阿里改造后的memcached客户端源码详解
源码分析
memcached本身是一个集中式的内存缓存系统,对于分布式的支持服务端并没有实现,只有通过客户端实现;再者,memcached是基于TCP/UDP进行通信,只要客户端语言支持TCP/UDP即可实现客户端,并且可以根据需要进行功能扩展。memchaced-client-forjava 既是使用java语言实现的客户端,并且实现了自己的功能扩展,下面这张类图描述了其主要类之间的关系。
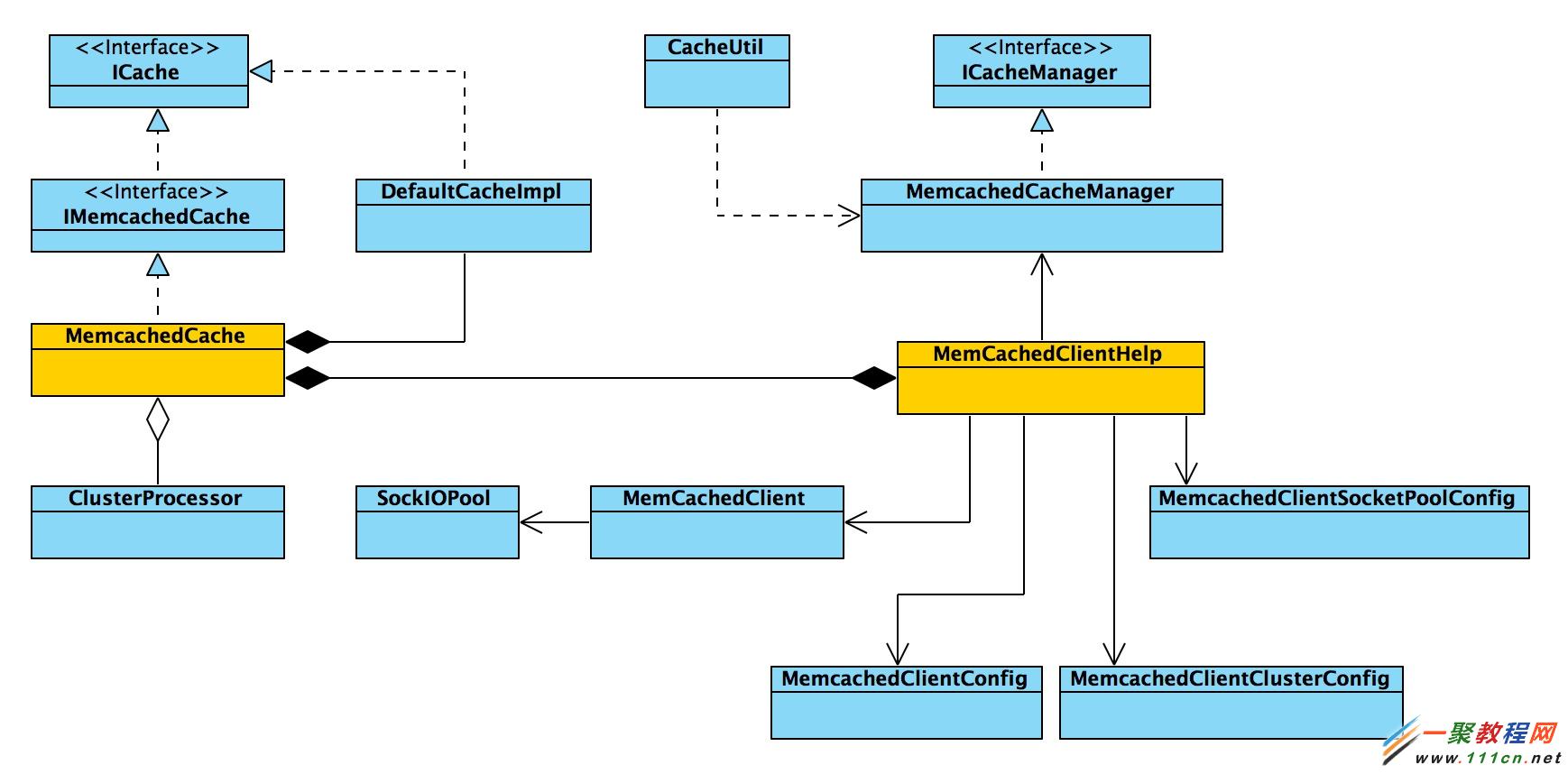
几个重要类的说明:
MemcachedCacheManager: 管理类,负责缓存服务端,客户端,以及相关资源池的初始化工作,获取客户端等等
MemcachedCache:memcached缓存实体类,实现了所有的缓存API,实际上也会调用MemcachedClient进行操作
MemcachedClient:memcached缓存客户端,一个逻辑概念,负责与服务端实例的实际交互,通过调用sockiopool中的socket
SockIOPool:socket连接资源池,负责与memcached服务端进行交互
ClusterProcessor:集群内数据异步操作工具类
客户端可配置化
MemcachedCacheManager是入口,其start方法读取配置文件memcached.xml,初始化各个组建,包括memcached客户端,socket连接池以及集群节点。
memcached客户端是个逻辑概念,并不是和memcached服务端实例一一对应的,可以认为其是一个逻辑环上的某个节点(后面会讲到hash一致性算法时涉及),该配置文件中,可配置一个或多个客户端,每个客户端可配置一个socketPool连接池,如下:
| 代码如下 | 复制代码 |
| 代码如下 | 复制代码 |
192.168.1.66:11211,192.168.1.68:11211 |
|
初始化过程
上文提及的MemcachedCacheManager,该类功能包括有初始化各种资源池,获取所有客户端,重新加载配置文件以及集群复制等。我们重点分析方法start,该方法首先加载配置文件,然后初始化资源池,即方法initMemCacheClientPool,该方法中定义了三个资源池,即socket连接资源池socketpool,memcachedcache资源池cachepool,以及由客户端组成的集群资源池clusterpool,这些资源池的数据结构都是线程安全的ConcurrentHashMap,保证了并发效率。将配置信息分别实例化后,再分别放入对应的资源池容器中,socket连接放入socketpool中,memcached客户端放入cachepool中,定义的集群节点放入clusterpool中。
注意,在实例化socket连接池资源socketpool时,会调用每个pool的初始化方法pool.initialize(),来映射memcached实例到HASH环上,以及初始化socket连接。
单点问题
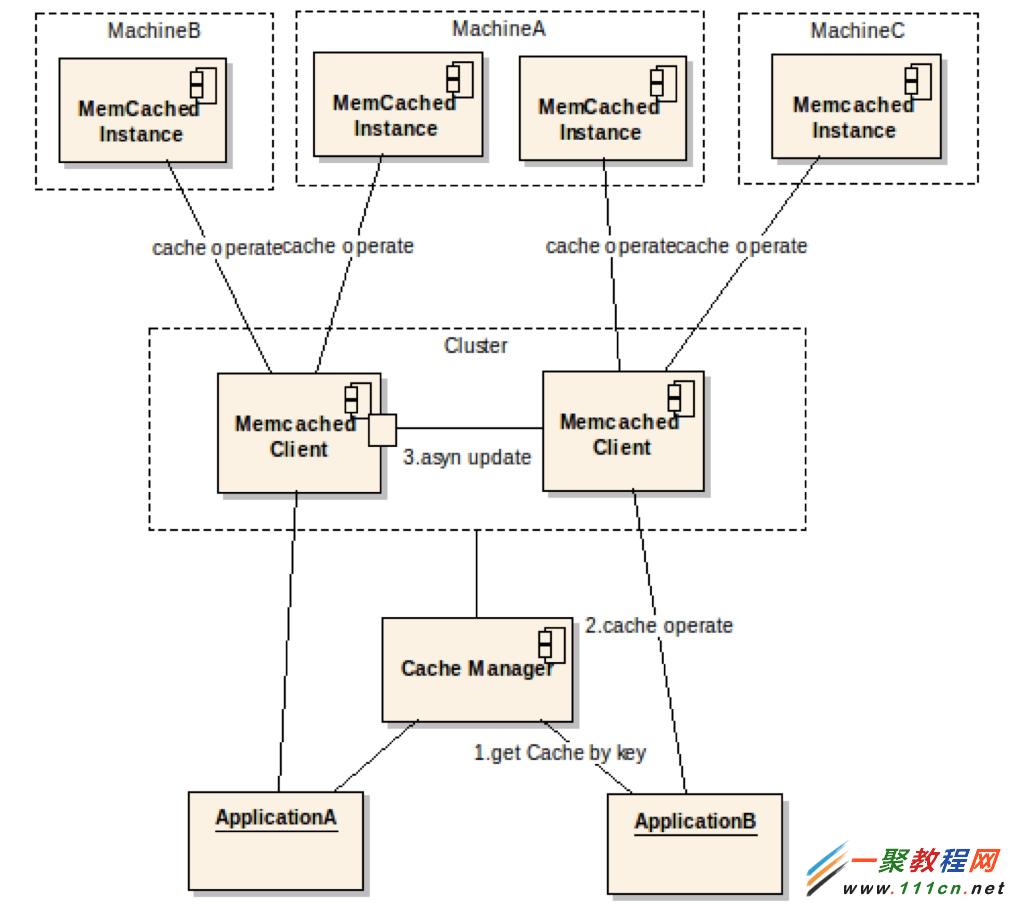
memcached的分布式,解决了容量水平扩容的问题,但是当某个节点失效时,还是会丢失一部分数据,单点故障依然存在,分布式只是解决了数据整体失效问题,而在实际项目中,特别是GAP平台适应的企业级项目中,是不允许数据不一致的,所以对每一份保存的数据都需要进行容灾处理,那么对于定义的每个memcached客户端,都至少增加一个新客户端与其组成一个cluster集群,当更新或者查找数据时,会先定位到该集群中某个节点,如果该节点失效,就去另外一个节点进行操作。在实际项目中,通过合理规划配置cluster和client(memcached客户端),可以最大限度的避免单点故障(当所有client都失效时还会丢失数据)。在配置文件中,集群配置如下:
