你还在古法PPT吗:试试HTML呢?免费编辑导出工具给 xdm 放这了
最近我自己踩了个坑,后来想明白了,顺手做了个小工具,再顺手把过程整理一下,希望对你有用。
事情是这样的:过去一年多,「让 AI 直接用 HTML 写幻灯片」其实已经悄悄变成一种很主流的工作方式了。各种大模型写 Flex/Grid 排版、KaTeX、Mermaid、自定义字体都很强,但要它们去写原生 PowerPoint 那套 XML,是真的烂。所以越来越多人干脆让 AI 产一个好看的 deck.html,而不是回去跟 Keynote 较劲。
但只要你真的这么干过几次,就会发现每次都撞上同一堵墙。AI写起来容易,改起来费劲。这都是朕的Token,朕的钱!!
当然也有朋友让AI直接全做成图,但改起来仍然很烦。可能改几个字还有反复对话框修改沟通,无尽循环。 所以太烦了然后抽空做了个东西叫 NextPPT
- 官网 next-ppt.com,
- 代码开源在 github.com/Trade-Offf/…。
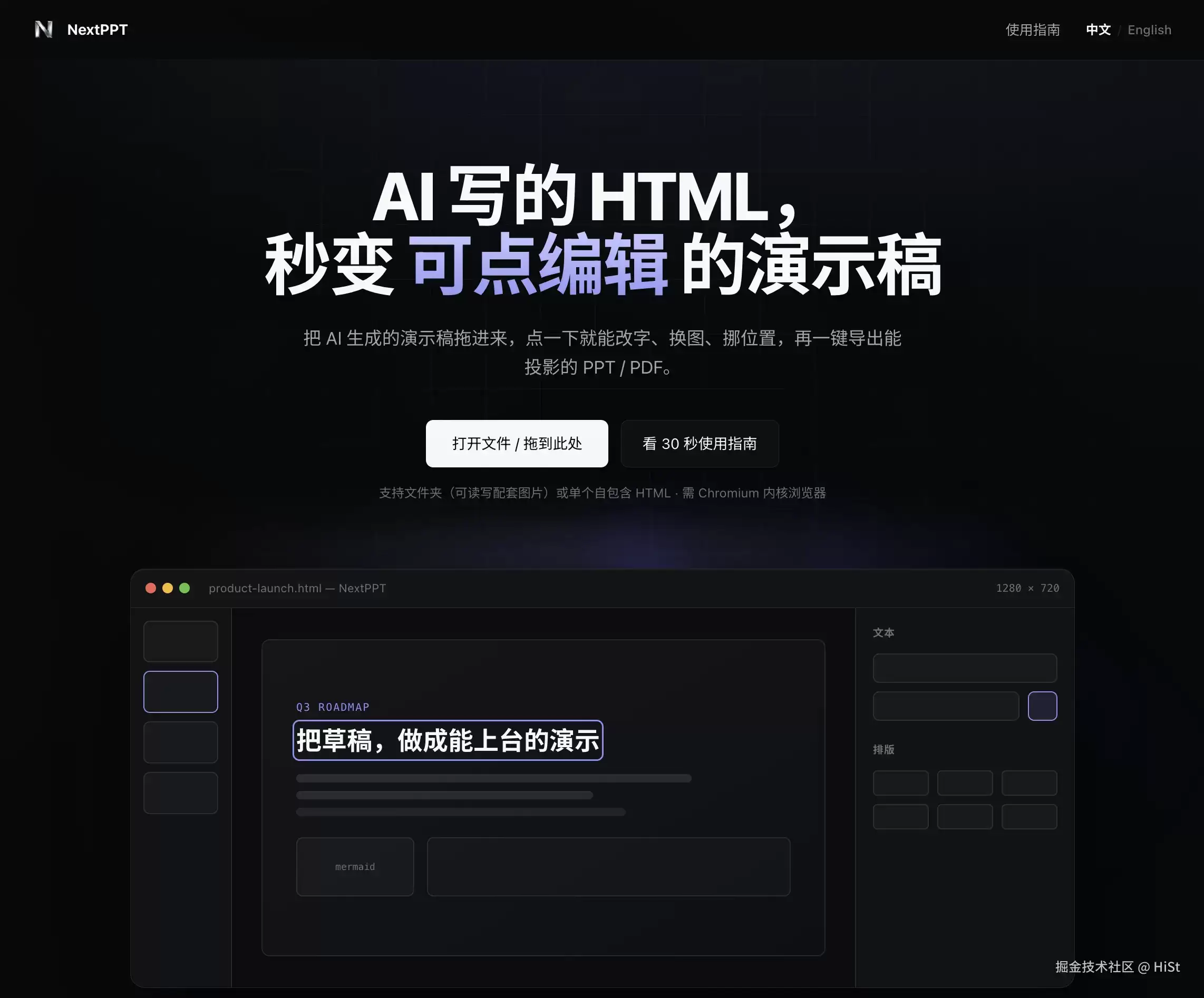
太长不读
- AI 很会生成漂亮的 HTML 演示稿,但改不动——改一个字就得回对话框重发 prompt、等、看 diff,token 哗哗烧。NextPPT 让你把 HTML 拖进浏览器,点哪改哪。
- 投影、提交、分享最终还是要 PPT/PDF,而 HTML 上投影仪爱掉字体、卡网络。NextPPT 一键导出高保真、图片型的 PPTX/PDF。
- 答辩稿、客户方案、内部资料,没人想传到在线编辑器。所以 NextPPT 编辑期全程在你本机,文件不上传。
- 能马上试的动作:用 Chrome/Edge 打开 next-ppt.com,拖一个
.html进去,点一下标题改两个字。三十秒就懂了。
下面从「为什么」一路讲到「怎么实现」和「怎么用」。这个观点只代表我自己,也不一定对。
一、先看为什么:问题的本质不是「做 PPT」,是「改 PPT」
我做工具有个习惯,先别急着想用什么技术栈,先问这个问题的本质是什么、用户真正的痛点在哪。
