KV Cache优化实战:分层量化:动态淘汰:全局共享:攻克长上下文显存难题.157
一、什么是 KV Cache
1. 核心概念
在大模型的推理过程中,KV Cache 是专门为Transformer注意力机制设计的中间结果缓存技术。我们先回归Transformer 的核心:自注意力机制(Self-Attention),它的计算逻辑是:输入文本会被转换成三个向量:Query(查询向量 Q)、Key(键向量 K)、Value(值向量 V),注意力分数 = Q×Kᵀ,再通过Softmax归一化后与V相乘,得到最终的注意力输出。
大模型推理有一个关键特性:逐词生成。比如生成“今天天气很好”,模型会先输出“今”,再输出“天”,逐字迭代。如果不做缓存,每生成一个新词,都要重复计算之前所有文本的K和V向量,生成第 1000个词时,要重新计算前999个词的K/V,生成第1001个词时,又要重新计算前1000个词的K/V,这会造成海量的重复计算,推理速度极慢。
KV Cache的核心作用就是:把每一层Transformer计算好的K、V向量永久缓存下来,后续生成新词时,直接读取缓存,不再重复计算。这是大模型推理速度提升10~100倍的核心技术,没有KV Cache,当前的大模型几乎无法实现实时交互。
举个通俗的例子:我们写一篇1000字的文章,每写一个字都要把前面999个字重新写一遍,效率极低;而 KV Cache就像把前面写好的字存档,新字直接接在后面,不用重复书写。

2. 基础原理
KV Cache 的标准执行流程,我们以“逐词生成”为核心,拆解KV Cache的标准执行步骤,这是所有优化技术的基础:
1. 初始状态:输入Prompt提示词,模型对 Prompt 中的每一个Token(词或字),在每一层Transformer中计算K、V向量;2. 缓存写入:将所有层的K、V向量存储到显存(GPU Memory)中,形成初始KV Cache;3. 生成第一个新词:只计算新词的Q向量,直接读取缓存中所有旧Token的K、V,计算注意力分数,输出新词;4. 缓存更新:将新词的K、V向量追加到原有KV Cache的末尾,缓存长度 1;5. 循环生成:重复步骤 3-4,直到生成结束符号(EOS)。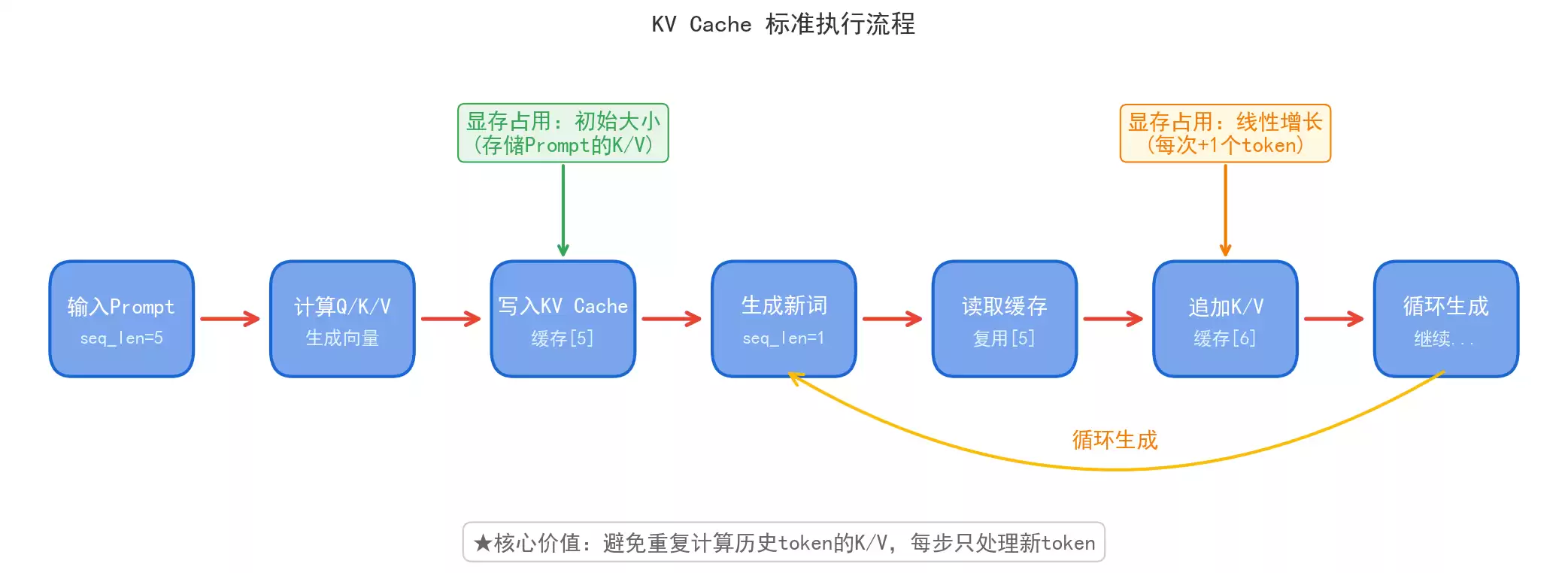
整个过程中,计算量大幅降低,但显存占用会线性增长,这就是KV Cache的双刃剑特性:提速的同时,带来了显存爆炸的风险。
3. KV Cache多维度对比
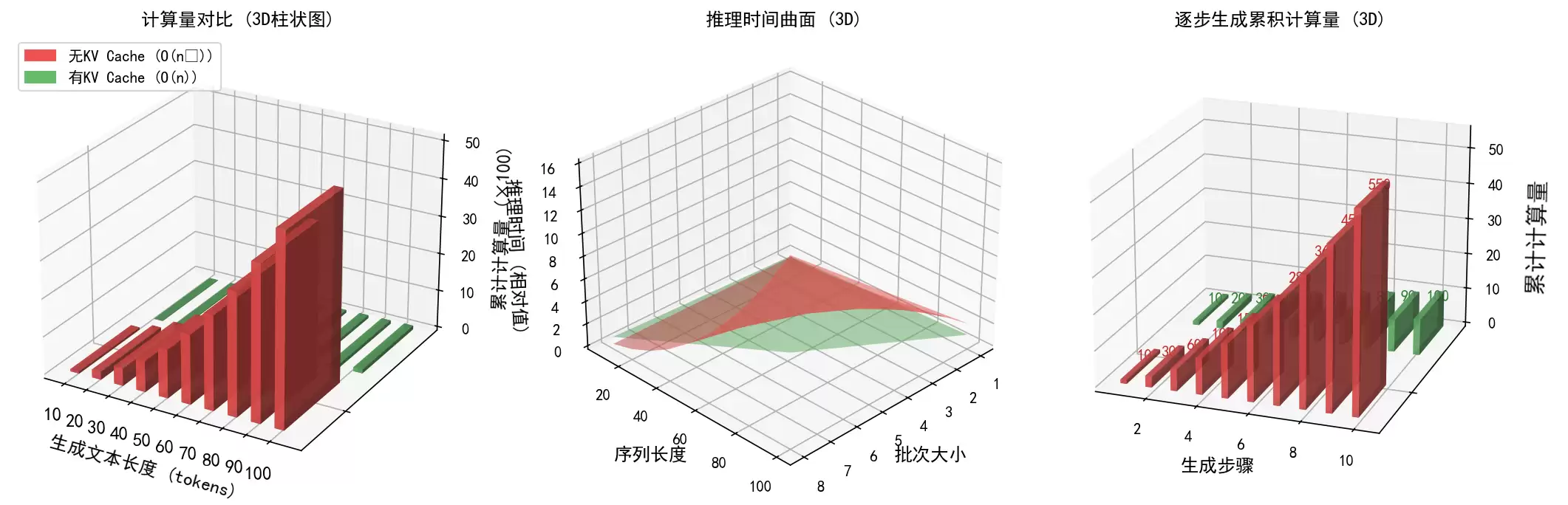
3.1 计算量对比柱状图
红色: 无KV Cache时计算量随长度平方增长绿色: 有KV Cache时计算量随长度线性增长3.2 推理时间曲面
展示不同批次和序列长度下的时间消耗红色曲面远高于绿色,差距随长度扩大3.3 逐步生成累积效果
每步红色柱子高度递增,要重算历史绿色柱子高度相同,只算新的1个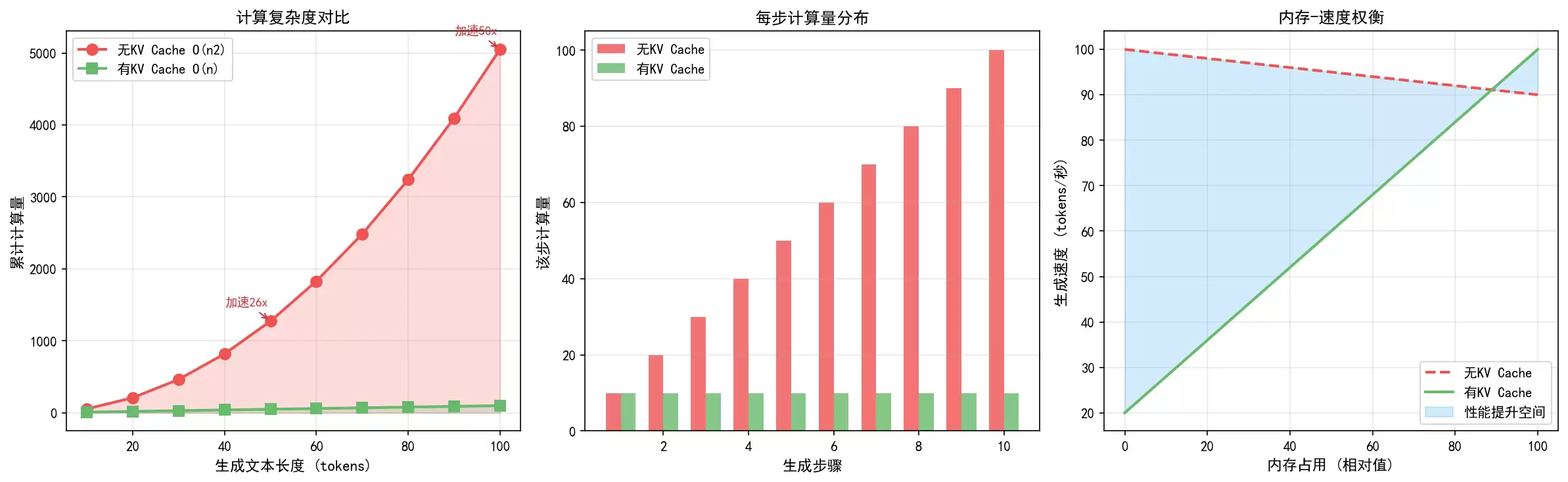
3.4 更直观的数值对比
左: 100token时加速约50倍中: 每步计算量对比右: 用内存换速度的策略4. 示例:原生KV Cache实现
KV Cache通俗解读,想象我们在写一篇长文章:
没有KV Cache = 每写一个新字,都要把整篇文章重新读一遍有KV Cache = 新写的字直接接在后面,之前的内容不用重复看这就是KV Cache的核心价值:记住之前算过的,避免重复计算!

