百川智能推出Baichuan-Audio-Instruct音频指令模型
作者:袖梨
2026-06-02
百川智能推出Baichuan-Audio-Instruct音频指令模型。这款模型专注于理解并执行语音指令,官方已将其托管在Hugging Face平台开放下载。
面向开发者的音频指令工具
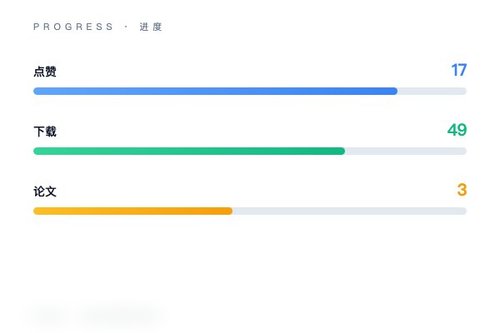
该模型在社区获得了17个点赞和49次下载。它的标签里包含“omni”“safetensors”等技术标识,还有三篇相关论文的编号作为技术支撑。模型采用Apache-2.0许可证,这意味着开发者可以比较自由地在项目里使用它——挺开放的吧?
为什么百川智能要专门做这样一个音频指令模型?答案其实很简单:语音交互正成为主流人机界面,但让机器准确理解语音里的“指令”仍然是个难题。这个模型的目的,就是帮开发者跳过基础训练阶段,直接获得一个能听懂“打开空调”“查询天气”这类具体指令的模型。
技术特点与应用场景
从公开信息看,Baichuan-Audio-Instruct具备多模态处理能力(“omni”标签暗示了这一点)。它不只识别语音内容,还能理解语音中的语调、停顿等细节。电商平台的语音客服、智能家居的语音控制、车载系统的免提操作——这些场景都算是它的用武之地。
开发者拿到模型后,可以用自己的数据进行微调。能直接拿来就用,确实方便了研发流程。没错,开源社区的快速迭代,靠的就是这种开放共享的模式。
百川智能这次发布的音频指令模型,真的能让咱们的智能设备理解得更精准一些吗?从技术公开的信息来看,它或许能解决目前语音助手“只听得见、听不懂”的尴尬问题。未来,手机上的语音助手、智能音箱的应答逻辑,都可能因为这个模型而变得更自然。音频交互的体验正在被一步步改善呢。