把 AI 写 HTML 幻灯片这件事拆开,你会发现痛点根本不在「生成」——生成这一步 AI 已经做得很好了。痛点全在生成之后:
- 临场改一句话太难受。 答辩前一晚导师说「第 16 页那句话改一下」,你又得回到 AI 工具:发 prompt、等、看 diff、保存。一次还好,第十次真的想骂人。更要命的是,AI 经常顺手把你没让它动的地方也「优化」了。
- 投影还是要 PPT/PDF。 学校要求交
.pptx,客户要.pdf,而 HTML 直接上投影仪,掉字体、卡 CDN、动画乱飞,是常态。 - 隐私是真的焦虑。 答辩稿、客户方案、内部资料,谁都不太敢传到一个不知道会不会拿去训练的云端编辑器里。
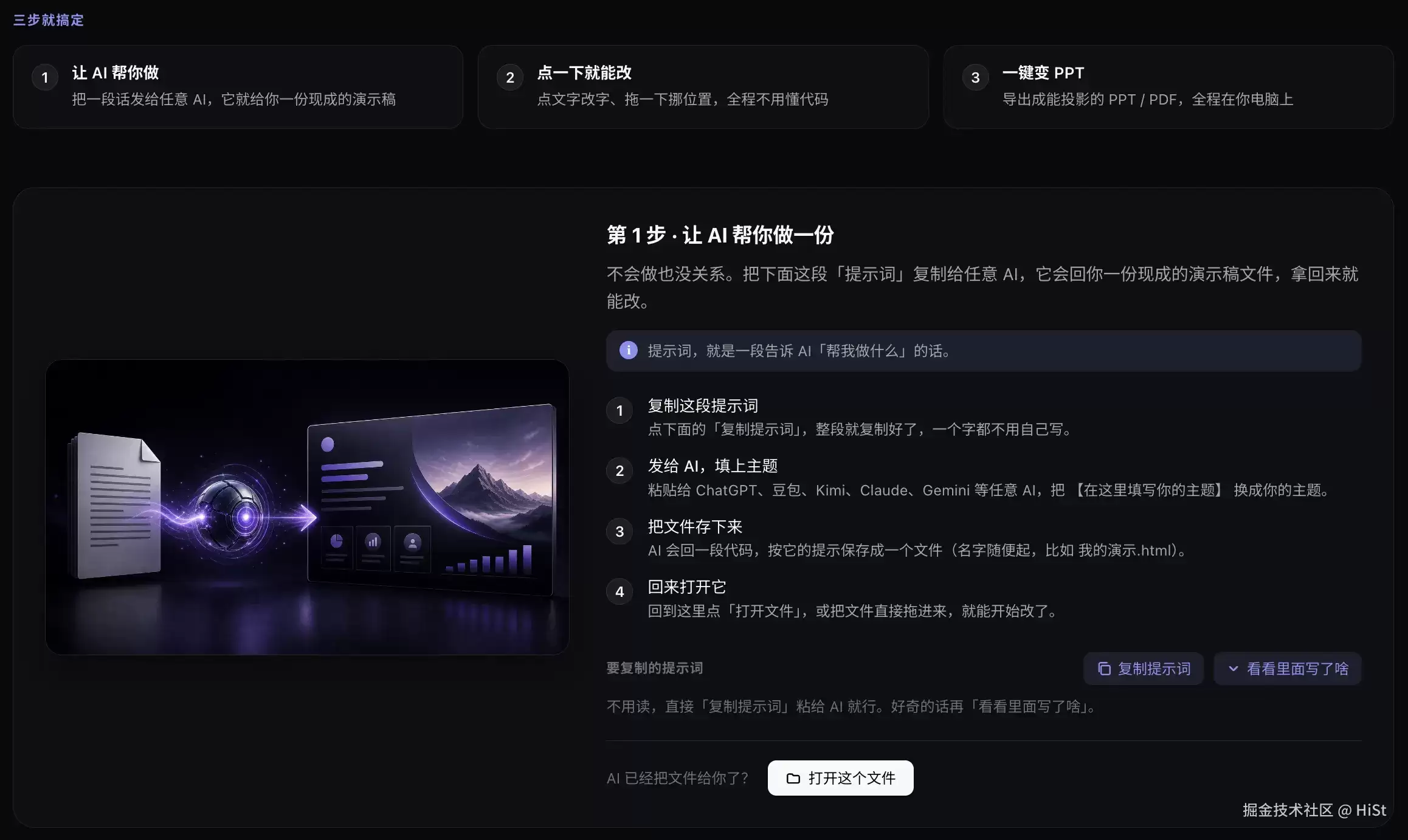 光是第一个痛点,循环起来就足够磨人——你想改的只是一句话,付出的却是一整圈:
光是第一个痛点,循环起来就足够磨人——你想改的只是一句话,付出的却是一整圈:
这三个痛点背后其实是同一件事在变:AI 把「从零到一」做便宜了,于是「从一到对」那段路,反而成了新的瓶颈。 大家都在卷怎么生成得更快更好看,却很少有人去管生成完之后那一地鸡毛。
想清楚这点,产品形态其实就定了:它不该是又一个 AI 生成器,而该是一把专门修剪 AI 演示稿的剪刀。
二、我砍掉了什么
我挺认同马斯克那套「五步工作法」的,尤其前两步——质疑每一项要求,然后大胆删掉。所以在动手之前,我先想清楚 NextPPT 不做什么:
- 不做 AI 生成 PPT。 生成交给任意 AI 就好,我只接管最后一公里。多做一个生成器,既卷不过大模型,又把产品做散了。
- 不做 reveal.js / Slidev 那种 DSL。 那些工具很好,但要重学一套语法。而 AI 吐出来的就是普通 HTML,我凭什么逼用户再学一门 DSL?任意
<section class="slide">结构都该能直接用。 - 不做云端编辑器。 一上云,隐私这条最硬的卖点就没了。
砍到最后,剩下的核心就一句话:拿你已经有的 HTML,在浏览器里点哪改哪,再导出一份高保真的 PPT/PDF——而且文件全程不离开你本机。