技术细节:
缓存存储格式:标准格式为"batch_size, num_heads, seq_len, head_dim",是GPU显存的连续存储结构;显存占用公式:KV Cache大小 = 2 × 层数 × 头数 × 序列长度 × 头维度 × 数据类型字节数;核心瓶颈:长上下文(10万Token 以上)时,KV Cache会占用90%以上的显存,导致模型无法推理。输出结果:
============================================================
KV Cache 效果演示
============================================================
【场景1】你输入了一个问题:
'今天天气怎么样,适合去哪里玩?'
假设这句话被分成了5个token
→ 初始缓存形状 - K: torch.Size([1, 4, 5, 32])
含义: [1个批次, 4个注意力头, 5个token, 每头32维]
通俗: 记住了你输入的5个字的内容
【场景2】模型开始回答,生成第1个字:
'今' → 模型想回答'今天天气不错...'
这时候只需要处理这1个新字!
→ 更新后缓存形状 - K: torch.Size([1, 4, 6, 32])
变化: 5 → 6 (增加了1个token)
通俗: 新写的字自动接在后面,之前5个字不用重算
【场景3】继续生成回答,第2、3、4个字...
生成第2个字 → 缓存长度: 7
生成第3个字 → 缓存长度: 8
生成第4个字 → 缓存长度: 9
→ 最终缓存形状 - K: torch.Size([1, 4, 9, 32])
总共记住了9个token的内容
示例说明:
- 1. 形状变化对比:
tttttt步骤输入长度 缓存总长度计算方式tttttPrompt5 tokens5 tokens全量计算ttttt生成第1字1 token6 tokens只算1个新字ttttt生成第2字1 token7 tokens只算1个新字ttttt生成第3字1 token8 tokens只算1个新字ttttt ... ... ... ...ttt","rows":6,"cols":4,"id":"ElkHn"}">- 2. 核心价值:
避免重复计算 没有KV Cache: 生成第10个字时,要把前面10个字都重新算一遍有KV Cache: 只算新出的这1个字,前面9个直接拿来用速度大幅提升 假设生成100个字的回答:- 无KV Cache: 要算 1 2 3 ... 100 = 5050 次- 有KV Cache: 只要算 100 次- 加速比: 约 50 倍!内存换时间 缓存会占用显存,存储K和V矩阵但换来的是生成速度的巨大提升这是大模型推理的标配优化!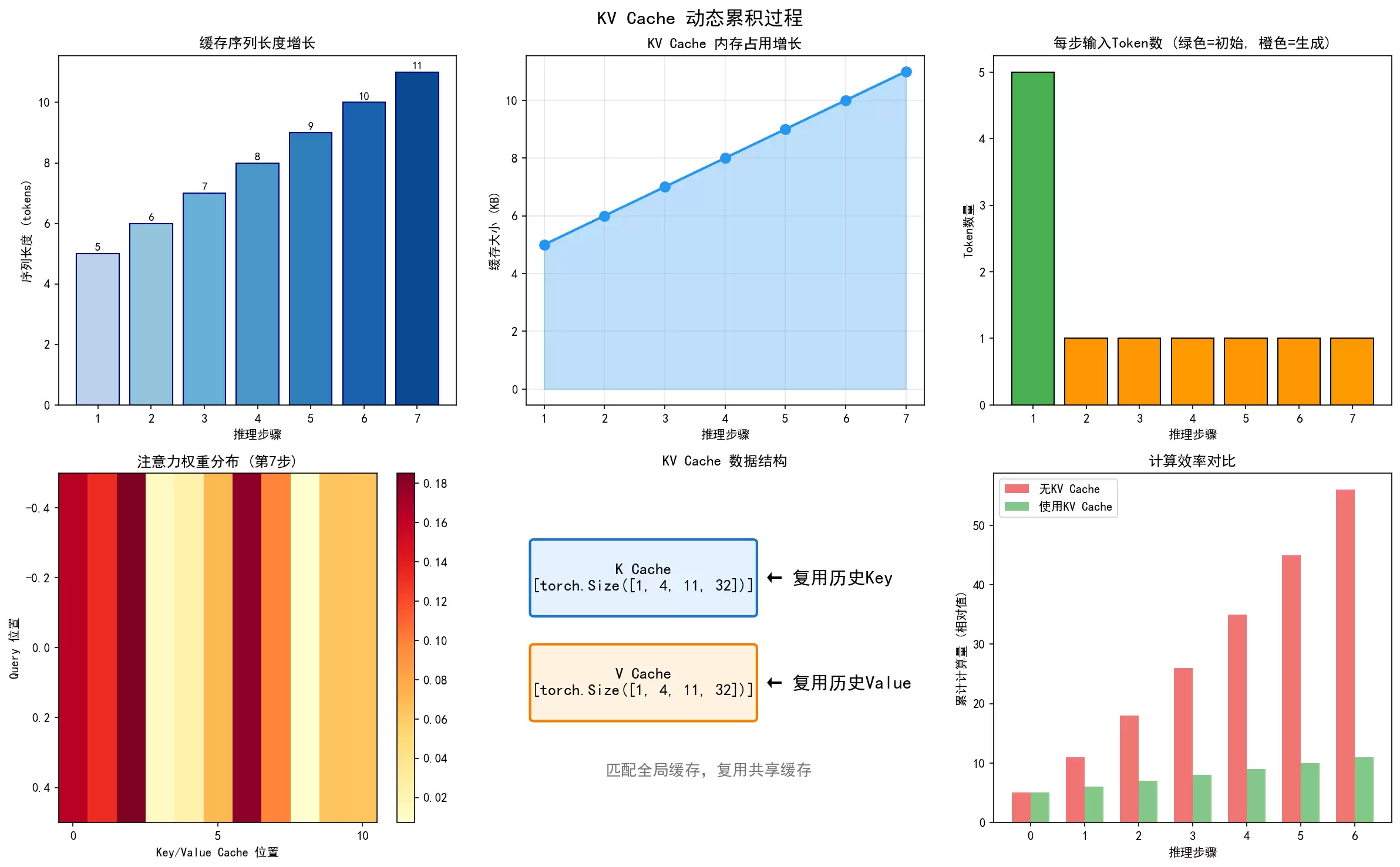
二、为什么要优化 KV Cache
1. 大模型长上下文的核心需求
当下的大模型已经从短文本对话升级为长上下文理解:
法律文档分析:估算需要10万Token;代码库理解:估算需要50万Token;长篇小说生成:估算需要100万Token;多模态文档处理:估算需要200万Token。这些场景对模型的上下文长度提出了极致要求,但原生KV Cache完全无法支撑。
我们用数据直观感受:以7B参数大模型、128层、128头、头维度128、FP16数据类型为例:
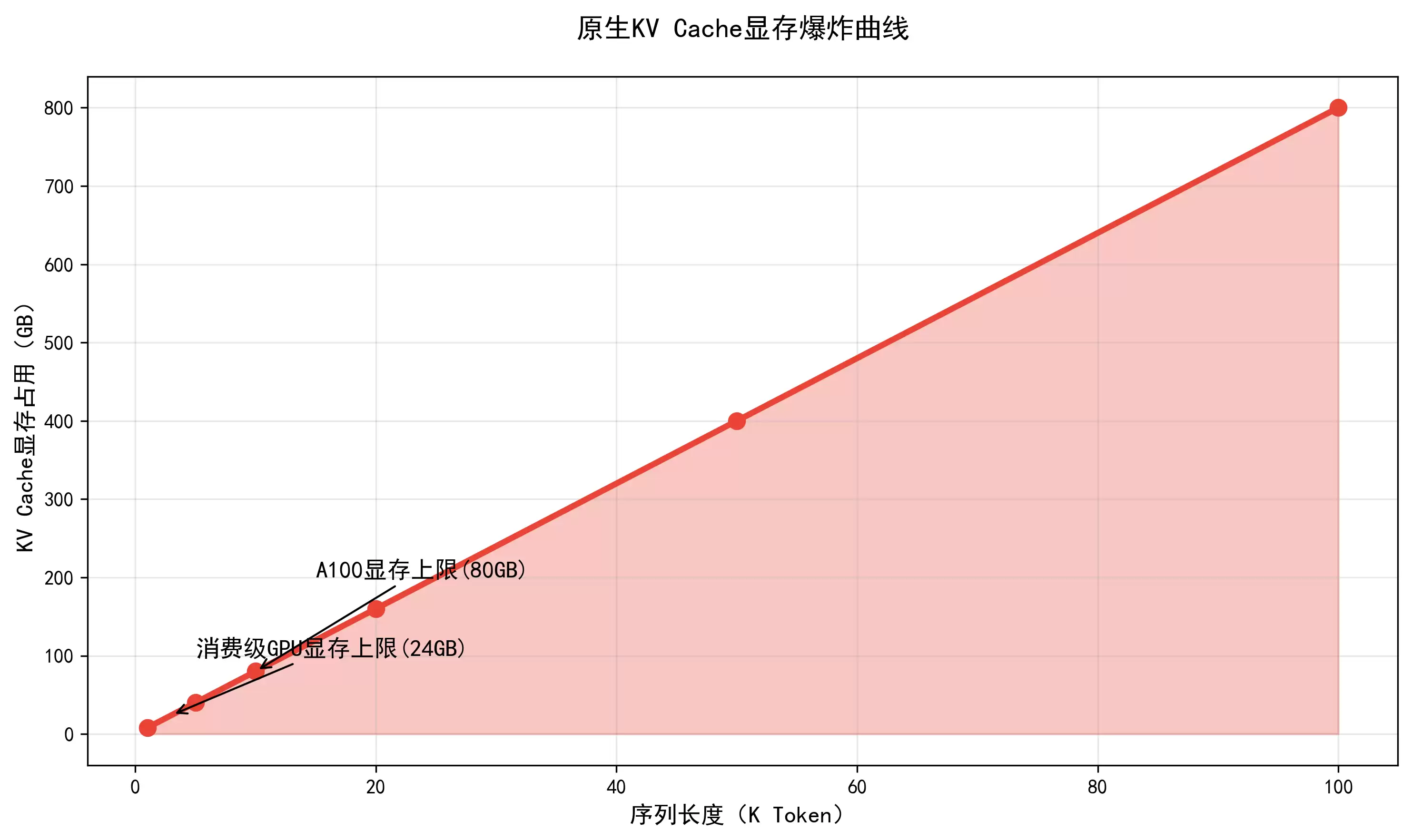
