02 HybridFlow: 将RLHF看作高层Dataflow
全文摘要
这篇文章只解决一个问题:verl 为什么能把复杂的 RLHF/PPO 训练写得像一段单进程程序,同时又让真正的计算跑在多 GPU worker 上?
核心结论是:
HybridFlow 把 RL 算法的控制流留在单 controller,把 rollout、logprob、value、actor/critic update 这些重计算交给 WorkerGroup。
这不是一个单独的类,而是一组源码边界:
RayPPOTrainer.fit()写高层算法顺序。TaskRunner和 init_workers()把 role、resource pool、worker class 装配成可调用系统。DataProto/ TensorDict承载每一步产生的训练证据。@register和 RayWorkerGroup把一次普通方法调用变成 dispatch、remote execute、collect。这套设计买到的是算法可读性、后端可替换性和角色放置的灵活性;代价是 controller 会成为数据往返和调度汇合点。本文不展开 single_controller的完整实现细节,那是下一篇的主题。这里先建立读懂 HybridFlow 的最短源码路线。
先纠正一个误解:RLHF 不是普通训练脚本
读 HybridFlow 之前,先不要从 Ray、decorator 或 worker 细节开始。更好的入口是看 RLHF 的系统形状。
普通监督训练大多可以简化成:
代码语言:javascript复制batch -> forward -> loss -> backward -> optimizer step
PPO/GRPO 后训练不是这样。它的一个 step 至少包含:
代码语言:javascript复制prompt-> rollout-> reward-> old/ref logprob-> value-> advantage-> actor/critic update-> weight sync-> next rollout
下面这张图要看中间的闭环:rollout 依赖当前策略,reward/logprob/value 依赖 rollout 结果,actor 更新后还要把新权重同步给下一轮生成服务。
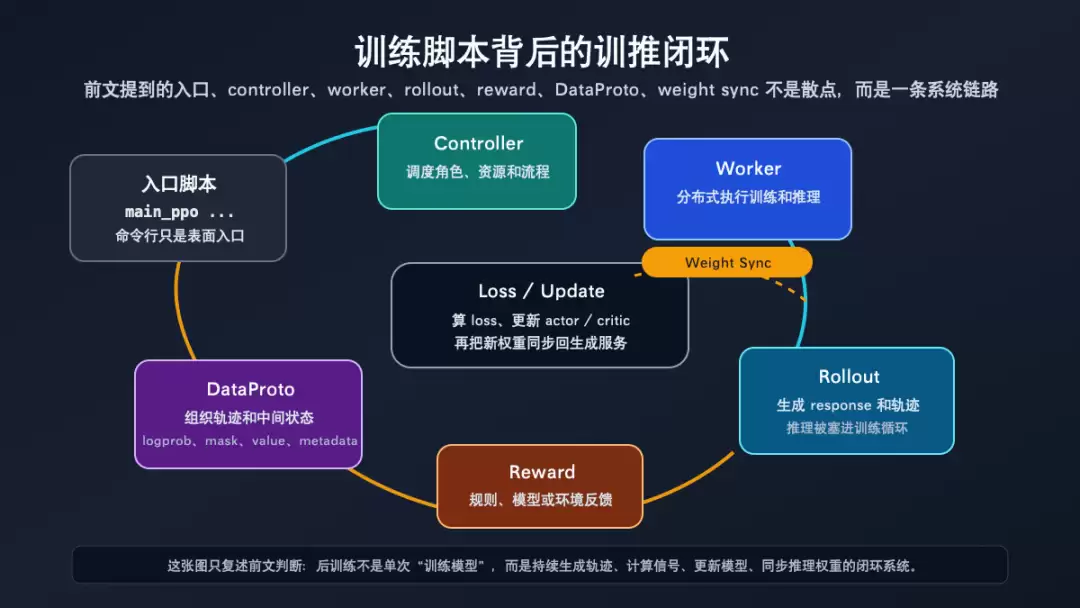
训练和推理如何合成一个闭环
这张图的含义是:后训练系统的难点不只是“训练一个模型”,而是让训练、推理、奖励、数据协议和权重同步在同一个循环里对齐。
HybridFlow 的作用,就是让这个循环在算法层仍然可读,同时让底层计算可以分布式执行。
HybridFlow 的边界:控制流留在 controller
本地文档 docs/hybrid_flow.rst:45-79把 RL dataflow 拆成两层:
verl 选择第二种设计:单进程 controller 负责 control flow,多进程 worker 负责 computation flow。
下面这张图要看左右两种路线的取舍。左边把控制流也下沉到 worker,固定流程里可能更紧凑;右边是 verl 的路线,把算法顺序留在 controller,把重计算挂到 worker 方法后面。

控制流放在 worker 侧还是单 controller 侧
图后的源码证据有三处:
