Claude团队引众怒:为爬数据不择手段:给爬虫改名字无视禁止规则
许多网友为此愤愤不平,有个搞文案工作的网友留言称:
“我建议用‘偷’,而不是‘不付费’来描述Anthropic的这种行为。”
一时之间,群情激愤!
支持声讨的,要求Claude付费的,评论区简直乱成一锅粥了。
这是怎么回事
强烈谴责Anthropic的这家公司叫做iFixit,是一家美国电子商务和操作指南网站。
iFixit的业务的一部分,是为消费电子产品和小工具提供类维基百科的免费在线维修指南。
网站内有数百万个页面,包括修理指南、指南的修订历史、博客、新闻帖子和研究、论坛、社区贡献的修理指南和问答部分等。
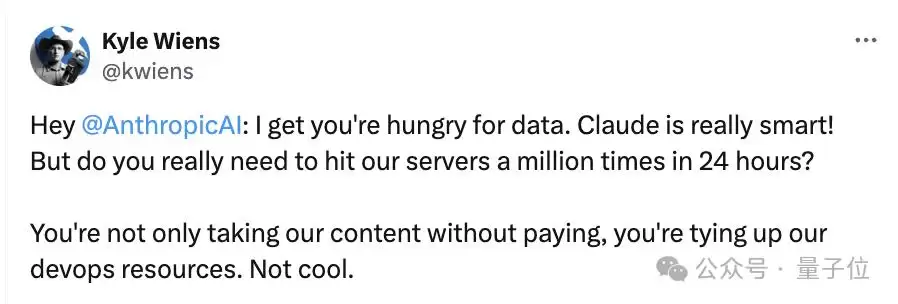
但,iFixit突然发现,Claude的爬虫程序ClaudeBot在几个小时内,每分钟都有数千次请求访问。
这约等于一天内访问其网站近百万次。
据统计,它一天内访问了10 TB的文件,整个5月份总计访问了73 TB。

为此,iFixit的CEO老K(Kyle Wiens)丢下一句话:
对你没看错,「未经许可」。
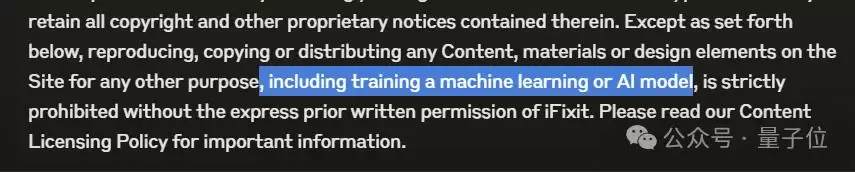
iFixit其实有写声明——
未经iFixit明确事先书面许可,严禁因为任何其他目的(包括训练机器学习或人工智能模型)复制、复制或分发本网站上的任何内容、材料或设计元素。
然并卵。
Claude不仅视若无睹地继续疯狂访问-抓取,还躲避了iFixit的防御。
iFixit其实成功阻止了两个Anthropic的AI抓取机器人,分别名为“ANTHROPIC-AI”和“CLAUDE-WEB”。
但这俩AI抓取机器人似乎已经是过去式了,目前的主力爬虫正是没被阻止成功的“ClaudeBot”。
逼不得已,老K表示,iFixit本周修改了robots.txt文件,专门用来阻止Anthropic的爬虫机器人。

那,Anthropic那边有啥反应不?