1K Token:KV Cache 占用 = 2×128×128×1024×128×2Byte ≈ 8GB;10K Token:≈80GB;100K Token:≈800GB。而主流消费级GPU显存仅为24GB,高端A100也仅为80GB,原生KV Cache在10K Token就会触发显存爆炸,直接导致推理崩溃。这就是KV Cache优化的必要性:不优化,大模型就无法实现长上下文推理。
2. 原生KV Cache的三大致命缺陷
2.1 显存占用线性增长
原生KV Cache是全量缓存,每生成一个 Token,就必须在显存中追加一组K/V向量;序列长度越长,显存占用越高,没有任何弹性空间。这是最核心的问题,也是所有优化技术的靶向目标。2.2 无差别缓存,浪费严重
Transformer的注意力机制有一个关键特性:注意力权重分布极度不均匀。90%的注意力分数集中在10%的关键Token上,比如文章的核心观点、对话的核心问题;而剩余90%的次要Token(比如语气词、标点符号、无关修饰词)几乎不影响模型输出,但原生 KV Cache 会一视同仁地缓存所有K/V向量,造成海量显存浪费。2.3 无共享、无分层,资源利用率极低
在多轮对话、批量推理场景中,不同请求、不同层之间存在大量重复的K/V向量,比如相同的系统提示词、相同的文档片段。原生KV Cache是独立缓存,每个请求、每层Transformer都单独存储,没有共享机制,资源利用率不足10%。3. KV Cache 优化对大模型的意义
1. 突破长上下文瓶颈:让7B/13B小模型也能支持10万 Token 长文本推理,打破显存物理限制;2. 降低推理成本:相同显存下,支持更长的上下文,减少GPU硬件投入;3. 提升推理速度:优化后的缓存读取速度更快,进一步降低推理延迟;4. 拓展模型应用场景:支撑法律、医疗、代码、长文创作等高价值长上下文业务;5. 适配端侧部署:让大模型在手机、嵌入式设备等低显存硬件上实现本地推理。4. 原生 KV Cache 显存爆炸曲线
三、四大核心优化技术
1. 量化压缩:最小化单条缓存显存占用
1.1 核心原理
量化压缩是最基础、性价比最高的KV Cache优化技术,核心逻辑是:降低K/V向量的数据精度,在几乎不损失模型效果的前提下,减少显存占用。
原生KV Cache默认使用FP16(2字节/数值)或FP32(4字节/数值),而量化技术可以将其压缩为INT8(1字节/数值)、INT4(0.5字节/数值),甚至 INT2(0.25字节/数值)。数据精度降低一半,显存占用就降低一半,推理速度也会同步提升。
1.2 技术分类
对称量化:将K/V向量的数值范围映射到对称的整数区间,计算简单,速度快;非对称量化:适配非均匀分布的K/V向量,精度损失更小,适合长文本场景;动态量化:每一层、每一步生成都动态计算量化参数,适配注意力分数的动态变化。1.3 示例:INT8 KV Cache量化

输出结果:
============================================================
KV Cache 量化效果演示
============================================================
【测试配置】
KV Cache形状: (1, 32, 4096, 128)
总元素数: 16,777,216
【原生FP16】
显存占用: 0.03 GB
数据类型: torch.float16
每元素: 2 bytes
【量化过程】
量化位数: INT8