docs/hybrid_flow.rst:68-79明确说 verl 采用 separate control flow and computation flow。verl/trainer/ppo/ray_trainer.py:1274-1279的 fit()docstring 说明 driver 通过 RPC 调 worker group 的 compute functions 来构造 PPO dataflow。verl/single_controller/ray/base.py:48-66的 func_generator()显示一次 WorkerGroup 方法调用会经过 dispatch、remote execute、collect 和可选 unpad。所以,HybridFlow 不是“把 PPO 分布式化”这么简单。它的关键是把算法顺序和计算执行拆开:controller 写“下一步做什么”,worker 负责“这一步怎么在多 GPU 上算”。
最短源码路线:只抓六个点
第二篇不需要把 single_controller的所有实现都读完。建议先按下面六个点走:
verl/trainer/main_ppo.py:48-98run_ppo()初始化 Ray,然后启动远程 TaskRunner。verl/trainer/main_ppo.py:107-187TaskRunner建立 role 到 worker class、role 到 resource pool 的映射。verl/trainer/main_ppo.py:219-311TaskRunner.run()创建 tokenizer、dataset、resource pool manager、RayPPOTrainer,然后调用 init_workers()和 fit()。verl/trainer/ppo/ray_trainer.py:688-884RayPPOTrainer.init_workers()把配置和资源池变成 WorkerGroup、LLM server manager、AgentLoopManager、CheckpointEngineManager。verl/trainer/ppo/ray_trainer.py:1274-1583RayPPOTrainer.fit()写出 PPO 的高层 dataflow。verl/workers/engine_workers.py:631-650和 verl/single_controller/ray/base.py:48-66worker 方法用 @register声明分布式调用规则;WorkerGroup 调用时执行 dispatch、remote、collect。下面这张图只解决一个问题:从入口脚本走到 PPO 主循环,中间经过哪些源码层。
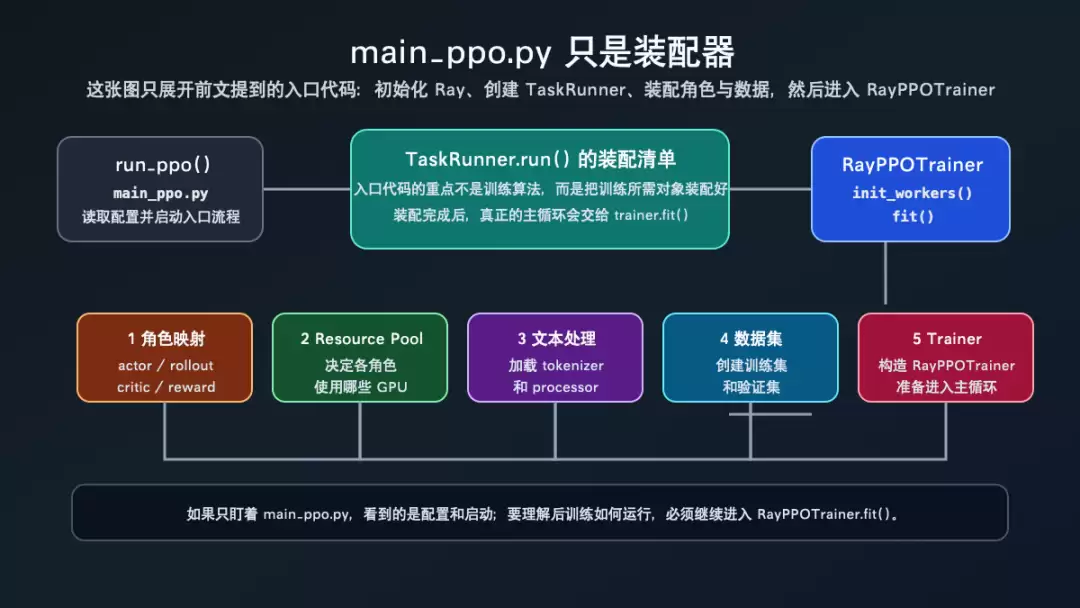
verl 源码阅读地图
图后要记住三层分工:
main_ppo.py是启动和装配层,不是训练算法层。init_workers()是系统对象初始化层,把资源、worker 和 manager 接起来。fit()是算法 dataflow 层,读者应该在这里看 PPO/GRPO 的阶段顺序。装配层:先有 role,再有 resource pool
TaskRunner的职责不是训练,而是先把 RLHF 里的 high-level operator 角色化。
源码里有两个核心字典:
代码语言:javascript复制self.role_worker_mapping = {}self.mapping = {}
role_worker_mapping回答“哪个 role 使用哪个 worker class”。
mapping回答“哪个 role 放进哪个 resource pool”。
在当前代码里:
actor/rollout/ref 走ActorRolloutRefWorker,默认映射到 global_pool,见 verl/trainer/main_ppo.py:122-142。critic 走 TrainingWorker,默认也映射到 global_pool,见 verl/trainer/main_ppo.py:144-152。reward model 和 teacher model 先登记资源池映射,不在这里注册训练 worker,见 verl/trainer/main_ppo.py:189-208。init_resource_pool_mgr()用 GPU 数量和节点数创建 ResourcePoolManager,见 verl/trainer/main_ppo.py:154-187。下面这张图要看 role、resource pool、WorkerGroup 的边界。它不是在说所有角色必须 colocate,而是在说 controller 首先看到的是角色和资源池,而不是裸 Ray actor。
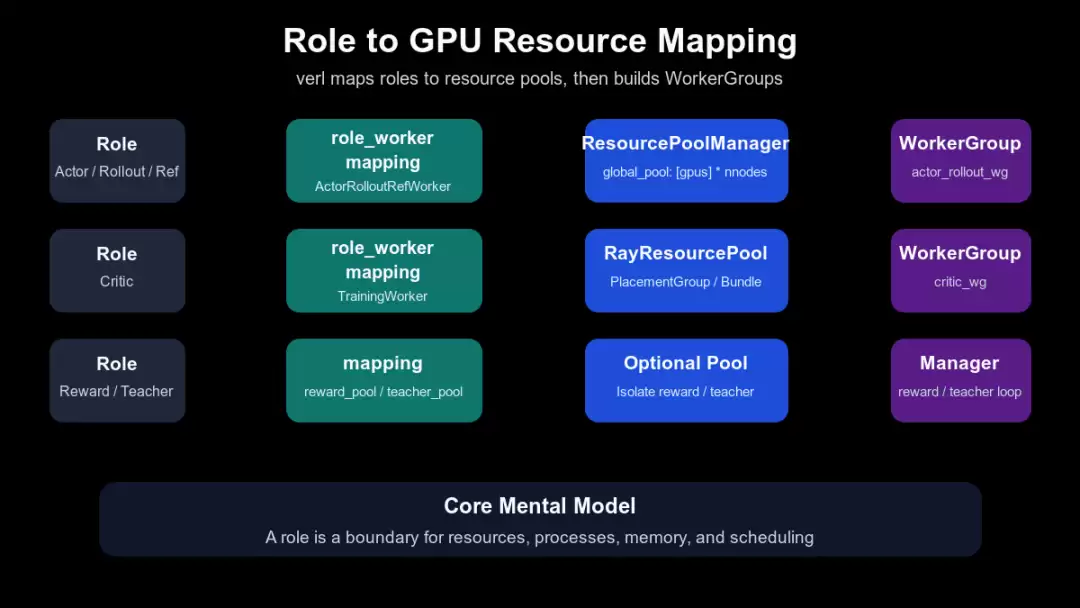
TaskRunner 中的角色到资源映射
图后的设计含义是:算法主循环不直接关心 rank、进程和 GPU 拓扑。它只需要知道 actor、critic、ref、reward、rollout 这些 high-level operator 是否已经被装配成可调用对象。
init_workers():把配置变成可调用系统
RayPPOTrainer.init_workers()是从“配置描述”走向“可调用系统”的地方。
它先创建资源池和 role/class 映射:
self.resource_pool_manager.create_resource_pool():verl/trainer/ppo/ray_trainer.py:695self.resource_pool_to_cls = ...:verl/trainer/ppo/ray_trainer.py:697actor/rollout/ref 放入 actor resource pool:verl/trainer/ppo/ray_trainer.py:699-709critic 被转换成 TrainingWorkerConfig后放入 critic resource pool:verl/trainer/ppo/ray_trainer.py:713-738然后创建 WorkerGroup:
代码语言:javascript复制create_colocated_worker_cls(class_dict)-> RayWorkerGroup(resource_pool, ray_cls_with_init)-> spawn(prefix_set=class_dict.keys())
对应 verl/trainer/ppo/ray_trainer.py:773-783。
后半段再接入推理和环境侧组件:
RewardLoopManager:verl/trainer/ppo/ray_trainer.py:812-822LLMServerManager.create(...):verl/trainer/ppo/ray_trainer.py:854-856AgentLoopManager.create(...):verl/trainer/ppo/ray_trainer.py:863-868CheckpointEngineManager(...):verl/trainer/ppo/ray_trainer.py:870-884这解释了为什么主循环里的一句 generate_sequences(...)不是普通 model.generate()。它背后已经接上了 rollout server、agent loop、reward loop、teacher client 和 checkpoint replicas。
