SQLServer使用XML详细教程
SQL Server对于XML支持的核心在于XML数据的格式,这种数据类型可以将XML的数据存储于数据库的对象中,比如variables, columns, and parameters。当你用XML数据类型配置这些对象中的一个时,你指定类型的名字就像你在SQLServer 中指定一个类型一样。
XML的数据类型确保了你的XML数据被完好的构建保存,同时也符合ISO的标准。在定义一个XML数据类型之前,我们首先要知道它的几种限制,如下:
一个实例的XML列不能包含超过2GB的数据。
一个XML的列不能是索引。
XML对象不能使用Group By的子句中。
XML的数据类型不支持比较和排序。
定义一个XML变量
DECLARE @ClientList XML
SET @ClientList =
'<?xml version="1.0" encoding="UTF-8"?>
John
Doe
Jane
Doe
'
SELECT @ClientList
GO
这个例子通过使用DECLARE 声明去定义名为@ClientList 的变量,当我声明变量的时候,只需要包含XML的数据类型的名字在变量名后。
我设定了变量的值,然后使用select 来检索这个值。和我们想的一样,它返回了XML的文档。如下:
John
Doe
Jane
Doe
接下来我们看看如何定义一个XML的列
在下面的例子中,我将创建一个商店客户的表,表中存储了ID和每个商店的客户信息。
USE AdventureWorks2008R2
GO
IF OBJECT_ID('dbo.StoreClients') IS NOT NULL
DROP TABLE dbo.StoreClients
GO
CREATE TABLE dbo.StoreClients
(
StoreID INT IDENTITY PRIMARY KEY,
ClientInfo XML NOT NULL
)
GO
接下来插入数据到这个表中,包括XML的文档和片段。我将声明一个XML的变量,然后用这个变量插入这个文档到表的数据行里面。
DECLARE @ClientList XML
SET @ClientList =
'<?xml version="1.0" encoding="UTF-8"?>
John
Doe
Jane
Doe
'
INSERT INTO dbo.StoreClients (ClientInfo)
VALUES(@ClientList)
GO
尽管变量将整个XML文档插入了进来,但是它是被当做一个单一的值插入到表列里面来。
正如以上所述,创建和插入都是很直接简单的,接下来我们看一下如何创建一个XML的参数
定义一个XML参数
例如,我定义@StoreClients 作为一个输入参数,并且配置它为XML的类型
USE AdventureWorks2008R2
GO
IF OBJECT_ID('dbo.AddClientInfo', 'P') IS NOT NULL
DROP PROCEDURE dbo.AddClientInfo
GO
CREATE PROCEDURE dbo.AddClientInfo
@StoreClients XML
AS
INSERT INTO dbo.StoreClients (ClientInfo)
VALUES(@StoreClients)
GO
然后我们再看看在存储过程中如何使用XML作为参数:
DECLARE @ClientList XML
SET @ClientList =
'<?xml version="1.0" encoding="UTF-8"?>
John
Doe
Jane
Doe
'
EXEC dbo.AddClientInfo @ClientList
过程也是很直接,先将XML数据赋值给变量,然后将变量作为参数执行SP,这是查询你会发现数据已经在表中了。
现在我们要学习一下XML类型支持的方法:query(), value().
在这之前我们要知道一种表达式,就是XQuery,它是一种强大的脚本语言,用来获取XML的数据。SQLServer 支持这种语言的子集,所以我们能使用这种语言的表达式来检索和修改XML的数据。
注意:
因为XQuery是一种非常复杂的语言,我们只是涉及了一部分他的组件,如果想要更进一步的理解它如何应用,请查看MSDN XQuery language reference.