| 代码如下 | 复制代码 |
mclient1,mclient2 |
|
下图展现了扩容和单点故障解决方案:
HASH一致性算法
在memcached支持分布式部署场景下,如何获取一个memcached实例?如何平均分配memcached实例的存储?这些需要一个算法来实现,我们选择的是HASH一致性算法,具体就体现在客户端如何获取一个连接memcached服务端的socket上,也就是如何定位memcached实例的问题?算法要求能够根据每次提供的同一个key获得同一个实例。
HASH闭环的初始化
本质上,hash一致性算法是需要实现一个逻辑环,如图所示,环上所有的节点即为一个memcached实例,如何实现?其实是根据每个memcached实例所在的ip地址,将所有的实例映射到hash数值空间中,构成一个闭合的圆环。
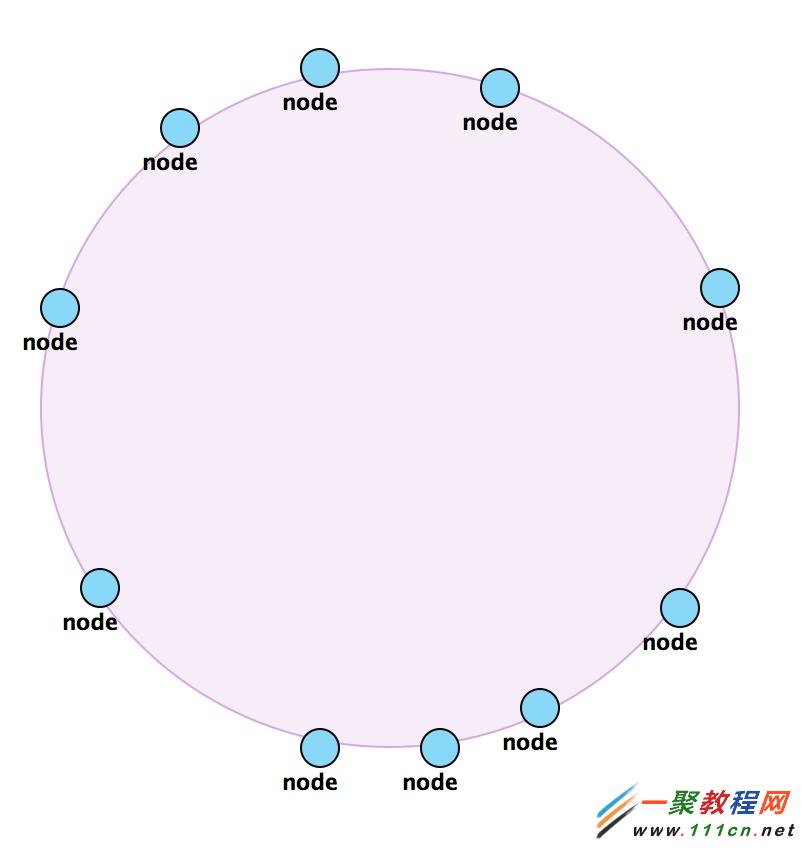
HASH环映射的初始化的代码位于SocketIOPool.populateConsistentBuckets方法中,主要代码如下:
| 代码如下 | 复制代码 |
| private void populateConsistentBuckets() { ……... for (int i = 0; i < servers.length; i++) { int thisWeight = 1; if (this.weights != null && this.weights[i] != null) thisWeight = this.weights[i]; double factor = Math .floor(((double) (40 * this.servers.length * thisWeight)) / (double ) this.totalWeight); for (long j = 0; j < factor; j++) { byte[] d = md5.digest((servers[i] + "-" + j).getBytes()); for (int h = 0; h < 4; h++) { // k 的值使用MD5hash算法计算获得 Long k = ((long) (d[3 + h * 4] & 0xFF) << 24) | ((long) (d[2 + h * 4] & 0xFF) << 16) | ((long) (d[1 + h * 4] & 0xFF) << 8) | ((long) (d[0 + h * 4] & 0xFF)); // 用treemap来存储memcached实例所在的ip地址, // 也就是将每个缓存实例所在的ip地址映射到由k组成的hash环上 consistentBuckets.put(k, servers[i]); if (log.isDebugEnabled()) log.debug("++++ added " + servers[i] + " to server bucket"); } } ……... } } |
|
获取socket连接
在实际获取memcahced实例所在服务器的soket时,只要使用基于同一个存储对象的key的MD5Hash算法,就可以获得相同的memcached实例所在的ip地址,也就是可以准确定位到hash环上相同的节点,代码位于SocketIOPool.getSock方法中,主要代码如下:
| 代码如下 | 复制代码 |