fit():PPO dataflow 被写成单进程程序
现在进入第二篇的核心:RayPPOTrainer.fit()。
它的 docstring 说明 driver process 通过 RPC 调 worker group 的 compute functions 来构造 PPO dataflow,轻量 advantage computation 在 driver process 上完成,见 verl/trainer/ppo/ray_trainer.py:1274-1279。
下面这张图要看 DataProto 如何在一个 step 里不断增加字段。rollout 增加 response,reward 增加 score,logprob/value 增加训练信号,advantage 把这些信号变成 update 所需字段。
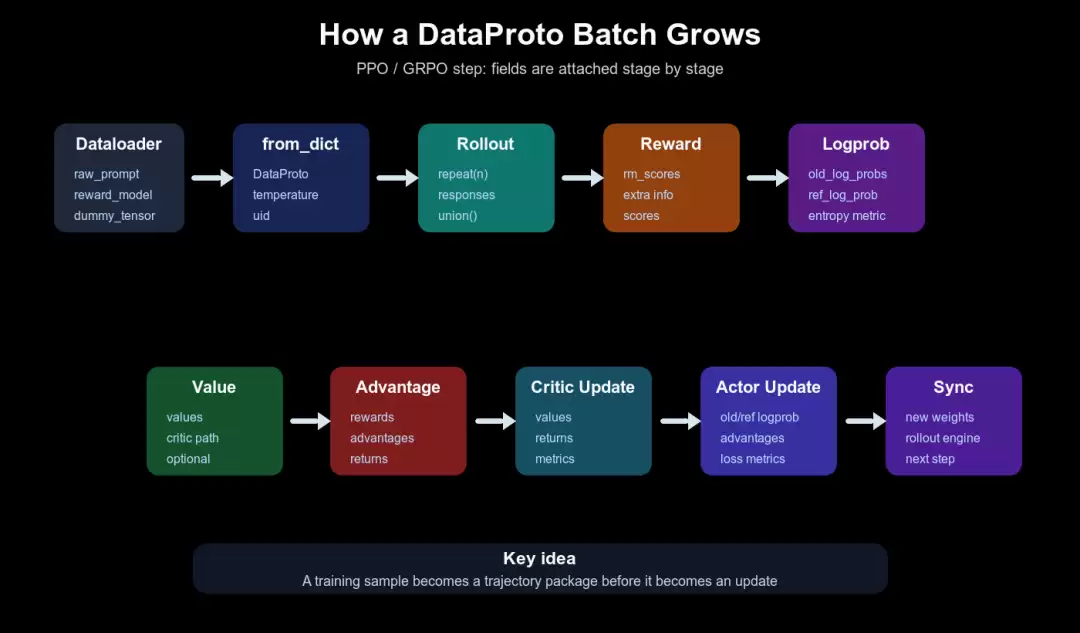
PPO 主循环里的高层 dataflow
图后的源码路线可以压缩成:
代码语言:javascript复制DataProto.from_single_dict(batch_dict)-> _get_gen_batch-> repeat rollout.n-> async_rollout_manager.generate_sequences-> batch.repeat batch.union(response)-> reward-> _compute_old_log_prob-> _compute_ref_log_prob-> _compute_values-> compute_advantage-> _update_critic-> _update_actor-> checkpoint_manager.update_weights
这些步骤集中在 verl/trainer/ppo/ray_trainer.py:1330-1583。
这里有几个分支要注意,但不需要在第二篇展开:
REMAX 会把 sampled rollout 和 greedy baseline 合并进同一次生成请求,见verl/trainer/ppo/ray_trainer.py:1358-1390。rollout correction 可以选择 bypass 或 recompute old logprobs,见 verl/trainer/ppo/ray_trainer.py:1435-1482。ref policy、critic 都是按配置条件执行,见 verl/trainer/ppo/ray_trainer.py:1484-1494。actor 更新后,checkpoint_manager.update_weights(...)把训练侧权重同步给 rollout replicas,见 verl/trainer/ppo/ray_trainer.py:1581-1583。这些分支说明 fit()不是一个死板脚本,而是高层 dataflow 的编排位置。
_compute_*:controller 和 worker 的桥
fit()里会调用几类短函数:
self._compute_old_log_prob(batch)self._compute_ref_log_prob(batch)self._compute_values(batch)self._update_actor(batch)self._update_critic(batch)