缩放因子: 0.030746
量化后显存: 0.02 GB
压缩率: 2.0x
【精度验证】
均方误差(MSE): 0.00007889
最大误差: 0.015625
相对误差: 0.400%
技术细节:
INT8 量化:显存占用降低50%,精度损失<0.1%,工业级标准方案;INT4 量化:显存占用降低75%,适合超长上下文100K Token;量化位置:仅量化K/VCache,不量化Q向量,保证注意力计算精度。量化总结:用轻微精度损失,换取显存大幅节省
2. 动态淘汰:剔除无效缓存
2.1 核心原理
动态淘汰是基于注意力权重的智能缓存管理技术,核心逻辑是:计算每个Token的注意力分数,淘汰注意力权重极低的无效K/V向量,只保留关键缓存。
结合注意力机制的特性:模型只关注核心Token,次要Token的注意力权重趋近于0,剔除后完全不影响生成效果。动态淘汰会实时计算注意力分数分布,设定阈值,自动丢弃低于阈值的缓存。
2.2 执行流程

2.3 示例:注意力权重动态淘汰

输出结果:
淘汰前缓存长度: 1024
淘汰后缓存长度: 716
显存降低比例: 0.30078125
技术细节:
保留比例:长文本场景推荐保留60%~80%关键缓存;淘汰触发时机:每生成100个Token执行一次淘汰,平衡效率与效果;无感知淘汰:用户完全感受不到缓存压缩,生成效果与原生一致。3. 分层缓存:适配Transformer层级差异
3.1 核心原理
大模型的Transformer层有明确的层级分工:
底层负责提取文本基础特征,如字词、语法;中层负责语义理解;顶层负责逻辑推理与生成。不同层级的K/V向量重要性完全不同,分层缓存就是为不同层级设计差异化的缓存策略,实现精细化管理。
3.2 分层策略
顶层缓存(推理层):全量保留、高精度(FP16)、不淘汰,核心负责逻辑生成,不能损失精度;中层缓存(语义层):INT8 量化、动态淘汰,平衡精度与显存;底层缓存(特征层):INT4 量化、高比例淘汰,特征冗余度高,可大幅压缩。3.3 分层缓存架构
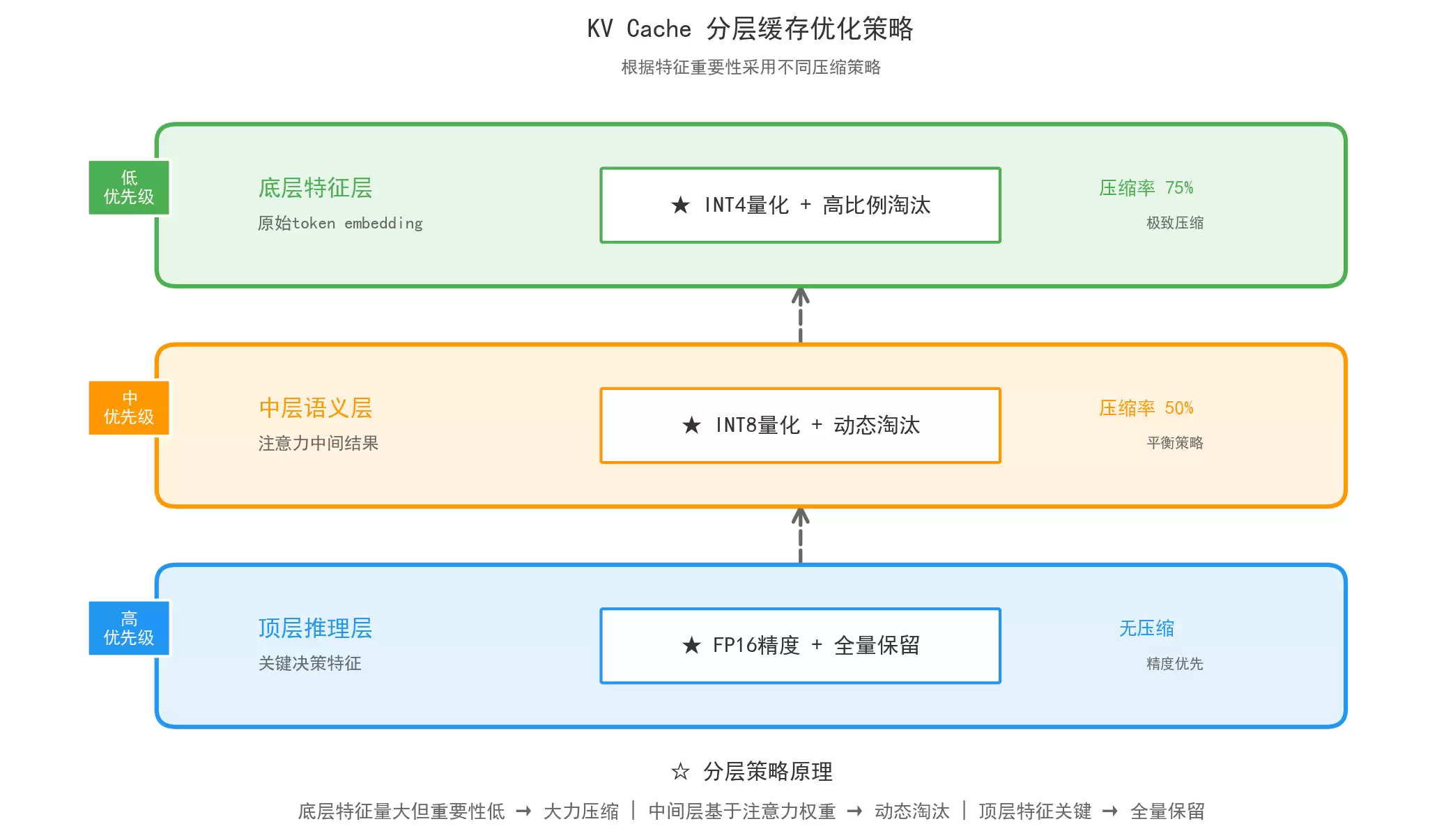
技术细节:
层级划分:128层模型,底层40层 中层48层 顶层40层;显存优化:分层后整体显存降低60%以上;兼容性:适配所有Transformer架构大模型。4. 全局共享:最大化资源利用率
4.1 核心原理
全局共享是批量推理、多轮对话场景的核心优化技术,核心逻辑是:将不同请求、不同对话中的重复Token(如系统提示、公共文档)的K/V缓存全局共享,避免重复存储。
比如100个用户同时请求模型,都使用相同的系统提示词“你是一个智能助手”,原生KV Cache会存储100份重复的K/V向量,而全局共享只存储1份,所有请求共享读取,显存占用降低 99%。
4.2 共享机制
公共缓存池:存储系统提示、公共文档等重复Token的K/V向量;私有缓存:存储用户个性化输入的K/V向量;缓存路由:推理时自动匹配公共缓存,无匹配则写入私有缓存。4.3 示例:全局共享缓存池