那我们现在先来通过例子来看一下query()和value 两个方法是如何使用XML数据的。需要注意的是我接下来的测试环境是SQLServer2008 R2。实例中包含了ClientDB 数据库、ClientInfoCollection 的XML数据以及ClientInfo 表。
USE master;
GO
IF DB_ID('ClientDB') IS NOT NULL
DROP DATABASE ClientDB;
GO
CREATE DATABASE ClientDB;
GO
USE ClientDB;
GO
IF OBJECT_ID('ClientInfoCollection') IS NOT NULL
DROP XML SCHEMA COLLECTION ClientInfoCollection;
GO
CREATE XML SCHEMA COLLECTION ClientInfoCollection AS
'xmlns="urn:ClientInfoNamespace"
targetNamespace="urn:ClientInfoNamespace"
elementFormDefault="qualified">
';
GO
IF OBJECT_ID('ClientInfo') IS NOT NULL
DROP TABLE ClientInfo;
GO
CREATE TABLE ClientInfo
(
ClientID INT PRIMARY KEY IDENTITY,
Info_untyped XML,
Info_typed XML(ClientInfoCollection)
);
INSERT INTO ClientInfo (Info_untyped, Info_typed)
VALUES
(
'<?xml version="1.0" encoding="UTF-8"?>
John
Doe
Jane
Doe
',
'<?xml version="1.0" encoding="UTF-8"?>
John
Doe
Jane
Doe
'
);
Listing 1: 创建测试环境和数据
The XML query() Method
query方法,通常被用来返回一个指定XML子集的无类型的XML实例,如下,用括号加单引号来实现表达式,语法:
db_object.query('xquery_exp')
当我们调用这个方法时,用真实数据库对象替换掉引号内的表达式。通过实例来比较一下结果有什么不一样。
SELECT Info_untyped.query('/People')
AS People_untyped
FROM ClientInfo;
Listing 2: 使用query() 来获得元素中的值
在这种情况下,将返回标签下所有的元素,包括子元素属性以及它们的值。
John
Doe
Jane
Doe
Listing 3: 结果集返回了/People 的内容
假如打算检索类型化的列中的 元素的内容,我需要修改XQuery的表达式。如Listing 4
SELECT Info_typed.query(
'declare namespace ns="urn:ClientInfoNamespace";
/ns:People') AS People_typed
FROM ClientInfo;
Listing 4: 使用query() 来检索类型化的XML列,然后你运行这个语句,就会得到结果如Listing5
John
Doe
Jane
Doe
Listing 5: 展示结果
如上,我们发现两种结果是很接近的,唯一的区别就是类型化的列里面包含了涉及的命名空间。
如果我们打算获得子下一级,子元素的内容,我们需要修改表达式,通过添加/Person 到路径名称中,如下:
SELECT
Info_untyped.query(
'/People/Person') AS People_untyped,
Info_typed.query(
'declare namespace ns="urn:ClientInfoNamespace";
/ns:People/ns:Person') AS People_typed
FROM ClientInfo;
Listing 6: 检索 元素
John
Doe
Jane
Doe
Listing 7: 这个结果集是非类型化数据的结果
John
Doe
Jane
Doe
Listing 8: 这个结果集是类型化数据的结果
如果我们打算去得到指定的下面的某一个元素,需要加入涉及的id属性。下面对比类型和非类型的两种情况下指定元素属性时如何获取。
SELECT
Info_untyped.query(
'/People/Person[@id=1234]') AS People_untyped,
Info_typed.query(
'declare namespace ns="urn:ClientInfoNamespace";
/ns:People/ns:Person[@id=5678]') AS People_typed
FROM ClientInfo;
Listing 9: 检索数据,指定元素
前面的没有变化,按照元素来添加表达式,然后用中括号,在中括号内添加了@id的值,结果如下
John
Doe
Listing 10: id为1234非类型化数据结果返回值。
对于类型化的列,我使用的id为5678.注意,这次不再需要在属性名称前加上命名空间的前缀了,只需要在元素名字前引用就足够了。
Jane
Doe
Listing 11: id为5678的数据结果
更进一步的展示结果,向下一级
SELECT
Info_untyped.query(
'/People/Person[@id=1234]/FirstName') AS People_untyped,
Info_typed.query(
'declare namespace ns="urn:ClientInfoNamespace";
/ns:People/ns:Person[@id=5678]/ns:FirstName') AS People_typed
FROM ClientInfo;
结果
John
Jane
Listing 14: 名字的结果的展示
当然还可以通过数字索引的方式展示:
SELECT
Info_untyped.query(
'/People/Person[1]/FirstName') AS People_untyped,