public SockIO getSock(String key, Integer hashCode){ …………. // from here on, we are working w/ multiple servers // keep trying different servers until we find one // making sure we only try each server one time Set tryServers = new HashSet(Arrays.asList(servers)); // get initial bucket // 通过key值计算hash值,使用的是基于MD5的算法 long bucket = getBucket(key, hashCode); String server = (this.hashingAlg == CONSISTENT_HASH) ? consistentBuckets .get(bucket) : buckets.g et((int) bucket); …………... } private long getBucket(String key, Integer hashCode) { / / 通过key值计算hash值,使用的是基于MD5的算法 long hc = getHash(key, hashCode); if (this.hashingAlg == CONSISTENT_HASH) { return findPointFor(hc); } else { long bucket = hc % buckets.size(); if (bucket < 0) bucket *= -1; return bucket; } } /** * Gets the first available key equal or above the given one, if none found, * returns the first k in the bucket * * @param k * key * @return */ private Long findPointFor(Long hv) { // this works in java 6, but still want to release support for java5 // Long k = this.consistentBuckets.ceilingKey( hv ); // return ( k == null ) ? this.consistentBuckets.firstKey() : k; // 该consistentBuckets中存储的是HASH结构初始化时,存入的所有memcahced实例节点,也就是整个hash环 // tailMap方法是取出大于等于hv的所有节点,并且是递增有序的 SortedMap tmap = this.consistentBuckets.tailMap(hv); // 如果tmap为空,就默认返回hash环上的第一个值,否则就返回最接近hv值的那个节点 return (tmap.isEmpty()) ? this.consistentBuckets.firstKey() : tmap .firstKey(); } /** * Returns a bucket to check for a given key. * * @param key * String key cache is stored under * @return int bucket */ private long getHash(String key, Integer hashCode) { if (hashCode != null) { if (hashingAlg == CONSISTENT_HASH) return hashCode.longValue() & 