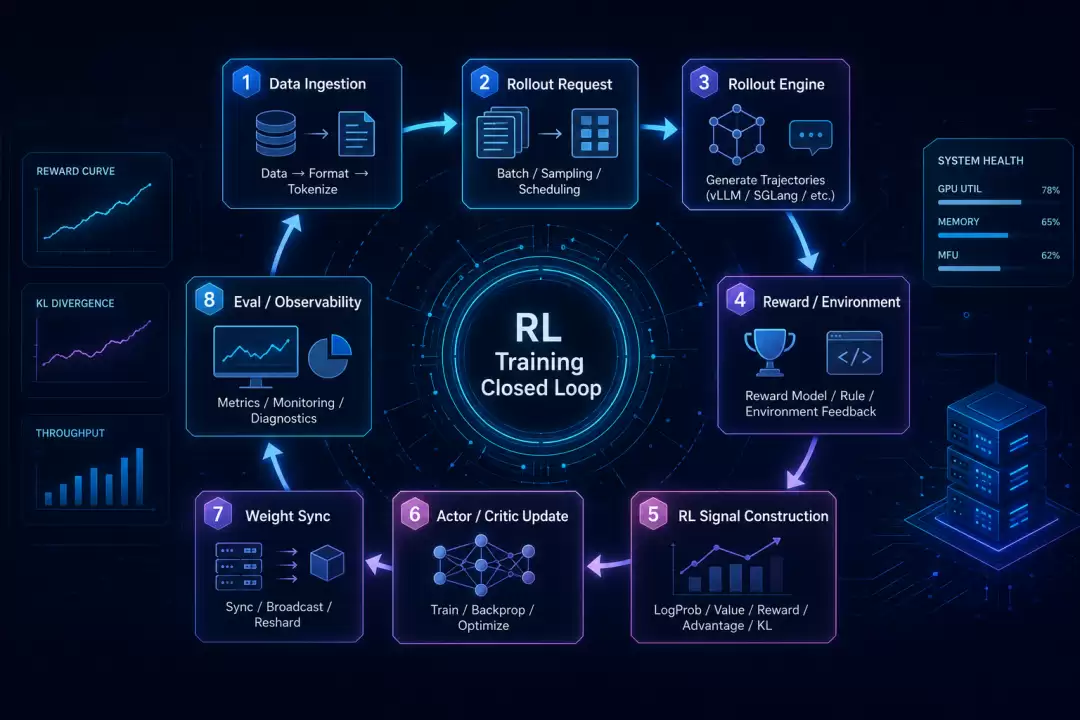
第一,数据进入系统。
原始题目、对话、偏好样本、代码任务、工具任务、多模态样本,要先被整理成训练框架能消费的格式。这里会涉及 dataset、parquet、prompt schema、chat template、tokenization、max prompt length、truncation、multi-modal inputs。很多训练问题不是从模型开始坏的,而是从数据字段、模板和 token 边界开始偏掉的。
第二,构造 rollout 请求。
系统从训练集中取出一批 prompt,把它们变成推理引擎可以生成的输入。对于 GRPO、DAPO 这类算法,一个 prompt 往往会生成多个 response,形成 group sampling。这里会涉及 rollout batch、generation batch、temperature、top-p、response length、rollout.n、request scheduling。
第三,推理引擎生成轨迹。
模型通过 vLLM、SGLang、TensorRT-LLM 或 HF rollout 生成 token。单轮任务里,轨迹主要是 prompt 和 response;Agentic RL 里,轨迹还会包含多轮对话、工具调用、环境返回、sandbox 执行结果、tool reward、response mask。推理在这里不是终点,而是训练样本的生产机。
第四,reward 或环境反馈。
生成结果出来后,系统要给轨迹打分。分数可能来自 rule-based reward,比如数学答案匹配;也可能来自 reward model;还可能来自代码 sandbox、搜索工具、真实环境或人工偏好。这里会涉及 reward function、reward model、verifiable reward、process reward、outcome reward、overlong penalty、format reward、tool reward。
第五,把生成轨迹转成训练信号。
有了 response 和 reward 还不够。训练侧通常还要计算 old logprob、reference logprob、value、KL、token-level reward、advantage、returns 等字段。PPO 会依赖 critic 和 GAE;GRPO 依赖组内相对 reward;DAPO 还会引入 dynamic sampling、clip higher、token-level loss、overlong reward shaping。算法论文里的公式,到了系统里会变成一批必须精确对齐的数据字段。