Info_typed.query(
'declare namespace ns="urn:ClientInfoNamespace";
/ns:People/ns:Person[2]/ns:FirstName') AS People_typed
FROM ClientInfo;
Listing 15: 使用数字索引来引用元素下的结果
XML的value()方法
就如同query()方法一样简便,很多时候当你想去检索一个特定的元素或属性的时候,而不是获取XML的元素,那就可以使用value()了。这种方法只会返回一个特定的值,不作为数据类型。因此一定要传递两个参数XQuery表达式和T-SQL数据类型。下面看语法:
db_object.value('xquery_exp', 'sql_type')
SELECT
Info_untyped.value(
'(/People/Person[1]/FirstName)[1]',
'varchar(20)') AS Name_untyped,
Info_typed.value(
'declare namespace ns="urn:ClientInfoNamespace";
(/ns:People/ns:Person[2]/ns:FirstName)[1]',
'varchar(20)') AS Name_typed
FROM ClientInfo;
Listing 16: 检索 的值
在Listing16中,我指定了[1]在Xquery表达式的后面,所以结果集将只返回第一个人的名字。
Name_untyped Name_typed
-------------------- --------------------
John Jane
Listing 17: 的两个结果
当然,我们也可以检索每个实例的id的属性值,并且指定Int类型返回。
SELECT
Info_untyped.value(
'(/People/Person/@id)[1]',
'int') AS Name_untyped,
Info_typed.value(
'declare namespace ns="urn:ClientInfoNamespace";
(/ns:People/ns:Person/@id)[2]',
'int') AS Name_typed
FROM ClientInfo;
Listing 19: 检索两个实例的id属性值
Name_untyped Name_typed
-------------------- --------------------
1234 5678
Listing 20: 返回两个id的属性
除了在表达式中定义你的XQuery表达式,你也能聚合的功能来进一步定义你的查询和操作数据。例如,count()功能,我们来获取每个列中 元素的个数。
SELECT
Info_untyped.value(
'count(/People/Person)',
'int') AS Number_untyped,
Info_typed.value(
'declare namespace ns="urn:ClientInfoNamespace";
count(/ns:People/ns:Person)',
'int') AS Number_typed
FROM ClientInfo;
Listing 21: 使用count功能来检索元素个数
结果如下:
Number_untyped Number_typed
-------------- ------------
2 2
Listing 22: 每列数据中 元素的数量
另外一个常用的功能是concat(), 它可以连接两个或多个XML元素下的数据。你可以指定你想连接的每一个部分。示例:
SELECT
Info_untyped.value(
'concat((/People/Person/FirstName)[2], " ",
(/People/Person/LastName)[2])',
'varchar(25)') AS FullName
FROM ClientInfo;
Listing 23: 使用concat()来连接数值
FullName
-------------------------
Jane Doe
Listing 24: 连接后的返回值
名和姓被连接起来,组成一个单一的值。都来自于同一个 下,当然也可以来自不同。
总结
我们基本上了解了XML在SQLServer 中的简单应用,从定义到使用方法。也看到了query()检索子集,也能使用value()检索独立的元素属性的值。当然除此之外还有向exist() andnodes() 这样方法,配合语法都以应用,这部分就不再展开讲了,大同小异。有不明白的可以私聊。更多使用方法还请访问MSDN来获取(搜索XQuery language reference)。
SQL Server对Xml字段的操作
T-Sql操作Xml数据
一、前言
SQL Server 2005 引入了一种称为 XML 的本机数据类型。用户可以创建这样的表,它在关系列之外还有一个或多个 XML 类型的列;此外,还允许带有变量和参数。为了更好地支持 XML 模型特征(例如文档顺序和递归结构),XML 值以内部格式存储为大型二进制对象 (BLOB)。
用户将一个XML数据存入数据库的时候,可以使用这个XML的字符串,SQL Server会自动的将这个字符串转化为XML类型,并存储到数据库中。
随着SQL Server 对XML字段的支持,相应的,T-SQL语句也提供了大量对XML操作的功能来配合SQL Server中XML字段的使用。本文主要说明如何使用SQL语句对XML进行操作。
二、定义XML字段
在进行数据库的设计中,我们可以在表设计器中,很方便的将一个字段定义为XML类型。需要注意的是,XML字段不能用来作为主键或者索引键。同样,我们也可以使用SQL语句来创建使用XML字段的数据表,下面的语句创建一个名为“docs”的表,该表带有整型主键“pk”和非类型化的 XML 列“xCol”:
CREATE TABLE docs (pk INT PRIMARY KEY, xCol XML not null)
XML类型除了在表中使用,还可以在存储过程、事务、函数等中出现。下面我们来完成我们对XML操作的第一步,使用SQL语句定义一个XML类型的数据,并为它赋值:
declare @xmlDoc xml;
set @xmlDoc='