0xffffffffL; else return hashCode.longValue(); } else { switch (hashingAlg) { case NATIVE_HASH: return (long) key.hashCode(); case OLD_COMPAT_HASH: return origCompatHashingAlg(key); case NEW_COMPAT_HASH: return newCompatHashingAlg(key); case CONSISTENT_HASH: return md5HashingAlg(key); default: // use the native hash as a default hashingAlg = NATIVE_HASH; return (long) key.hashCode(); } } } /** * Internal private hashing method. * * MD5 based hash algorithm for use in the consistent hashing approach. * * @param key * @return */ private static long md5HashingAlg(String key) { / /通过key值计算hash值,使用的是基于MD5的算法 MessageDigest md5 = MD5.get(); md5.reset(); md5.update(key.getBytes()); byte[] bKey = md5.digest(); long res = ((long) (bKey[3] & 0xFF) << 24) | ((long) (bKey[2] & 0xFF) << 16) | ((long) (bKey[1] & 0xFF) << 8) | (long) (bKey[0] & 0xFF); return res; } |
|
通过以上代码的分析,整个memcahced服务端实例HASH环的初始化,以及数据更新和查找使用的算法都是基于同一种算法,这就保证了通过同一个key获得的memcahced实例为同一个。
socket连接池
这部分单独介绍,请猛烈地戳这里。
容灾、故障转移以及性能
衡量系统的稳定性,很大程度上是对各种异常情况的处理,充分考虑异常情况,以及合理处理异常是对系统设计人员的要求,下面看看在故障处理和容灾方面系统都做了那些工作。
定位memcached实例时,当第一次定位失败,会对所有其他的属于同一个socketpool中的memcahced实例进行定位,找到一个可用的,代码如下:
| 代码如下 | 复制代码 |
// log that we tried // 先删除定位失败的实例 tryServers.remove(server); if (tryServers.isEmpty()) break; // if we failed to get a socket from this server // then we try again by adding an incrementer to the // current key and then rehashing int rehashTries = 0; while (!tryServers.contains(server)) { // 重新计算key值 String newKey = new StringBuilder().append(rehashTries).append(key).toString(); // String.format( "%s%s", rehashTries, key ); if (log.isDebugEnabled()) log.debug("rehashing with: " + newKey); // 去HASH环上定位实例节点 bucket = getBucket(newKey, null); server=(this.hashingAlg == CONSISTENT_HASH) ? consistentBuckets.get(bucket) : buckets.get((int) bucket); rehashTries++; } |