第六,更新 actor 和 critic。
训练引擎拿到整理好的 batch 后,才真正进入 forward、backward、optimizer step。这里会出现 FSDP、FSDP2、Megatron、tensor parallel、pipeline parallel、expert parallel、micro batch、gradient checkpointing、activation offload、sequence parallel、dynamic batch size 等训练系统问题。后训练不是不训练,而是训练只占闭环中的一段。
第七,把新权重同步回推理侧。
actor 更新以后,rollout engine 必须用新策略继续生成下一批轨迹。于是系统要处理 checkpoint、weight sync、weight resharding、parameter broadcast、sleep/resume、KV cache 管理。模型越大,推理副本越多,训练和推理资源越分离,这一步越容易成为关键瓶颈。
第八,评测、观测和故障处理。
系统还要定期 validation,记录 reward、response length、KL、entropy、MFU、throughput、GPU memory、rollout latency、trainer idle ratio、rollouter idle ratio 等指标。否则你很难判断模型是在学习、在发散,还是只是因为 rollout 长尾、reward 噪声、batch 不均衡或权重同步拖慢了整个系统。
后续这个系列会逐篇拆这些环节。
哪些属于算法,哪些属于系统;
哪些是论文里的目标函数,哪些是工程里的数据字段;
哪些是训练瓶颈,哪些是推理瓶颈;
哪些问题表面上看是模型效果,背后其实是数据、调度、显存、通信或可观测性。
我会尽量讲清楚。
为什么用 verl 作为参照
这次系列,我们会以 verl 代码库为参照。
不是因为 verl 是唯一值得学习的框架,而是因为它足够适合作为一个“解剖标本”。
verl 来自 HybridFlow 论文,是一个面向大语言模型后训练的 RL 训练框架。它把 PPO、GRPO 等算法流程,放进一个可以连接 FSDP、FSDP2、Megatron-LM、vLLM、SGLang、HF Transformers 等训练和推理组件的系统里。
