SemanticAudio - 港中文等研发的音频生成与编辑框架
作者:袖梨
2026-07-05
SemanticAudio是什么
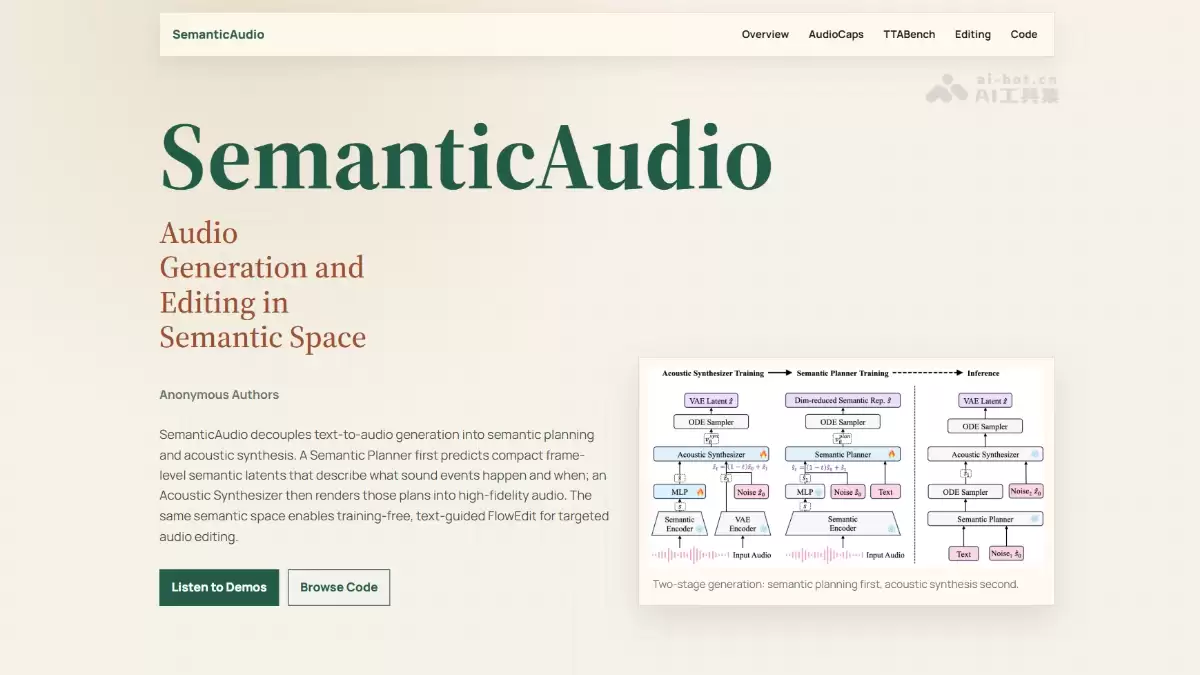
SemanticAudio 是香港中文大学、LIGHTSPEED、上海交通大学联合推出的音频生成与编辑框架。框架将文本到音频生成拆分为”语义规划”与”声学合成”两阶段,在高层语义空间规划声音事件的身份、时序与结构,再渲染为高质量音频。框架支持无需训练的文本引导音频编辑,在 AudioCaps 和 TTABench 基准上均显著优于 TangoFlux 等主流方法,实现语义对齐与生成质量的双重提升。
SemanticAudio的主要功能
- 文本到音频生成:输入自然语言描述,生成环境声、动作声、复杂声音场景等高质量音频。
- 语义规划生成:在高层语义空间规划声音事件的全局布局,再合成声学细节。
- 无需训练音频编辑:通过 FlowEdit ODE 机制,直接在语义空间中修改声音属性,支持替换、调整等操作。
- 帧级语义嵌入:提取保留时间结构的语义表示,精准描述复杂音频中的事件顺序和局部变化。
SemanticAudio的技术原理
- 两阶段 Flow Matching 架构:SemanticAudio 将音频生成拆分为语义规划与声学合成两阶段,Semantic Planner 先从文本生成紧凑语义表示,描绘声音事件的全局布局。Acoustic Synthesizer 再用该语义计划为条件,生成高质量声学潜变量并解码为音频。解耦使模型分工明确,避免单阶段模型在声学空间中同时处理语义理解与声学渲染的耦合问题。
- 语义空间的构建与压缩:用 Perception Encoder 提取帧级语义嵌入以保留时间结构,再通过轻量 MLP 压缩至 128 维。低维语义空间既保留关键声音身份与时序信息,又能被 Flow Matching 模型高效学习,成为连接文本语义与声学细节的关键中间层。
- FlowEdit ODE:用源文本与目标文本的速度场差异引导语义轨迹编辑,将源音频编码为语义潜变量,计算两文本的速度场差值确定编辑方向,执行 ODE 步进得到目标语义表示,再经声学合成器还原。编辑在高层语义空间进行,无需额外训练、反演或配对数据,即可实现属性级修改。
- 语义-声学解耦的核心价值:显式解耦使模型先在语义空间规划多事件身份与时序,再合成声学细节,避免复杂提示词下的事件缺失与顺序错误。语义空间为编辑提供更清晰、可解释的操作对象,修改更接近”改变声音内容本身”,实现更稳定灵活的文本引导修改。

微信关注回复“开源”,加入AI开源项目交流群
如何使用SemanticAudio
- 访问 Demo 页面:打开 https://semanticaudio1.github.io/ 体验在线演示。
- 输入文本提示:描述目标声音场景,如”狗叫之后传来汽车鸣笛”。
- 语义规划:Semantic Planner 生成紧凑语义表示,规划声音事件布局。