|
查找数据时,当前节点获取不到,会尝试到所在集群中其他的节点查找,成功后,会将数据复制到原先失效的节点中,代码如下:
| 代码如下 | 复制代码 |
public Object get(String key) { Object result = null; boolean isError = false; ……....... if (result == null && helper.hasCluster()) if (isError || helper.getClusterMode().equals(MemcachedClientClusterConfig.CLUSTER_MODE_ACTIVE)) { List caches = helper.getClusterCache(); for(MemCachedClient cache : caches) { if (getCacheClient(key).equals(cache)) continue; try{ try { result = cache.get(key); } catch(MemcachedException ex) { Logger.error(new StringBuilder(helper.getCacheName()) .append(" cluster get error"),ex); continue; } //仅仅判断另一台备份机器,不多次判断,防止效率低下 if (helper.getClusterMode().equals(MemcachedClientClusterConfig.CLUSTER_MODE_ACTIVE ) && result != null) { Object[] commands = new Object[]{CacheCommand.RECOVER,key,result}; // 加入队列,异步执行复制数据 addCommandToQueue(commands); } break; } catch(Exception e) { Logger.error(new StringBuilder(helper.getCacheName()) .append(" cluster get error"),e); } } } return result; } |
|
更新数据时,异步更新到集群内其他节点,示例代码如下:
| 代码如下 | 复制代码 |
public boolean add(String key, Object value) { boolean result = getCacheClient(key).add(key,value); if (helper.hasCluster()) { Object[] commands = new Object[]{CacheCommand.ADD,key,value}; // 加入队列,异步执行 addCommandToQueue(commands); } return result; } |
|
删除数据时,需要同步执行,如果异步的话,会产生脏数据,代码如下:
| 代码如下 | 复制代码 |