这件事的价值不只是“支持很多后端”。
真正有意思的是:verl 把 LLM 后训练这件事拆成了一个可以观察的系统。
在 verl 里,我们能看到一轮 RL step 是怎样发生的:
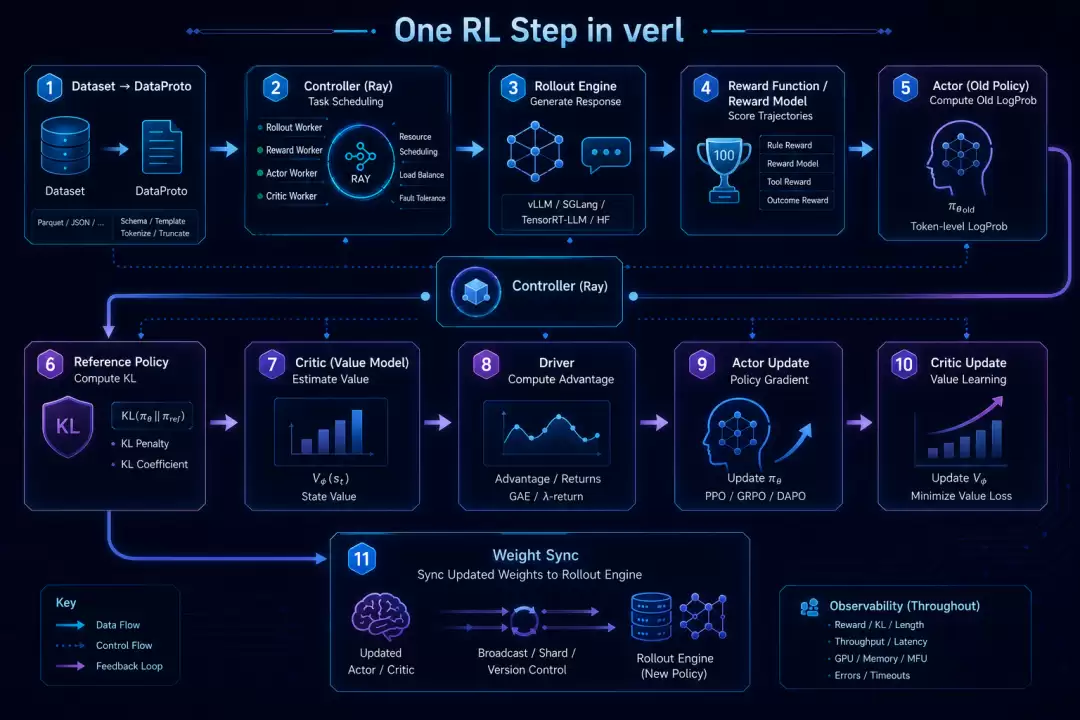
数据从 dataset 进入 DataProto;
controller 通过 Ray 调度不同角色的 worker;
rollout engine 生成 response;
reward function 或 reward model 给轨迹打分;
actor 重新计算 old logprob;
reference policy 计算 KL 相关约束;
critic 估计 value;
driver 计算 advantage;
actor 和 critic 分别更新;
训练权重再同步给 rollout engine。
这条链路里,每一步都对应一个真实的 AI infra 问题。
算法问题会变成数据流问题。
数据流问题会变成分布式调度问题。
分布式调度问题会变成显存、通信、batch、checkpoint、profiling 和 fault tolerance 问题。
这就是我们想讲清楚的东西。
从“架构原本”的道与术,到“训推工坊”的系统地图
当年我想写“架构原本”,是因为一直觉得架构有“道”和“术”。
设计模式、架构原则、模块边界、抽象能力、演进判断,这些更接近道。
业务架构、搜索推荐、云原生、可观测、数据湖、工程平台、组织协同,这些更接近术。
道太抽象,需要术来支撑。
术太具体,也需要道来校准。
好的架构设计,往往不是一开始就画出一张漂亮图,而是在约束、目标、团队能力、业务阶段和外部变量之间做取舍。
AI infra 也是一样。
FSDP、Megatron、vLLM、SGLang、checkpoint engine、TransferQueue、Agent Loop、reward model,这些都是术。
但它们背后也有道:
控制流和计算流如何分离?
训练和推理如何复用资源?
数据协议如何让复杂轨迹可流动?
算法灵活性和系统效率如何取舍?
同步训练和异步训练如何权衡新鲜度与吞吐?
可观测性如何帮助我们判断系统是真的在学习,还是只是在消耗 GPU?
如果只看术,很容易陷入配置和参数。
如果只谈道,又容易变成空泛的原则。