这些函数不是重计算本身。它们的职责是把 controller 侧的 DataProto转成 worker 侧更适合消费的 TensorDict,设置 meta 信息,调用 WorkerGroup,再把返回结果包回 DataProto。
下面这张图要看数据类型和职责变化:fit()持有 DataProto,_compute_*转成 TensorDict,WorkerGroup 返回 logprob/value/metrics,结果再回到 DataProto。
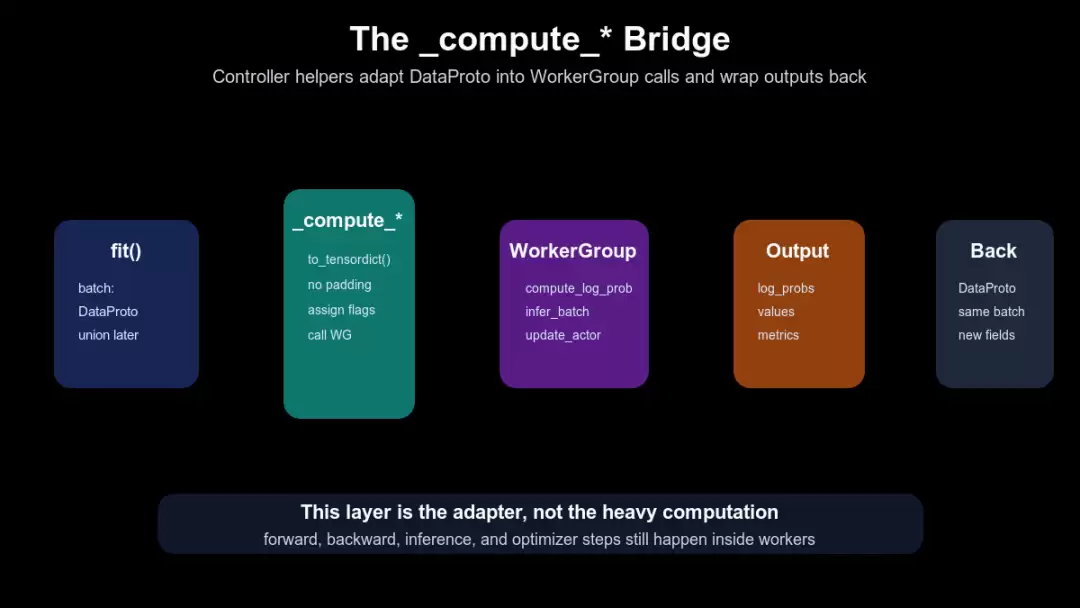
controller helper 如何桥接 DataProto 和 WorkerGroup
以 _compute_old_log_prob()为例,源码路径是:
batch.to_tensordict():verl/trainer/ppo/ray_trainer.py:1171left_right_2_no_padding(...):verl/trainer/ppo/ray_trainer.py:1173tu.assign_non_tensor(...):verl/trainer/ppo/ray_trainer.py:1176-1181self.actor_rollout_wg.compute_log_prob(batch_td):verl/trainer/ppo/ray_trainer.py:1182DataProto.from_tensordict(...):verl/trainer/ppo/ray_trainer.py:1201-1202同样的桥接模式也出现在 _compute_ref_log_prob()、_compute_values()、_update_actor()、_update_critic(),集中在 verl/trainer/ppo/ray_trainer.py:1130-1272。
这说明 controller 不做 actor forward/backward,也不做 critic forward/backward。controller 做的是准备 batch、选择阶段、调用对应 WorkerGroup、合并返回结果。
@register:普通方法调用背后的分布式协议
桥的另一端,是 worker 方法上的 @register。
ActorRolloutRefWorker里有三个关键方法:
@register(dispatch_mode=make_nd_compute_dataproto_dispatch_fn(mesh_name="ref"))def compute_ref_log_prob(...)@register(dispatch_mode=make_nd_compute_dataproto_dispatch_fn(mesh_name="actor"))def compute_log_prob(...)@register(dispatch_mode=make_nd_compute_dataproto_dispatch_fn(mesh_name="actor"))def update_actor(...)
对应 verl/workers/engine_workers.py:631-650。
下面这张图要看三层关系:worker 源码上有装饰器,装饰器把 dispatch/execute/blocking 元信息挂到方法上,controller 侧看到的是一个普通方法调用。

register 如何把 worker 方法变成分布式接口
图后的关键源码是:
register()在 verl/single_controller/base/decorator.py:398-444,它给方法挂上 dispatch_mode、execute_mode、blocking。make_nd_compute_dataproto_dispatch_fn(mesh_name)在 verl/single_controller/base/decorator.py:300-304,它返回 mesh-specific dispatch/collect 函数。func_generator()在 verl/single_controller/ray/base.py:48-66,它实际执行 dispatch、Ray remote execute、collect 和可选 unpad。因此 controller 写:
代码语言:javascript复制self.actor_rollout_wg.compute_log_prob(batch_td)
背后发生的是:
代码语言:javascript复制dispatch_fn-> execute_fn(method_name, ...)-> optional ray.get-> collect_fn-> unpad if needed
下一篇讲 single_controller,就是要把这条链路拆开。
DataProto:高层 dataflow 里流动的是训练证据
DataProto是 controller 侧 dataflow 的标准容器。它的定义在 verl/protocol.py:318-328,由三部分组成:
batch: TensorDictnon_tensor_batch: dictmeta_info: dict
下面这张图要和 fit()里的 batch.union(...)一起读。DataProto 不只是装 tensor;它还要让 uid、reward extra info、temperature、global step、metrics 等上下文和 tensor 字段保持同一个 batch 轴。

DataProto 的三层结构
在第二篇里,需要记住 DataProto 的五个动作:
from_single_dict()把 dataloader 输出变成 DataProto,见 verl/protocol.py:480-493。repeat()支持 rollout.n多采样,见 verl/protocol.py:971-1100。union()把每个阶段的新字段合回 batch,见 verl/protocol.py:781-798。chunk()/ concat()支持切分和合并,见 verl/protocol.py:864-961。to_tensordict()支持进入 worker 前转换视图,见 verl/protocol.py:1102-1126。这就是为什么本文把 DataProto 称为“训练证据”的载体。rollout 后有 response;reward 后有 score;logprob/value 后有 policy/value 信号;advantage 后才有 actor/critic update 所需字段。
取舍:可读算法流换来中心化数据往返
到这里可以回到设计取舍。
HybridFlow 的收益是:算法顺序集中在 fit(),计算后端被 worker 抽象隔离,角色和资源可以通过 mapping 重放置。docs/hybrid_flow.rst:203-206也把“更换 computation backend”和“更改 WorkerGroup/ResourcePool placement”列为这个范式的 takeaway。