它们倒是没有闭麦,对媒体回应道:
当然了,Anthropic回避了现在活跃的ClaudeBot是否尊重防爬虫robots.txt阻止被爬取的问题。
AI公司不是第一次干这事儿了
翻看Anthropic的官方网站可以发现,早就挂着一篇名为《Anthropic是否从网络上抓取数据?网站所有者如何阻止抓取工具?》的文章。
里面提到:
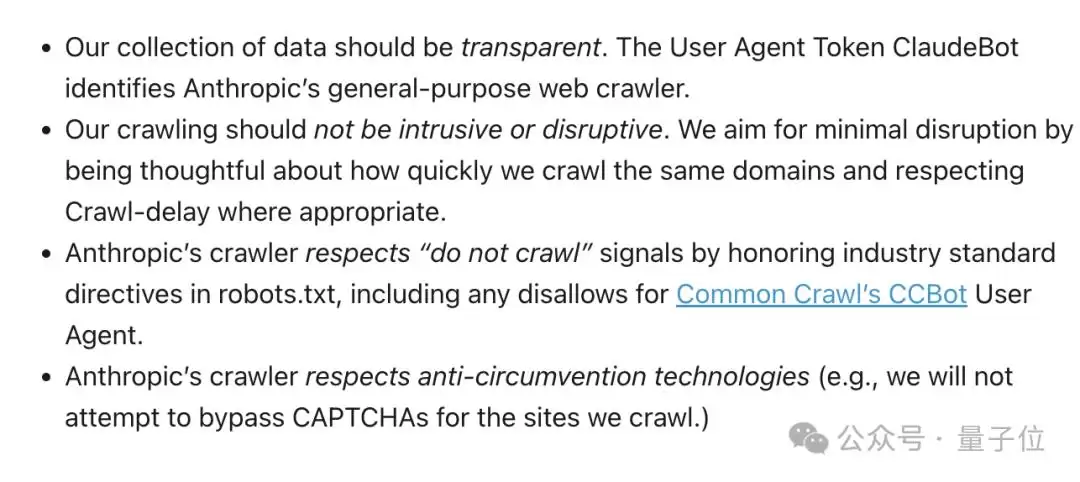
但一片舆论声中不难发现,Anthropic显然不是这么做的。
它,未经允许爬取别人数据,老惯犯了。
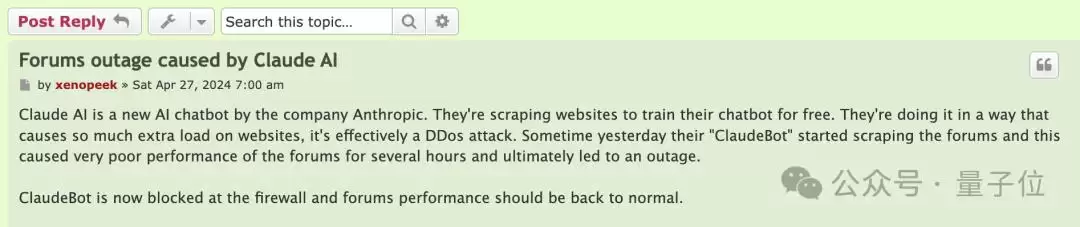
就说今年4月的时候,Linux Mint论坛就惨遭被爬。
在几个小时中,ClaudeBot多次访问论坛爬取数据,导致论坛在几个小时内处于超低速or崩溃状态,最终完全崩掉。
有人表示,在同一时间内,ClaudeBot占用的流量独占鳌头,是第二名的20倍、第三名的40倍。
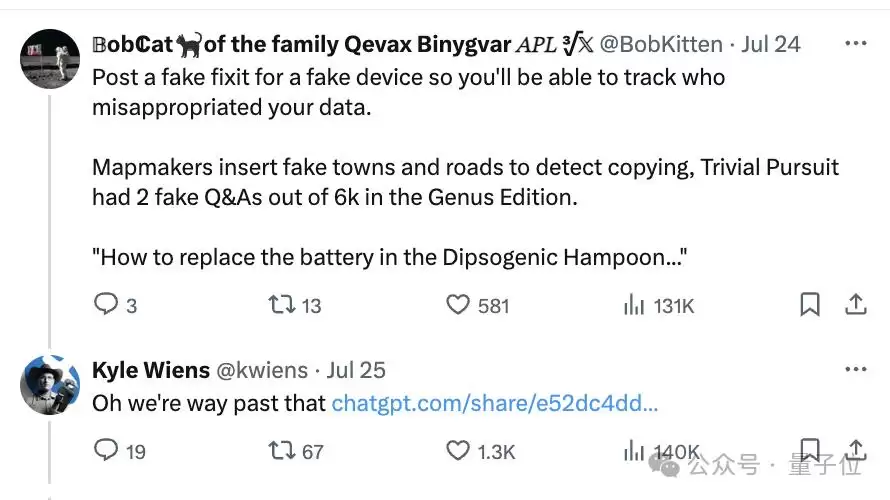
在4月事件和本次事件的讨论贴中,都有人建议:
iFixit确实也这么做了。
而且真的有用——发现自家网站的信息不仅被Claude爬个底朝天,还被OpenAI也爬走了……
讲道理,有什么办法呢?真的一点办法也没有。
因为除了Claude和GPT以外,这样强行偷家的AI挺不少的。
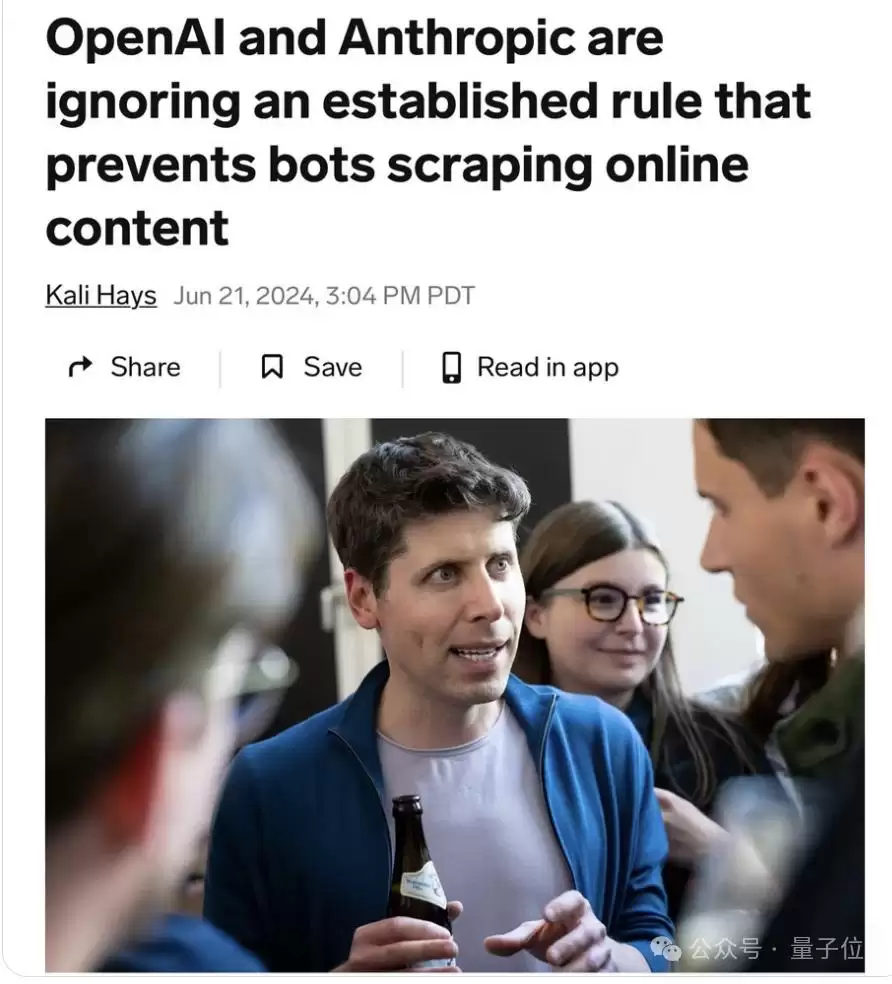
前几天就有一家名为Tollbit的机器人检测初创公司声称Perplexity、Claude、OpenAI会忽略爬取网站上的robots.txt设置——当时有人跑去问了OpenAI的态度,OpenAI不予置评。
再往前看,上个月也闹过一次。
《福布斯》谴责AI搜索产品Perplexity涉嫌抄袭其新闻文章;一石激起千层浪,更多媒体站出来,指责Perplexity的爬虫机器人PerplexityBot非法抓取自家网站信息。
而Perplexity一直的态度都是:
理论上讲,不管是ClaudeBot还是PerplexityBot,在遇到标明“禁止抓取”“禁止robot.txt”的文件时,都应该遵从协议,规避爬取声明方网站的内容。
既然声明无效,就有人呼吁创作者把内容尽可能转移到付费区域,来防止无限制的抓取。
你觉得这样的办法会有效吗?
参考链接:
[1]https://www.404media.co/websites-are-blocking-the-wrong-ai-scrapers-because-ai-companies-keep-making-new-ones/
[2]https://www.404media.co/anthropic-ai-scraper-hits-ifixits-website-a-million-times-in-a-day/
[3]https://twitter.com/kwiens/status/1816128302542905620
[4]https://x.com/Carnage4Life/status/1804316030665396356
[5]https://support.anthropic.com/en/articles/8896518-does-anthropic-crawl-data-from-the-web-and-how-can-site-owners-block-the-crawler?ref=404media.co