“训推工坊”想做的,是用真实代码把两者接起来。
这个系列写给谁
最重要的,写给自己。
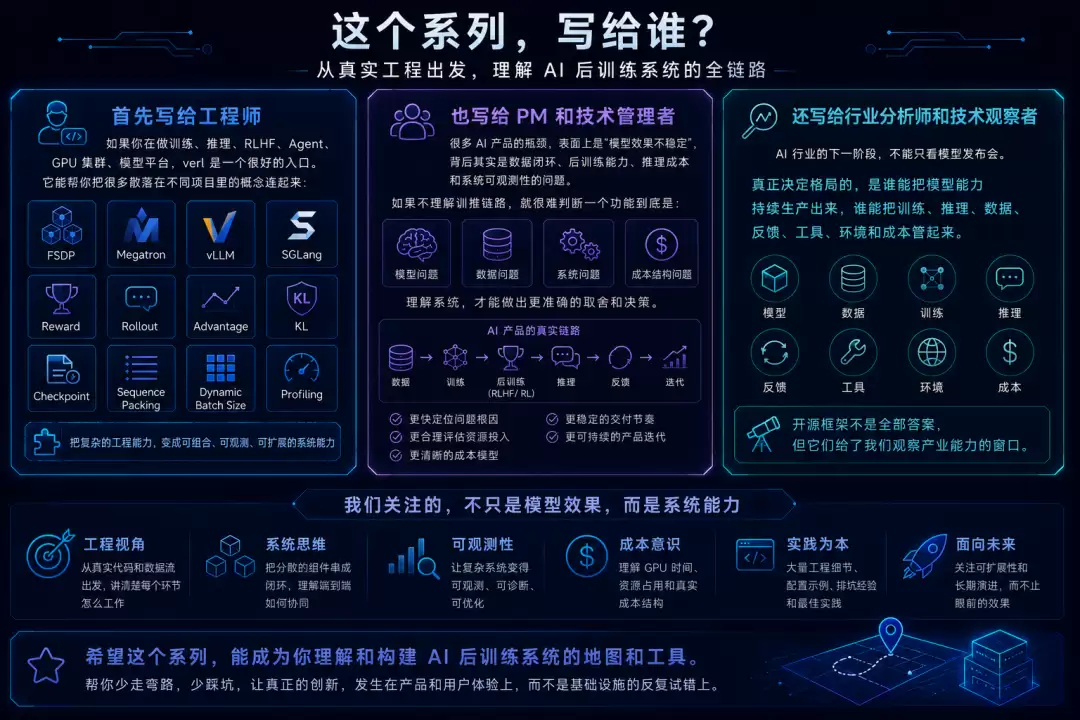
然后,这个系列首先写给工程师。
如果你在做训练、推理、RLHF、Agent、GPU 集群、模型平台,verl 是一个很好的入口。它能帮你把很多平时散落在不同项目里的概念连起来:FSDP、Megatron、vLLM、SGLang、reward、rollout、advantage、KL、checkpoint、sequence packing、dynamic batch size、profiling。
这个系列也写给 PM 和技术管理者。
很多 AI 产品的瓶颈,表面上是“模型效果不稳定”,背后其实是数据闭环、后训练能力、推理成本和系统可观测性的问题。如果不理解训推链路,就很难判断一个功能到底是模型问题、数据问题、系统问题,还是成本结构问题。
这个系列还写给行业分析师和技术观察者。
AI 行业的下一阶段,不能只看模型发布会。真正决定格局的,是谁能把模型能力持续生产出来,谁能把训练、推理、数据、反馈、工具、环境和成本管起来。开源框架不是全部答案,但它们给了我们观察产业能力的窗口。
我会怎么写(你要怎么读)
我们计划用 36 篇文章,分六组讲清楚这件事。
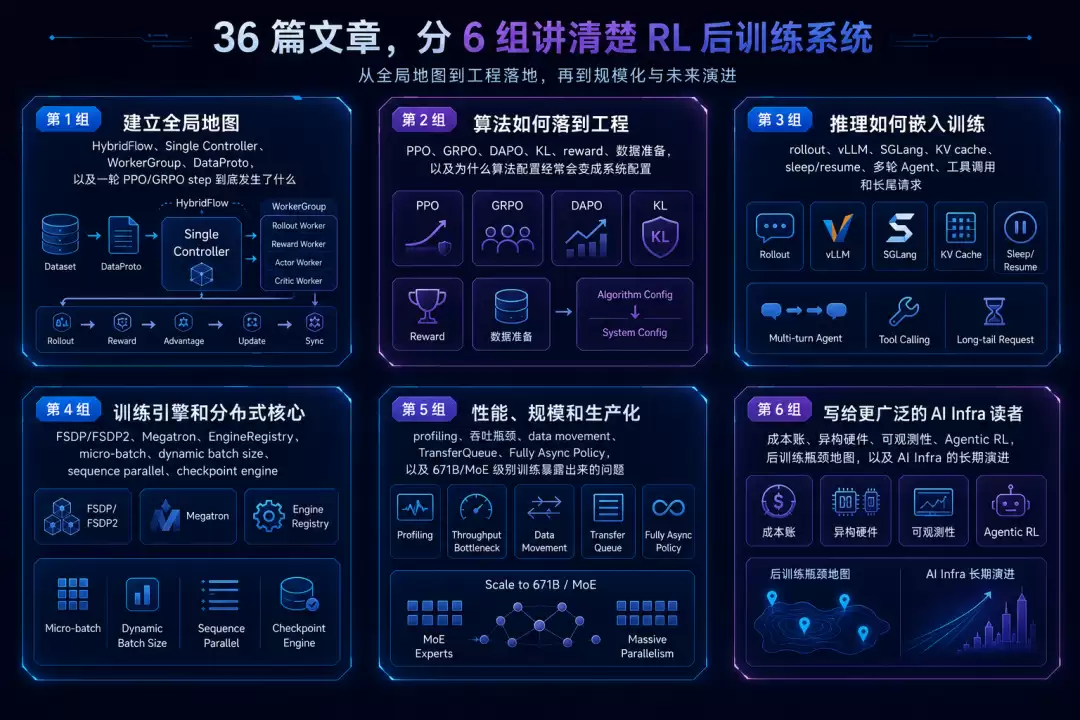
第一组,建立全局地图:HybridFlow、Single Controller、WorkerGroup、DataProto,以及一轮 PPO/GRPO step 到底发生了什么。
第二组,讲算法如何落到工程:PPO、GRPO、DAPO、KL、reward、数据准备,以及为什么算法配置经常会变成系统配置。
第三组,讲推理如何嵌入训练:rollout、vLLM、SGLang、KV cache、sleep/resume、多轮 Agent、工具调用和长尾请求。
第四组,讲训练引擎和分布式核心:FSDP/FSDP2、Megatron、EngineRegistry、micro-batch、dynamic batch size、sequence parallel、checkpoint engine。
第五组,讲性能、规模和生产化:profiling、吞吐瓶颈、data movement、TransferQueue、Fully Async Policy,以及 671B/MoE 级别训练暴露出来的问题。