在 AI 让做加法变得几乎零成本的时代,功能是堆出来的,产品却是删出来的。一个工具真正的样子,往往不是由它能做什么定义的,而是由它坚决不做什么定义的。需求一旦砍干净,架构也就清爽了。
三、架构:一个编辑器 + 一个「即用即焚」的导出服务
整个系统就两块:一个浏览器 SPA 负责全部编辑;一个无状态服务只在你点「导出」那一下出现,干完活立刻把一切忘掉。
- 编辑全部在浏览器里,通过 File System Access API 直接读写本地文件,不上传。
- 导出才把内容送到一个短命的 Puppeteer worker:高 DPI 逐页截图、拼成 PPTX/PDF、回吐文件,然后把临时目录删干净。没有数据库,没有对象存储。
这个边界划分很关键:模型/服务端只负责一次性的、可丢弃的计算,状态全在用户本机。 说到底,最硬的隐私承诺,从来不是「我保证不看」,而是让系统压根没有看的能力——能力上的不能,永远比道德上的不愿更让人安心。

四、技术实现:几个我觉得有意思的点
1. 用 File System Access API 把「本地」做实
要做到「文件不离开本机」又「能自动保存」,靠的是浏览器的 File System Access API。它给了两种入口,对应两种真实场景:
- 文件夹模式:你选一个包含
deck.html和图片资源的目录,NextPPT 能读写同级图片、自动回写、保留备份。适合图文混排、资源较多的稿子。 - 单文件模式:直接拖进来一个自包含的
.html,编辑后另存为一份副本,图片以 base64 内联。适合「就一个文件」的轻量场景。
代价是这套 API 目前只有 Chromium 系(Chrome / Edge / Brave / Arc)支持,Safari/Firefox 还得等。这是个清醒的取舍:与其做一个处处妥协的全兼容方案,不如先把 Chromium 上的体验做到极致,ZIP 兜底以后再说。
2. 沙箱 iframe + 强类型 postMessage 协议
幻灯片本身是别人(AI)写的 HTML,里面可能有任意脚本。直接挂到主文档里既不安全、样式又会互相污染。所以每一页都渲染在一个沙箱 iframe(srcdoc,origin 是 null)里,主应用和 iframe 之间只通过 postMessage 通信。