但收益不是免费的。本地文档 docs/hybrid_flow.rst:75-79已经指出,separate control flow and computation flow 会带来额外数据通信开销。
下面这张图要看四类成本:字段增长、object columns、序列化、对齐风险。它不是说 DataProto 设计错误,而是在提醒读者:统一协议越有用,它经过 controller 时也越可能变重。
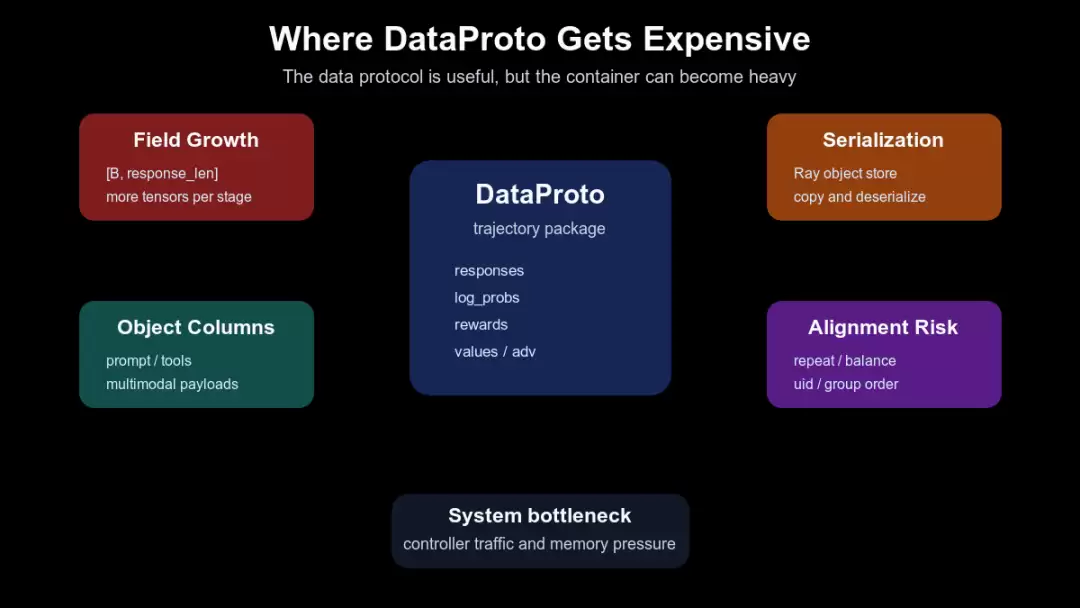
controller 中心化带来的 DataProto 瓶颈
源码里的表现很具体:
rollout 结果回到 controller,再通过batch.union(gen_batch_output)合并,见 verl/trainer/ppo/ray_trainer.py:1404-1406。reward、old logprob、ref logprob、values 都会把结果合回 batch,见 verl/trainer/ppo/ray_trainer.py:1426-1494。advantage 在 driver/controller 上计算,见 verl/trainer/ppo/ray_trainer.py:1496-1541。actor/critic update 的 metrics 回到 controller,见 verl/trainer/ppo/ray_trainer.py:1543-1586。actor 更新后还要同步权重给 rollout replicas,见 verl/trainer/ppo/ray_trainer.py:1581-1583。所以这篇文章的判断可以更精确地写成:
HybridFlow 用 controller 上的可读算法流程,换取了更多跨 worker 的数据往返、collect 等待和协议字段管理成本。
这不是缺点清单,而是理解 verl 后续文章的入口。第三篇讲 single_controller,就是要看这种“普通方法调用”的成本和收益如何在 dispatch/collect 层落地。
小结:第二篇只需要记住这条边界
读完第二篇,应该记住三句话:
代码语言:javascript复制RayPPOTrainer.fit()写 RLHF/PPO 的高层 dataflowWorkerGroup @register把 high-level operator 变成分布式执行DataProto / TensorDict在 controller 和 worker 之间携带训练证据
回到本系列地图,第一篇解释了为什么 AI 后训练不是一个训练脚本;第二篇把这个系统拆成 dataflow、controller、worker 和协议边界。下一篇进入 Single Controller:一次看似普通的 Python 方法调用,如何变成一组 Ray worker 上的 dispatch、execute、collect。
本文源码索引
概念文档:
docs/hybrid_flow.rst:45-79:control flow / computation flow 和 verl 的分离策略。docs/hybrid_flow.rst:160-177:dispatch、collect 和 @register的文档解释。docs/hybrid_flow.rst:180-206:PPO 主循环示意和 takeaways。入口和装配:
verl/trainer/main_ppo.py:48-98:run_ppo()初始化 Ray 并启动远程 TaskRunner。verl/trainer/main_ppo.py:107-187:TaskRunner的 role mapping 和 resource pool mapping。verl/trainer/main_ppo.py:219-311:TaskRunner.run()装配 dataset、resource pool、trainer,并调用 init_workers()/ fit()。verl/trainer/ppo/ray_trainer.py:688-884:init_workers()创建 WorkerGroup、reward loop、LLM server、agent loop 和 checkpoint manager。PPO 主循环:
verl/trainer/ppo/ray_trainer.py:1274-1279:fit()docstring 对 PPO dataflow 的说明。verl/trainer/ppo/ray_trainer.py:1330-1406:dataloader batch、uid、rollout、repeat、union。verl/trainer/ppo/ray_trainer.py:1426-1541:reward、old logprob、ref logprob、values、advantage。verl/trainer/ppo/ray_trainer.py:1543-1583:critic update、actor update、weight sync。controller 到 worker:
verl/trainer/ppo/ray_trainer.py:1130-1272:_compute_values()、_compute_ref_log_prob()、_compute_old_log_prob()、_update_actor()、_update_critic()。verl/workers/engine_workers.py:76-81:TrainingWorker的定位。verl/workers/engine_workers.py:238-385:TrainingWorker的 train_mini_batch()、train_batch()、infer_batch()。verl/workers/engine_workers.py:439-650:ActorRolloutRefWorker的 actor/ref/rollout 组合和 high-level methods。协议和分发:
verl/protocol.py:318-328:DataProto 三层结构。verl/protocol.py:480-493:from_single_dict()。verl/protocol.py:781-798:union()。verl/protocol.py:864-961:chunk()/ concat()。verl/protocol.py:971-1100:repeat()。verl/protocol.py:1102-1126:to_tensordict()。verl/single_controller/base/decorator.py:300-304:mesh-specific DataProto dispatch/collect 函数生成。verl/single_controller/base/decorator.py:398-444:register()给 worker method 挂分布式元信息。verl/single_controller/ray/base.py:48-66:func_generator()执行 dispatch、remote、collect。本文参与腾讯云自媒体同步曝光计划,分享自微信公众号。原始发表:2026-06-18,如有侵权请联系[email protected] 删除