第六组,写给更广泛的 AI infra 读者:成本账、异构硬件、可观测性、Agentic RL、后训练瓶颈地图,以及 AI infra 的长期演进。
每篇文章会尽量遵守三个原则。
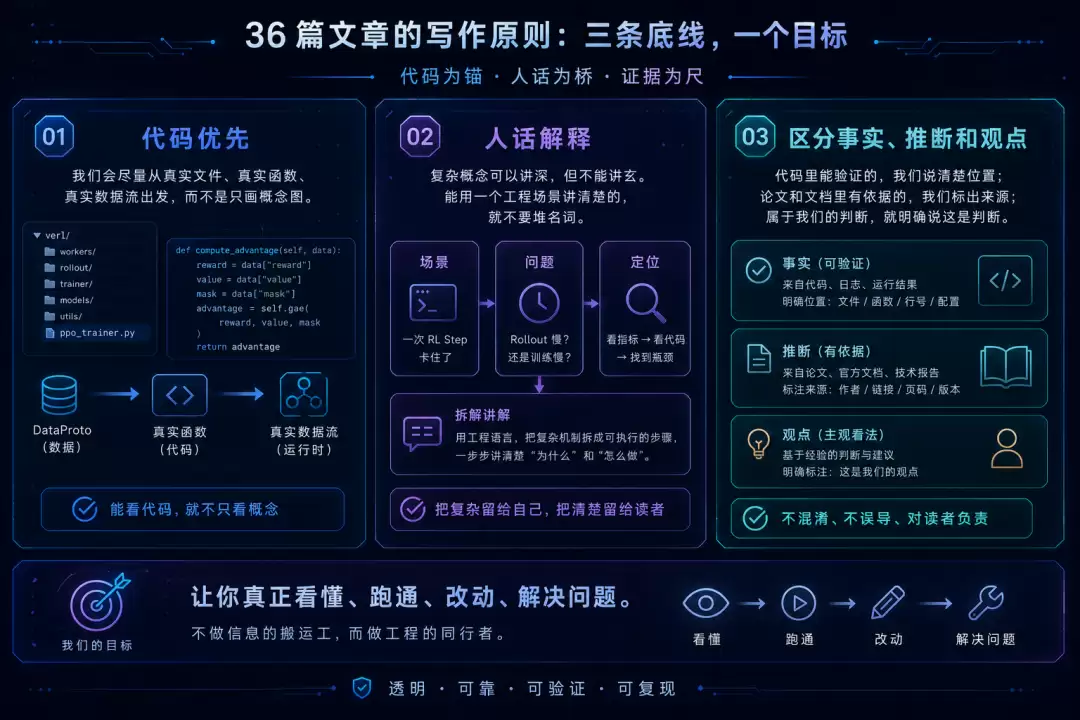
第一,代码优先。
我会尽量从真实文件、真实函数、真实数据流出发,而不是只画概念图。
第二,人话解释。
复杂概念可以讲深,但不能讲玄。能用一个工程场景讲清楚的,就不要堆名词。
第三,区分事实、推断和观点。
代码里能验证的,我们说清楚位置;论文和文档里有依据的,我们标出来源;属于我们的判断,就明确说这是判断。
从新开始
回到 2022 年那篇发刊词,我当时写到一半,最后说要去吃饭,吃完饭陪女儿玩“谁是卧底”。
那是一段很真实的生活。
技术人写文章,不能只有宏大叙事,也要承认生活、工作、家庭、环境都会影响节奏。
所以这一次重启,我不想把话说得太满。
这个系列不会承诺每篇都完美,也不会假装自己已经掌握所有答案。
我们只是从一个真实代码库开始,把一条复杂链路拆开,逐段看懂。
看懂数据在哪里;
看懂权重在哪里;
看懂 reward 在哪里;
看懂 token 边界在哪里;
看懂瓶颈在哪里;
看懂风险在哪里;
看懂成本在哪里。
如果这些文章能帮一些工程师少绕一点路,帮一些 PM 更准确地判断 AI 产品背后的系统代价,帮一些行业观察者从发布会走到真实工程里看问题,那就已经值得。
重要参考
Stanford HAI, The 2026 AI Index Report: https://hai.stanford.edu/ai-index/2026-ai-index-report
Stanford HAI, Inside the AI Index: 12 Takeaways from the 2026 Report: https://hai.stanford.edu/news/inside-the-ai-index-12-takeaways-from-the-2026-report
HybridFlow: A Flexible and Efficient RLHF Framework: https://arxiv.org/abs/2409.19256
verl GitHub README: https://github.com/verl-project/verl
本文参与腾讯云自媒体同步曝光计划,分享自微信公众号。原始发表:2026-05-17,如有侵权请联系[email protected] 删除