通信协议我做成了强类型的,编辑这一侧的核心是一组 PatchOp:
export type PatchOp =
| { kind: 'text'; value: string }
| { kind: 'attr'; name: string; value: string | null }
| { kind: 'style'; name: string; value: string | null }
| { kind: 'class'; add?: string[]; remove?: string[] };
你在属性面板改字号、改颜色、改对齐,本质上都是往 iframe 发一条 patch 消息,里面带一个由 runtime 生成的稳定 CSS 选择器和一串 PatchOp。iframe 改完 DOM,再把整页最新的 outerHTML 回吐给主应用。整条链路没有任何「魔法」,就是感知 → 决策 → 行动 → 反馈这个朴素循环,只不过两端隔着一道安全边界:
这里其实最重要的不是协议写得多花,而是把选择器做稳:忽略布局占位符、优先用稳定 id,否则 patch 会打到错的元素上——这种 bug 比「功能没做」还难查。
3. 实时 iframe:自己改的不重载,别人改的才重载
最早我图样图森破,每收到一条 patched 就把 iframe 重新 render 一遍。结果就是:你刚选中一个元素,handle 一闪没了;刚插入一张图,还没来得及拖就被刷掉了。体验稀碎。
后来想明白了:iframe 应该是「活的」编辑现场,而不是一块被反复重绘的画布。
于是我把它改成:iframe 自己产生的改动(移动、缩放、改字、patch)绝不触发重载;只有「外部原因」才重新挂载——撤销/重做、恢复历史快照、切换页面。判断逻辑就是拿当前 HTML 和「上一次自己 patch 出来的 HTML」比一下,是自己改的就跳过 remount:
if (html !== prevHtmlRef.current) {
prevHtmlRef.current = html;
