利用Pacemaker集群管理让Apache最大可用性
实验环境:
系统版本:CentOS release 6.5 (Final)_x64
node1: ip :192.168.0.233 #写进/etc/hosts文件中
node2: ip :192.168.0.234
vip: 192.168.0.183
注意:1.两台机器务必写静态ip,切记莫用dhcp获取ip,确保两个机器互相能ping通
2. 先禁用防火墙和SELinux
一.配置SSH
SSH 是一个方便又安全的用来远程传输文件或运行命令的工具. 在这个文档中, 我们创建ssh key(用 -N 选项)来免去登入要输入密码的麻烦。
创建一个密钥并允许所有有这个密钥的用户登入
在node1上操作:
[root@node1 ~]# ssh-keygen -t dsa -f ~/.ssh/id_dsa -N ""
[root@node1 ~]# cp .ssh/id_dsa.pub .ssh/authorized_keys
[root@node1 ~]# scp -r .ssh node2:
ok,我们已经做好了双机认证
二.集群软件安装/配置(两台机器都要做同样的操作)
1.这里,我们用的rpm包安装的,建议使用163源或epel 源进行依赖关系解决:
epel-release-6-5.noarch #我用的是epel源,找不到源rpm包的话可以留言给我
rpm -ivh epel-release-6-5.noarch.rpm #安装
163源:
wget http://mirrors.**1*63.com/.help/CentOS6-Base-163.repo
2.设置Pacemaker源:
vi /etc/yum.repos.d/centos.repo #贴入如下内容
[centos-6-base]
name=CentOS-$releasever - Base
mirrorlist=http://mirrorlist.ce**n*tos.org/?release=$releasever&arch=$basearch&repo=os
enabled=1
#baseurl=http://mirror.*ce**ntos.org/centos/$releasever/os/$basearch/
3.安装集群软件:
[root@node1 ~]# yum makecache #缓存一下
[root@node1 ~]# yum install lvm2-cluster corosync pacemaker pcs -y #安装请这样安装,官网文档有点坑,大概八十六个包
4.开始集群设置:
[root@node1 ~]# /etc/init.d/pcsd start

[root@node2 ~]# /etc/init.d/pcsd start

① 设置hacluster用户设置密码。两个节点设置一致
[root@node1 ~]# passwd hacluster
[root@node2 ~]# passwd hacluster
② 配置 Corosync
hacluster 这个我们之前用过的用户就是做统一的集群管理用的,这里配置corosync就是用到这个用户,配置完成后生成corosync.conf 发送到各个节点上hacluster在一个集群中的节点认证的的事情。
[root@node1 ~]# pcs cluster auth node1 node2
Username: hacluster
Password: #这里输入redhat
node1: Authorized
node2: Authorized
[root@node1 ~]# pcs cluster setup --name mycluster node1 node2
node1: Updated cluster.conf...
node2: Updated cluster.conf...
③ 启动我们的集群:
[root@node1 ~]# pcs cluster start --all #启动稍微有点慢,耐心等待