tttttt场景差异化体现ttttt场景1首次写入,展示缓存创建过程ttttt场景24个请求复用同一缓存,显示命中状态和节省显存ttttt场景33个不同用户,其中2个Prompt相同,展示复用识别ttttt场景4统计对比:传统方式 vs 共享方式的显存差异ttt","rows":5,"cols":2,"id":"HIOAu"}">= self.max_pool_size:n self.pool.popitem(last=False) # 先进先出淘汰n self.pool[token_hash] = (k_cache, v_cache)n # 读取共享缓存n def get(self, token_hash):n return self.pool.get(token_hash, (None, None))n # 检查缓存是否存在n def exists(self, token_hash):n return token_hash in self.pooln# 测试全局共享缓存nif __name__ == "__main__":n print("=" * 65)n print(" 全局共享KV缓存池 - 效果演示")n print("=" * 65)n n # 初始化缓存池n global_pool = GlobalKVCachePool(max_pool_size=100)n print(f"n【初始化】缓存池容量: {global_pool.max_pool_size} 项n")n n # 模拟系统Prompt(所有请求共享)n sys_prompt_hash = hash("你是一个智能助手")n sys_k = torch.randn(1, 128, 8, 128)n sys_v = torch.randn(1, 128, 8, 128)n cache_size_mb = sys_k.numel() * sys_k.element_size() * 2 / 1024 / 1024n n # 场景1:第一个请求写入系统Prompt缓存n print("-" * 65)n print("【场景1】请求1 - 首次系统Prompt | 提示词: '你是一个智能助手' ")n print("-" * 65)n print(f"系统Prompt缓存大小: {cache_size_mb:.2f} MB")n global_pool.put(sys_prompt_hash, sys_k, sys_v)n print(f"缓存池状态: {len(global_pool.pool)} 项")n n # 场景2:多个请求复用同一缓存n print("n" + "-" * 65)n print("【场景2】请求2-5 - 复用系统Prompt缓存")n print("-" * 65)n prompts = [n "你是一个智能助手", # 与请求1相同n "你是一个智能助手", # 与请求1相同n "你是一个智能助手", # 与请求1相同n "你是一个智能助手", # 与请求1相同n ]n for i, prompt in enumerate(prompts, start=2):n prompt_hash = hash(prompt)n k, v = global_pool.get(prompt_hash)n status = "✓ 命中" if k is not None else "✗ 未命中"n saved = cache_size_mb if k is not None else 0n print(f"请求{i}: {status} | 提示词: '{prompt}' | 节省: {saved:.2f} MB")n n # 场景3:不同用户不同Promptn print("n" + "-" * 65)n print("【场景3】用户A/B/C - 不同系统Prompt")n print("-" * 65)n users = [n ("用户A", "你是编程助手"),n ("用户B", "你是翻译专家"),n ("用户C", "你是编程助手") # 与用户A相同n ]n for user, prompt in users:n prompt_hash = hash(prompt)n k, v = global_pool.get(prompt_hash)n if k is None:n new_k = torch.randn(1, 128, 8, 128)n new_v = torch.randn(1, 128, 8, 128)n global_pool.put(prompt_hash, new_k, new_v)n print(f"{user}: 新缓存写入 | Prompt: '{prompt[:8]}...'")n else:n print(f"{user}: ✓ 复用缓存 | Prompt: '{prompt[:8]}...' (与用户A相同)")n n # 场景4:统计对比n print("n" + "=" * 65)n print("【效果统计】")n print("=" * 65)n total_saved = cache_size_mb * 4 # 4次复用n print(f"缓存池项数: {len(global_pool.pool)}")n print(f"系统Prompt复用次数: 4 次")n print(f"累计节省显存: {total_saved:.2f} MB")n print(f"传统方式需显存: {cache_size_mb * 5:.2f} MB (5份独立)")n print(f"共享方式需显存: {cache_size_mb:.2f} MB (1份共享)")n print(f"节省比例: {(1 - 1/5) * 100:.0f}%")n n print("n" + "=" * 65)n print("核心价值: N个请求共享1份缓存,显存节省 (N-1)/N")n print("=" * 65)","id":"igHkR"}">
输出结果:
=================================================================
全局共享KV缓存池 - 效果演示
=================================================================
【初始化】缓存池容量: 100 项
-----------------------------------------------------------------
【场景1】请求1 - 首次系统Prompt | 提示词: '你是一个智能助手'
-----------------------------------------------------------------
系统Prompt缓存大小: 1.00 MB
缓存池状态: 1 项
-----------------------------------------------------------------
【场景2】请求2-5 - 复用系统Prompt缓存
-----------------------------------------------------------------
请求2: ✓ 命中 | 提示词: '你是一个智能助手' | 节省: 1.00 MB
请求3: ✓ 命中 | 提示词: '你是一个智能助手' | 节省: 1.00 MB
请求4: ✓ 命中 | 提示词: '你是一个智能助手' | 节省: 1.00 MB