David
21
'
三、查询操作
在定义了一个XML类型的数据之后,我们最常用的就是查询操作,下面我们来介绍如何使用SQL语句来进行查询操作的。
在T-Sql中,提供了两个对XML类型数据进行查询的函数,分别是query(xquery)和value(xquery, dataType),其中,query(xquery)得到的是带有标签的数据,而value(xquery, dataType)得到的则是标签的内容。接下类我们分别使用这两个函数来进行查询。
1、使用query(xquery) 查询
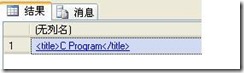
我们需要得到书的标题(title),使用query(xquery)来进行查询,查询语句为:
select @xmlDoc.query('/book/title')
运行结果如图:
2、使用value(xquery, dataType) 查询
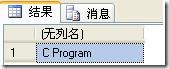
同样是得到书的标题,使用value函数,需要指明两个参数,一个为xquery, 另一个为得到数据的类型。看下面的查询语句:
select @xmlDoc.value('(/book/title)[1]', 'nvarchar(max)')
运行结果如图:
3、查询属性值
无论是使用query还是value,都可以很容易的得到一个节点的某个属性值,例如,我们很希望得到book节点的id,我们这里使用value方法进行查询,语句为:
select @xmlDoc.value('(/book/@id)[1]', 'nvarchar(max)')
运行结果如图:
4、使用xpath进行查询
xpath是.net平台下支持的,统一的Xml查询语句。使用XPath可以方便的得到想要的节点,而不用使用where语句。例如,我们在@xmlDoc中添加了另外一个节点,重新定义如下:
set @xmlDoc='
Jerry
50
Tom
49
'
--得到id为0002的book节点
select @xmlDoc.query('(/root/book[@id="0002"])')
上面的语句可以独立运行,它得到的是id为0002的节点。运行结果如下图:
![clip_image001[6]](https://img.111cn.net/uploads/20221114/img_637260e84632333.jpg)
四、修改操作
SQL的修改操作包括更新和删除。SQL提供了modify()方法,实现对Xml的修改操作。modify方法的参数为XML修改语言。XML修改语言类似于SQL 的Insert、Delete、UpDate,但并不一样。
1、修改节点值
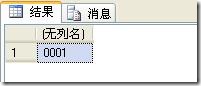
我们希望将id为0001的书的价钱(price)修改为100, 我们就可以使用modify方法。代码如下:
set @xmlDoc.modify('replace value of (/root/book[@id=0001]/price/text())[1] with "100"')
--得到id为0001的book节点
select @xmlDoc.query('(/root/book[@id="0001"])')
注意:modify方法必须出现在set的后面。运行结果如图:

2、删除节点
接下来我们来删除id为0002的节点,代码如下:
--删除节点id为0002的book节点
set @xmlDoc.modify('delete /root/book[@id=0002]')
select @xmlDoc
运行结果如图:

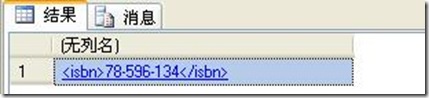
3、添加节点
很多时候,我们还需要向xml里面添加节点,这个时候我们一样需要使用modify方法。下面我们就向id为0001的book节点中添加一个ISBN节点,代码如下:
--添加节点
set @xmlDoc.modify('insert 78-596-134 before (/root/book[@id=0001]/price)[1]')
select @xmlDoc.query('(/root/book[@id="0001"]/isbn)')
运行结果如图:
4、添加和删除属性
当你学会对节点的操作以后,你会发现,很多时候,我们需要对节点进行操作。这个时候我们依然使用modify方法,例如,向id为0001的book节点中添加一个date属性,用来存储出版时间。代码如下:
--添加属性
set @xmlDoc.modify('insert attribute date{"2008-11-27"} into (/root/book[@id=0001])[1]')
select @xmlDoc.query('(/root/book[@id="0001"])')
运行结果如图:

如果你想同时向一个节点添加多个属性,你可以使用一个属性的集合来实现,属性的集合可以写成:(attribute date{"2008-11-27"}, attribute year{"2008"}),你还可以添加更多。这里就不再举例了。
5、删除属性
删除一个属性,例如删除id为0001 的book节点的id属性,我们可以使用如下代码:
--删除属性
set @xmlDoc.modify('delete root/book[@id="0001"]/@id')
select @xmlDoc.query('(/root/book)[1]')
运行结果如图:

6、修改属性
修改属性值也是很常用的,例如把id为0001的book节点的id属性修改为0005,我们可以使用如下代码:
--修改属性
set @xmlDoc.modify('replace value of (root/book[@id="0001"]/@id)[1] with "0005"')
select @xmlDoc.query('(/root/book)[1]')
运行结果如图:

经过上面的学习,相信你已经可以很好的在SQL中使用Xml类型了,下面是我们没有提到的,你可以去其它地方查阅:exist()方法,用来判断指定的节点是否存在,返回值为true或false; nodes()方法,用来把一组由一个查询返回的节点转换成一个类似于结果集的表中的一组记录行。