if (html !== lastPatchedHtmlRef.current) setCanvasKey((k) => k + 1);
}
这套「是不是自己改的」判断,画出来就一个分叉:
一个 canvasKey 控制 remount,配合「重载后用选择器把选区重新选回来」,体验一下就顺了。这种问题,模型再强也帮不上忙,得靠你对状态边界的工程判断。
4. 编辑 / 拖动双模式:要 PPT 的自由,也要不误触的安全
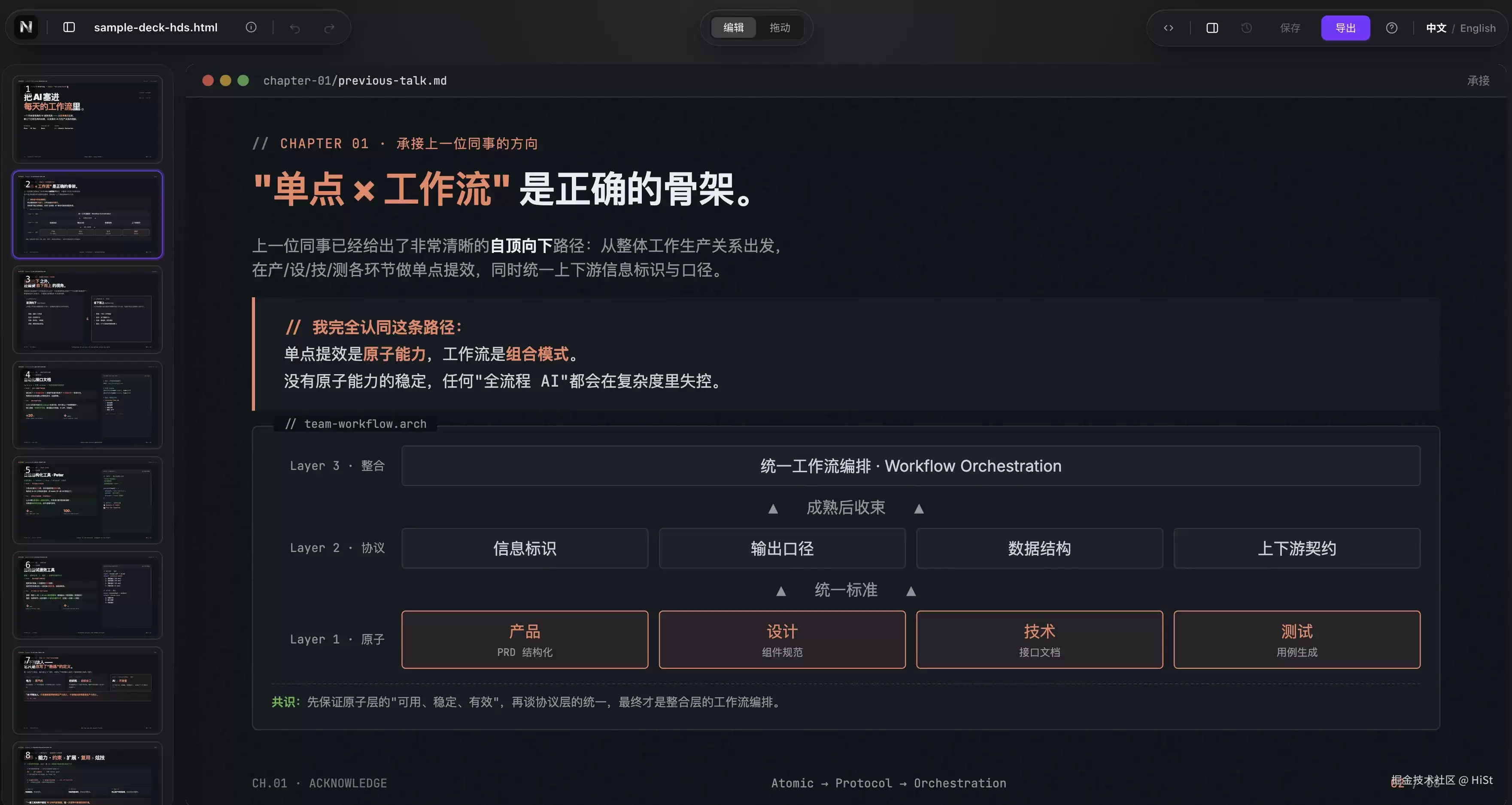
我想让每个元素都能像原生 PPT 那样自由拖动、缩放、删除。但马上就有矛盾:自由变换和「点文字改字」会互相打架——你想改个字,结果手一抖把整块挪走了。
我的解法是两个严格互斥的模式,顶部中间一个 pill 切换:
- 编辑模式:只能点选、双击文字行内编辑、用右侧属性面板。没有拖拽 handle,绝不会误移。
- 拖动模式:能移动、四角缩放、删除(带 handle)。但不能行内改字。
切到拖动模式去拽一个原本在文档流里的元素时,它会自动转成绝对定位(detach-on-grab)。这个边界是产品决策,不是技术限制——宁可让用户多点一下切个模式,也不要让他在「改字」时提心吊胆。
5. 资源解析:blob URL 和相对路径的双向翻译
文件夹模式下,图片在磁盘上是相对路径(assets/cover.png),但 iframe 里要显示得用 blob URL。于是我维护了一张 blob URL ↔ 相对路径的映射表:显示时把相对路径解析成 blob,导出/存盘时再翻译回相对路径。
这块踩过一个挺典型的坑,后面「踩坑」那节细说。
6. 历史快照:让用户「永远不怕改坏」
改动会防抖(1.5s)自动回写磁盘,同时在 .hds-backup/ 里留带时间戳的快照。任何时候都能从历史版本里把之前的样子捞回来。
这条看着不起眼,但它解决的是一个心理问题:人只有在「知道自己随时能反悔」的时候,才敢放心大胆地改。⌘Z 撤销、⇧⌘Z 重做、历史版本,三层兜底,原文件永远不会被你改坏。
7. 导出管线:Puppeteer 高 DPI 截图 → 图片型 PPTX/PDF