请求5: ✓ 命中 | 提示词: '你是一个智能助手' | 节省: 1.00 MB
-----------------------------------------------------------------
【场景3】用户A/B/C - 不同系统Prompt
-----------------------------------------------------------------
用户A: 新缓存写入 | Prompt: '你是编程助手...'
用户B: 新缓存写入 | Prompt: '你是翻译专家...'
用户C: ✓ 复用缓存 | Prompt: '你是编程助手...' (与用户A相同)
=================================================================
【效果统计】
=================================================================
缓存池项数: 3
系统Prompt复用次数: 4 次
累计节省显存: 4.00 MB
传统方式需显存: 5.00 MB (5份独立)
共享方式需显存: 1.00 MB (1份共享)
节省比例: 80%
=================================================================
核心价值: N个请求共享1份缓存,显存节省 (N-1)/N
=================================================================
技术细节:
哈希算法:使用SHA-256生成Token唯一哈希,避免冲突;适用场景:批量推理、多轮对话、公共文档问答;资源利用率:共享缓存可将批量推理显存占用降低90%以上。5. 融合优化:取长补短
5.1 融合优化执行流程
我们将分层缓存、量化压缩、动态淘汰、全局共享四大技术融合,形成端到端KV Cache优化流程,这是应用落地实践长上下文推理的标准方案:

5.2 融合优化显存效果对比
tttttt缓存类型1K Token 显存10K Token 显存100K Token 显存支持上下文上限tttttttt原生 KV Cache8GB80GB800GB8K(A100)ttttt融合优化 KV Cache1.2GB10GB80GB100K+(A100)ttt","rows":3,"cols":5,"id":"KiMjS"}">5.3 关键技术总结
量化压缩:基础优化,降低单条缓存大小;动态淘汰:智能优化,剔除无效缓存;分层缓存:精细化优化,适配层级差异;全局共享:规模化优化,提升资源利用率。四大技术相辅相成,共同解决长上下文显存爆炸问题,是大模型推理的核心基础设施。
四、总结
总的来说,分层缓存、量化压缩、动态淘汰、全局共享四大优化方案,是破解长上下文显存瓶颈的关键。量化从数据精度入手缩小缓存体积,动态淘汰筛选低权重无效Token节省空间,分层缓存贴合Transformer不同层级的特征差异做精细化管控,全局共享则解决批量场景下重复缓存的资源浪费问题,四项技术互补配合,就能在几乎不损耗生成效果的前提下,大幅压低显存占用。
大模型推理优化不是单一技术的堆砌,而是贴合模型结构、硬件限制与业务场景的综合调优。初次接触先吃透注意力机制与KV Cache底层逻辑,再逐个拆解单项优化原理。多对比优化前后的显存、性能差异,慢慢建立工程化思维。后续可以结合长文本推理落地场景深入研究,循序渐进掌握大模型部署优化的核心能力。