public Object remove(String key) { Object result = getCacheClient(key).delete(key); //异步删除由于集群会导致无法被删除,因此需要一次性全部清除 if (helper.hasCluster()) { List caches = helper.getClusterCache(); for(MemCachedClient cache : caches) { if (getCacheClient(key).equals(cache)) continue; try { cache.delete(key); } catch(Exception ex) { Logger.error(new StringBuilder(helper.getCacheName()) .append(" cluster remove error"),ex); } } } return result; } |
|
异步执行集群内数据同步,因为不可能每次数据都要同步执行到集群内每个节点,这样会降低系统性能;所以在构造MemcachedCache对象时,会建立一个队列,线程安全的linked阻塞队列LinkedBlockingQueue,将所有需要异步执行的命令放入队列中,异步执行,具体异步执行由ClusterProcessor类负责。
| 代码如下 | 复制代码 |
public MemcachedCache(MemCachedClientHelper helper,int statisticsInterval) { this.helper = helper; dataQueue = new LinkedBlockingQueue(); ……… processor = new ClusterProcessor(dataQueue,helper); processor.setDaemon(true); processor.start(); } |
|
本地缓存的使用是为了降低连接服务端的IO开销,当有些数据变化频率很低时,完全可以放在应用服务器本地,同时可以设置有效时间,直接获取。DefaultCacheImpl类为本地缓存的实现类,在构造MemcachedCache对象时,即初始化。
每次查找数据时,会先查找本地缓存,如果没有再去查缓存,结束后将数据让如本地缓存中,代码如下:
| 代码如下 | 复制代码 |
public Object get(String key, int localTTL) { Object result = null; // 本地缓存中查找 result = localCache.get(key); if (result == null) { result = get(key); if (result != null) { Calendar calendar = Calendar.getInstance(); calendar.add(Calendar.SECOND, localTTL); // 放入本地缓存 localCache.put(key, result,calendar.getTime()); } } return result; } |
|
增加缓存数据时,会删除本地缓存中对应的数据,代码如下:
| 代码如下 | 复制代码 |
public Object put(String key, Object value, Date expiry) { boolean result = getCacheClient(key).set(key,value,expiry); //移除本地缓存的内容 if (result) localCache.remove(key); …….. return value; } |
|
改造部分