导出是唯一碰服务端的环节。思路很直白:把每一页当成一张高清照片拍下来,再拼进 PPTX/PDF。
为什么是「图片型」而不是去还原可编辑的 PPT 元素?因为高保真和「PPT 里还能改字」是冲突的,而用户的核心诉求是「长得和我的 HTML 一模一样」。所以我选了高保真,明确告诉用户:导出的是图片,想改字回来改完再导一次。
服务端这边几个细节值得一提:
- 超采样控分辨率。幻灯片固定在 1280×720 画布上,输出清晰度纯靠
deviceScaleFactor拉:@2x就是 2560×1440,往上能到 4K 甚至更高。视口不变,缩放因子变。 - 等渲染完成再截图。AI 产出的稿子里常有没渲染的 Mermaid 源码,所以截图前我会先把页面里未渲染的 Mermaid 节点跑一遍,再
await document.fonts.ready等 KaTeX/Google Fonts 落定,最后冻结所有动画。否则截出来缺图、缺字、动画糊成一团。 - SSE 推进度。页数多、页面复杂时导出会慢,用 Server-Sent Events 把
unpack → screenshot → assemble的进度实时推给前端,用户不至于对着转圈干等。 - 即用即焚。整个导出在一个
mkdtemp出来的临时目录里完成,finally里fs.rm删干净;产物丢进一个有 10 分钟 TTL 的下载缓存,过期自动清。服务端不持久化任何东西。
一整条导出流水线长这样,文件的「一生」也就这么几十秒:
// 固定 1280×720 画布,清晰度只由 deviceScaleFactor 决定
const SCALE_BY_RESOLUTION = {
'1280x720@2x': 2, // 2560×1440
'1920x1080@2x': 3, // ~4K
'3840x2160@2x': 4, // 5120×2880
};
8. 顺手把工具站做出 SEO:SSG + i18n