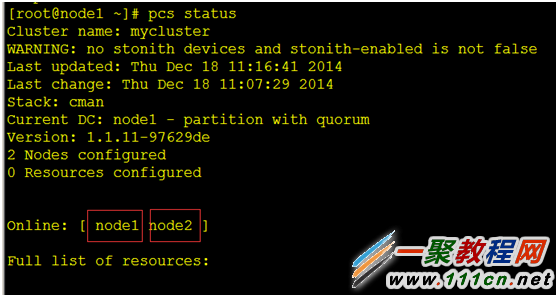
④ 查看我们创建的集群,节点状态:
[root@node1 ~]# pcs status
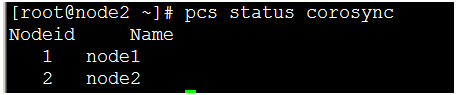
[root@node1 ~]# pcs status corosync
[root@node1 ~]# crm_verify -L -V #查看你会发现很多错误
[root@node1 ~]# pcs property set stonith-enabled=false #关掉这些错误
三.开始配置我们的Apache高可用(主/备)
①.添加vip
首先要做的是配置一个IP地址,不管集群服务在哪运行,我们要一个固定的地址来提供服务。在这里我选择 192.168.0.183作为浮动IP,给它取一个好记的名字 ClusterIP 并且告诉集群每30秒检查它一次。
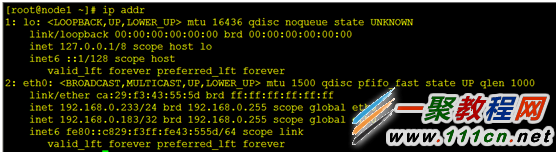
[root@node1 ~]# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.0.183 cidr_netmask=32 op monitor interval=30s
另外一个重要的信息是 ocf:heartbeat:IPaddr2。这告诉Pacemaker三件事情,第一个部分ocf,指明了这个资源采用的标准(类型)以及在哪能找到它。第二个部分标明这个资源脚本的在ocf中的名字空间,在这个例子中是heartbeat。最后一个部分指明了资源脚本的名称。
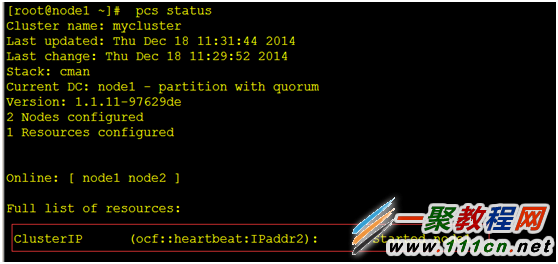
[root@node1 ~]# pcs status #查看我们已经创建好的资源,一个vip现在已经在node1 上运行
②安装Apace
在继续前,我们需要确保两个节点上都安装了Apache。
[root@node1 ~]# yum -y install httpd
[root@node2 ~]# yum -y install httpd
准备工作,给Apache,写个默认首页:
[root@node1 ~]# cat /var/www/html/index.html
welcome to node 1
END
[root@node2 ~]# cat /var/www/html/index.html
welcome to node 2
END
③开启 Apache status URL
为了监控Apache实例的健康状态,并在它挂掉的时候恢复Apache服务,pacemaker使用的资源agent会假设 server-status URL是可用的。查看/etc/httpd/conf/httpd.conf并确保下面的选项没有被禁用或注释掉。,在这里我们直接添加了,默认是注释的。
注意,两个node的Apache都要添加,切勿偷懒
vi /etc/httpd/conf/httpd.conf
SetHandler server-status
Order deny,allow
Deny from all
Allow from 127.0.0.1
⑤ Apache 添加进我们的集群中
[root@node1~]#pcs resource create Web ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://*l*o*calhost/server-status" op monitor interval=1min
现在,Apache已经可以添加到集群中了。我们管这个资源叫Web。我们需要用一个叫做apache的OCF脚本,这个脚本在heartbeat这个名字空间里,唯一一个需要设定的参数就是Apache的主配置文件路径,并且我们告诉集群每一分钟检测一次Apache是否运行。
默认的,所有资源的start,stop和monitor操作的超时时间都是20秒。在很多情况下这个超时周期小于建议超时时间。在本教程中,我们将调整全局操作的超时时间为240秒。
[root@node1 ~]# pcs resource op defaults timeout=240s
[root@node1 ~]# pcs resource op defaults
timeout: 240s
⑥ 确保资源在同一个节点运行
(1)为了减少每个机器的负载,Pacemaker会智能地尝试将资源分散到各个节点上面。然而我们可以告诉集群某两个资源是有联系并且要在同一个节点运行(或不同的节点运行)。这里我们告诉集群WebSite只能在有ClusterIP的节点上运行。
(2)为此我们使用托管约束来强制性的表明WebS和ClusterIP运行在同一节点。“强制性”部分的托管约束使用分数INFINITY(无穷大)来表示。无穷大也表明了如果ClusterIP没有在任何节点运行,那么Web也不能运行。
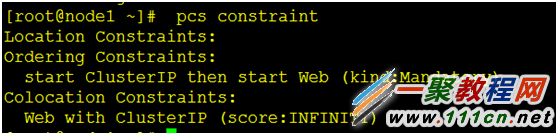
[root@node1 ~]# pcs constraint colocation add Web ClusterIP INFINITY
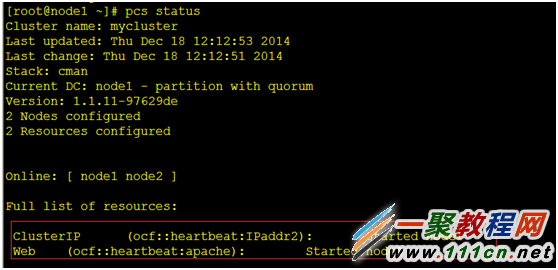
在两个节点上启动Apache即可,用vip访问我们写的界面。
⑦ 控制资源的启动停止顺序
当Apache启动了,它跟可用的IP绑在了一起。它不知道我们后来添加的IP,所以我们不仅需要控制他们在相同的节点运行,也要确保ClusterIP 在Web之前就启动了。我们用添加ordering约束来达到这个效果。我们需要给这个order取个名字(apache-after-ip之类描述性的),并指出他是托管的(这样当ClusterIP恢复了,同时会触发Web的恢复) 并写明了这两个资源的启动顺序。
[root@node1 ~]# pcs constraint order ClusterIP then Web

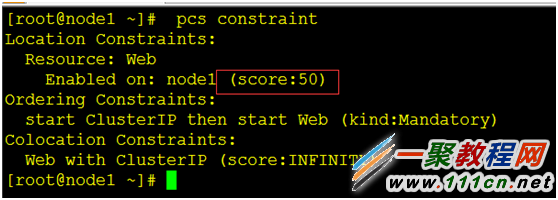
[root@node1 ~]# pcs constraint #查看一下我们写的规则
⑧ .指定优先的 Location
(1)Pacemaker 并不要求你机器的硬件配置是相同的,可能某些机器比另外的机器配置要好。这种状况下我们会希望设置当某个节点可用时,资源就要跑在上面之类的规则。为了达到这个效果我们创建location约束。
(2)同样的,我们给他取一个描述性的名字(prefer-pcmk-1),指明我们想在上面跑WebSite这个服务,多想在上面跑(我们现在指定分值为50,但是在双节点的集群状态下,任何大于0的值都可以达到想要的效果),以及目标节点的名字:
[root@node1 ~]# pcs constraint #查看我们写好的规则
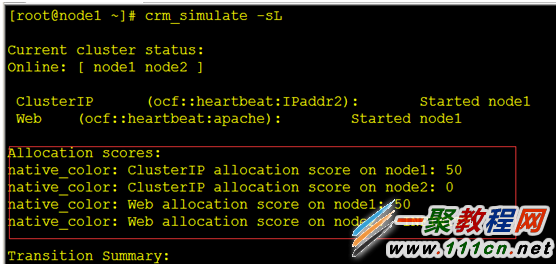
如果要看现在的分值,可以用crm_simulate这个命令
[root@node1 ~]# crm_simulate -sL
⑨在集群中手动迁移资源
[root@node1 ~]# pcs constraint location Web prefers node2=INFINITY
Pacemaker 还有许多强大的功能还未挖掘,请求期待!