据以上分析,我们通过封装,做到了客户端的可配置化,memcached实例的水平扩展,通过集群解决了单点故障问题,并且保证了应用程序只要每次使用相同的数据对象的key值即可获取相同的memcached实例进行操作。但是,为了使缓存的使用对于应用程序来说完全透明,我们对cluster部分进行了再次封装,即把cluster看做一个node,根据cluster名称属性,进行HASH数值空间计算(同样基于MD5算法),映射到一个HASH环上,如下图,。
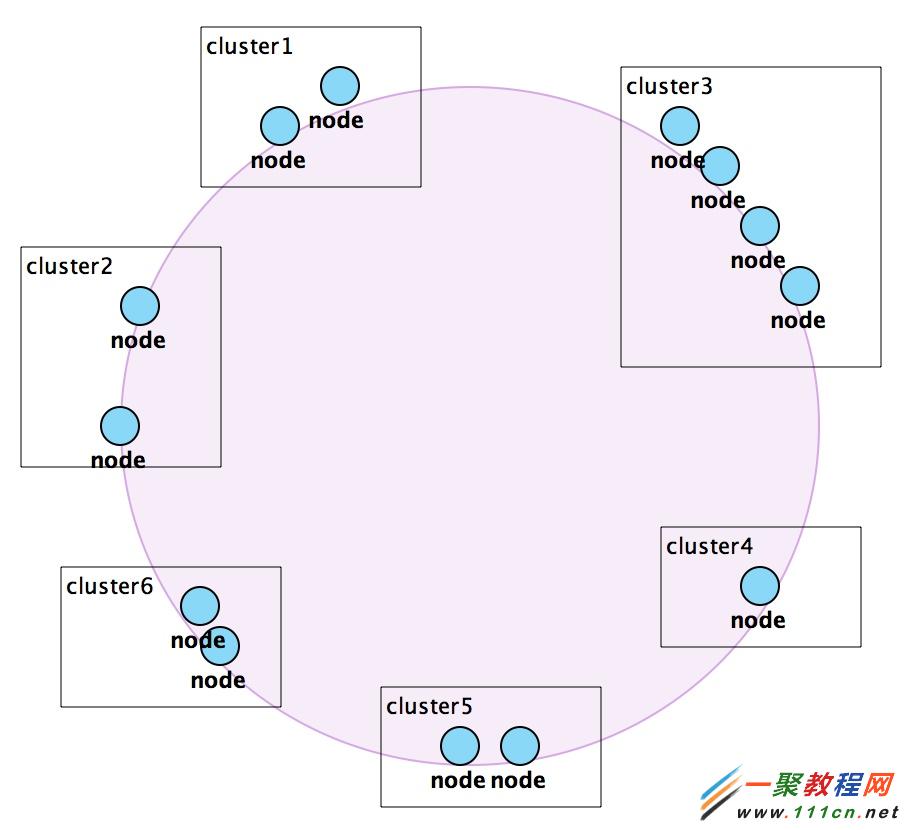
这部分逻辑放在初始化资源池clusterpool时进行(即放在MemcahedCacheManager.initMemCacheClientPool方法中),与上文中所描述的memcached实例HASH环映射的逻辑一致,部分代码如下:
| 代码如下 | 复制代码 |
| //populate cluster node to hash consistent Buckets MessageDigest md5 = MD5.get(); // 使用cluster的名称计算HASH数值空间 byte[] d = md5.digest((node.getName()).getBytes()); for (int h = 0; h < 4; h++) { Long k = ((long) (d[3 + h * 4] & 0xFF) << 24) | ((long) (d[2 + h * 4] & 0xFF) << 16) | ((long) (d[1 + h * 4] & 0xFF) << 8) | ((long) (d[0 + h * 4] & 0xFF)); consistentClusterBuckets.put(k, node.getName()); if (log.isDebugEnabled()) log.debug("++++ added " + node.getName() + " to cluster bucket"); } |
|
在进行缓存操作时,仍然使用数据对象的key值获取到某个cluster节点,然后再使用取余算法(这种算法也是经常用到的分布式定位算法,但是有局限性,即随着节点数的增减,定位越来越不准确),拿到cluster中的某个节点,在进行缓存的操作;定位hash环上cluster节点的逻辑也与上文一样,这里不在赘述。部分定位cluster中节点的取余算法代码如下:
public IMemcachedCache getCacheClient(String key){
………….
String clusterNode = getClusterNode(key);
MemcachedClientCluster mcc = clusterpool.get(clusterNode);
List memcachedCachesClients = mcc.getCaches();
//根据取余算法获取集群中的某一个缓存节点
if (!memcachedCachesClients.isEmpty())
{
long keyhash = key.hashCode();
int index = (int)keyhash % memcachedCachesClients.size();
if (index < 0 )
index *= -1;
return memcachedCachesClients.get(index);
}
return null;
}
这样,对于应用来说,配置好资源池以后,无需关心那个集群或者客户端节点,直接通过MemcachedCacheManager获取到某个memcachedcache,然后进行缓存操作即可。
最后,使用GAP平台分布式缓存组件,需要提前做好容量规划,集群和客户端事先配置好;另外,缓存组件没有提供数据持久化功能。