工具站不能只有一个 index.html 空壳——又想要 React 的交互,又想要爬虫和分享卡片能拿到真实内容。所以落地页和指南页用 vite-react-ssg 做了静态预渲染,按路径前缀分中英双语(/ 和 /en),每个语言版本都预渲染出带 title、description、canonical、hreflang 的真实 HTML。
这部分不算核心功能,但它是长期主义:一个工具想被人用,得先能被搜到、被分享出去时长得体面。
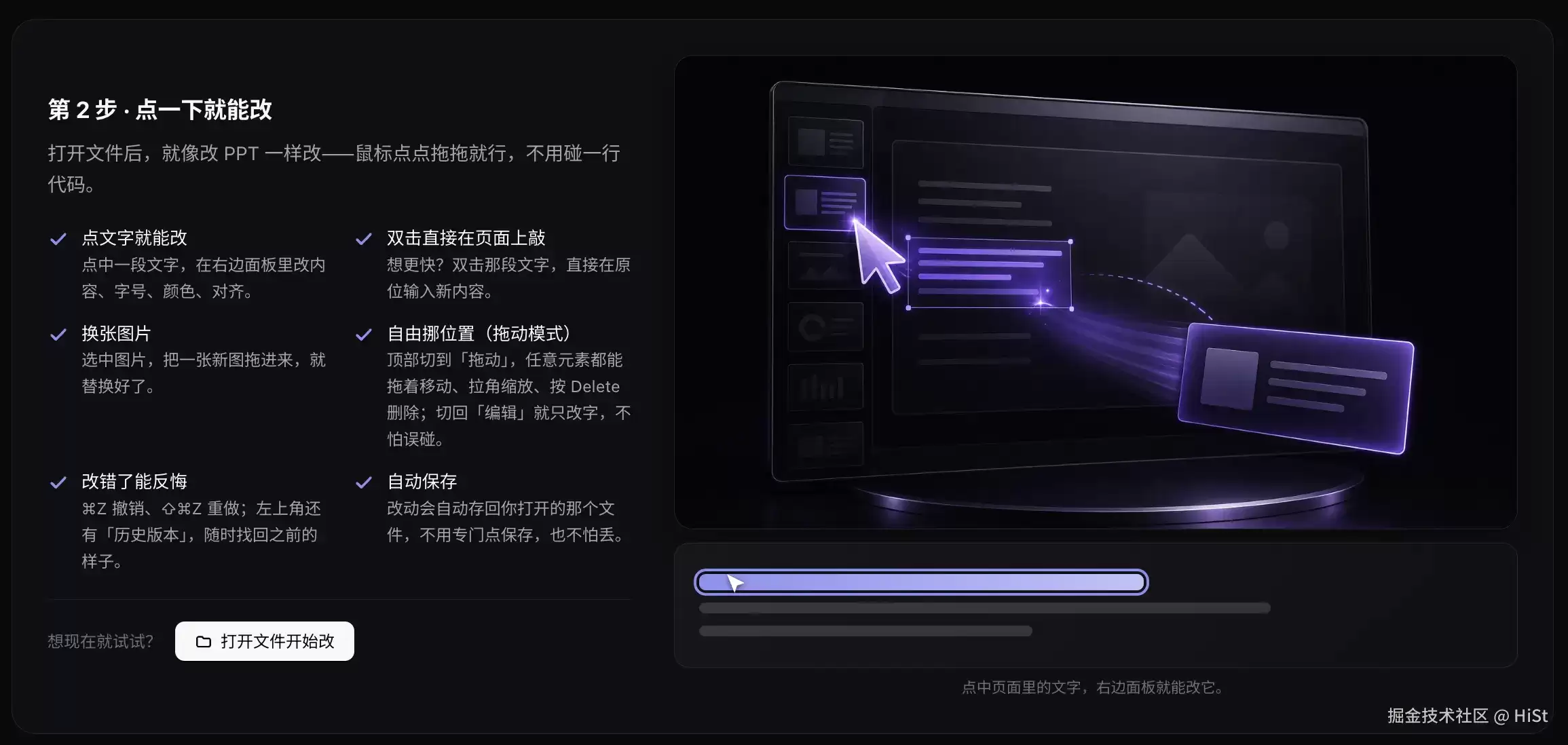
五、怎么用:生成 → 编辑 → 导出,就三步
讲完实现,说说普通用户视角的完整流程。其实一点都不复杂,三步:
第 1 步 · 让 AI 帮你做一份。 不会做也没关系,把一段提示词复制给任意 AI(ChatGPT、Claude、Gemini、豆包、Kimi 都行),把主题换成你的,它会回你一份现成的演示稿文件,存下来就行。官网指南页里直接备好了这段提示词,一键复制。
第 2 步 · 点一下就能改。 回到 next-ppt.com,用 Chrome/Edge 打开那个文件(或直接拖进来)。然后就像改 PPT 一样:点中文字在右边面板改内容/字号/颜色,双击直接在原位敲字,选中图片拖一张新图进去就替换,切到「拖动」还能自由挪位置、拉角缩放。改错了 ⌘Z,全程自动保存。
第 3 步 · 一键变 PPT / PDF。 点右上角导出,选格式和清晰度,可以只导某几页(1,3-5,8),下载。搞定。整个过程除了导出那几秒,都在你自己电脑上。
六、踩过的几个真实的坑
写工具最有价值的部分,往往是那些 README 里不会写、但你确实流过血的地方。挑三个印象最深的:
1. 拖动之后,整个版面塌了。 第一版把元素从文档流里「拎出来」变成绝对定位时,它原来占的位置瞬间塌缩,后面的元素全往上挤,于是你一拖第二个,测出来的坐标全是错的——结果就是所有浮动元素叠在了一起。解法是:抽离前先在原位插一个透明占位符(data-hds-placeholder)把空间占住,元素删除或还原自动布局时再回收掉这些占位符。一个很小的 trick,但不想到就是天天 debug。