- 声学合成:Acoustic Synthesizer 将语义计划渲染为高质量音频。
- 音频编辑(可选):输入源音频和目标文本,用 FlowEdit ODE 在语义空间中修改声音属性。
SemanticAudio的核心优势
- 语义对齐显著提升:通过先规划语义布局再合成声学细节,AudioCaps LAION-CLAP 达到 0.381,优于 TangoFlux 的 0.361,复杂提示词理解更准确。
- 无需训练即可编辑:FlowEdit ODE 机制利用速度场差异在语义空间中引导轨迹,支持属性级修改,CLAP 提升 +0.094,优于同类方法且无需额外训练。
- 生成质量与可控性兼顾:FD 19.1、MOS 3.72,在显著提升文本-音频语义对齐的同时保持高保真听感质量。
- 复杂提示词处理强:显式规划多事件身份与时序关系,有效避免事件缺失、顺序错误和文本对齐不足等问题。
- 更符合人类创作流程:采用先规划声音场景结构再补充声学细节的范式,实现想清楚再说出来的生成方式。
SemanticAudio的同类竞品对比
维度SemanticAudioTangoFlux架构两阶段(语义规划+声学合成)单阶段声学空间生成语义对齐LAION-CLAP 0.381LAION-CLAP 0.361编辑能力无需训练,属性级修改需 FlowEdit 适配,效果较弱复杂提示词显式规划时序,不易出错易遗漏事件或混淆顺序生成质量FD 19.1,MOS 3.72FD 22.6核心差异语义-声学解耦,先想后说直接在声学空间建模SemanticAudio的应用场景
- 影视后期:根据剧本中的自然语言描述,SemanticAudio 可生成包含多个声音事件且时序精准的复杂音效场景,提升后期制作效率。
- 游戏开发:针对不同游戏场景,开发者通过文本指令动态生成匹配的环境音与动作音效,实现音频内容的快速迭代。
- 内容创作:短视频、播客等创作者输入描述即可快速获得定制化音频素材,降低专业音频制作门槛。
- 虚拟现实:系统根据用户的自然语言指令实时生成沉浸式环境音,增强虚拟空间的临场感与交互体验。
- 音频编辑工具:用户用自然语言直接修改现有音频的属性或替换声音事件,无需训练可完成专业级编辑。
相关文章
-
Day 2:Function Calling究竟是什么?跟着AI老师从笨办法开始写
游戏攻略 2026-07-05
-
欢迎报名丨2026 Agentic AICon—智能体基础设施与 AgentOps 专场 邀您参会
游戏攻略 2026-07-05
-
项目实战:合同智能审批 结合 LangGraph + HITL 人机协同方案 [有源码]
游戏攻略 2026-07-05
-
实战揭秘:怎样让AI Agent在真实会话中“自我进化”并实现经验共享?
游戏攻略 2026-07-05
-
接口即代码:一个Skill轻松搞定类型定义:接口调用:Mock与调试
游戏攻略 2026-07-05
-
hbase大数据运用场景
游戏攻略 2026-07-05