2. 存盘存进去一堆「死」的 blob URL。 文件夹模式下图片在 iframe 里是 blob URL,我一开始直接把这份 HTML 写回磁盘了——结果下次打开,blob 早失效,图全裂了。后来才意识到:存盘必须走和导出一样的「还原相对路径」逻辑,把 blob URL 翻译回 assets/xxx.png 再落盘。两条路径用同一套还原函数,才算闭环。
3. SSG 之后页面出现两个 <title>。 静态预渲染注入了一份 title,index.html 里又留了个硬编码的,叠一起了。删掉模板里的默认 title 就好。小坑,但分享出去标题重复,挺丢人的。
这几个坑的共同点是:它们都不是模型能帮你发现的问题,得自己跑、自己看真实结果、自己判断。 AI 能帮我写出八成的样板代码,但这最后两成的「为什么不对」,还得是人。
写在最后
做完这一圈,我越来越相信一句话:AI 是放大器,放大的是你本来就在做的事情。 如果你心里有判断、有审美,它会让你跑得更快;如果你只有混乱,它也会把混乱放大得更快。它让我做 Demo、写样板、铺 i18n 的速度快了一大截,但「该砍掉哪些需求」「这个交互边界划在哪」「这个 bug 的本质是什么」——这些判断,它一个都替不了我。
所以我现在不太担心「不会写代码」,更担心「写得出,却说不清为什么」。纯 Coding 已经不再是护城河了,真正稀缺的,是判断力、审美,和把一个真实痛点啃到底的耐心。 当生成的成本趋近于零,过滤和打磨的价值反而被顶了上来——这世界从来不缺能跑的软件,缺的是有人愿意为「好不好用」较一次真。
NextPPT 现在还只是个 MVP,谈不上完美。但工具这东西,做到极致不是功能多,而是让人用着用着忘了它的存在;我也一直觉得,一个工具最好的样子,一定来自真正天天活在这个工作流里的人,而不是某次灵光一现。
如果它能帮你省下答辩前那个难受的晚上,对我来说就已经值了。毕竟说到底,我们写的每一行代码、做的每一个工具,最后都是在一点点雕刻自己。
- 官网体验:next-ppt.com/
- 开源代码:github.com/Trade-Offf/…
Please feel free to use and contribute to the development. 有想法欢迎来提 Issue、发 PR——开源用异步沟通,比拉群靠谱。